Tutoriel : ANOVA sur mesures répétées
L’ANOVA paramétrique à un facteur est une approche statistique qui permet de comparer plus de deux moyennes. Mais, pour être valide, cette méthode doit satisfaire trois critères :
- indépendance des résidus (ou des données)
- normalité des résidus (ou des données)
- homogénéité des résidus (ou des données).
Prérequis
Introduction
Contexte
Une situation très classique est celle de mesures répétées dans le temps. A titre d’exemple, imaginons que 15 garçons ont été mesurés à trois reprises entre 8 et 9 ans (par exemple à 8 ans, 8 ans + 3 mois, et 8 ans + 9 mois que l’on nomme Time1, Time2, Time3).
Les données pourraient être comme celles-ci : (
taille <- read.csv2(here::here("data", "Taille.csv"))
taille
## Sujet Time1 Time2 Time3
## 1 S_1 129.0 130.6 135.3
## 2 S_2 130.2 132.0 135.0
## 3 S_3 128.5 130.3 133.6
## 4 S_4 128.2 129.4 133.9
## 5 S_5 127.0 128.1 131.3
## 6 S_6 124.1 125.5 129.4 vous pouvez télécharger les données en cliquant le bouton ci-dessous.
Visualisation
Passage en format long

library(tidyverse)
tailleL <- taille %>%
pivot_longer(cols=c(Time1:Time3),
names_to="Time",
values_to="Taille") %>%
mutate(Sujet=fct_inorder(Sujet))# pour ordonner les sujets de 1 à 15
slice(tailleL,1:15) # afficher les 15 première lignes
## # A tibble: 15 x 3
## Sujet Time Taille
##
## 1 S_1 Time1 129
## 2 S_1 Time2 131.
## 3 S_1 Time3 135.
## 4 S_2 Time1 130.
## 5 S_2 Time2 132
## 6 S_2 Time3 135
## 7 S_3 Time1 128.
## 8 S_3 Time2 130.
## 9 S_3 Time3 134.
## 10 S_4 Time1 128.
## 11 S_4 Time2 129.
## 12 S_4 Time3 134.
## 13 S_5 Time1 127
## 14 S_5 Time2 128.
## 15 S_5 Time3 131. Plots
Pour visualiser les données, nous pouvons faire ce type de graphique :
ggplot(tailleL, aes(x=Time, y=Taille, colour=Sujet)) +
geom_point()+
geom_line(aes(group=Sujet))+
theme_classic() 
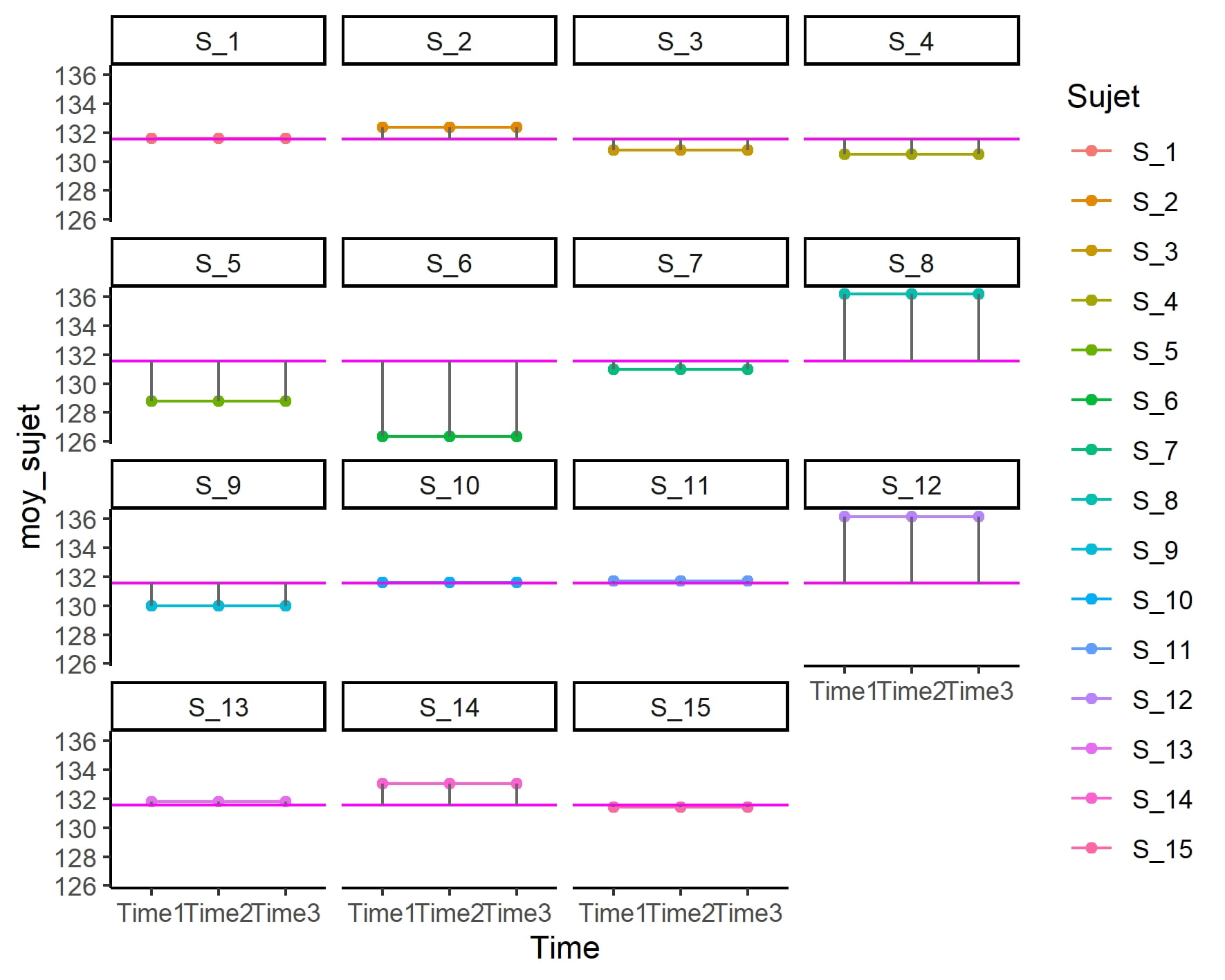
Nous pouvons également subdiviser le graphique par sujet. Il est très facile de le faire avec `ggplot2`, en employant la fonction `facet_wrap()`:
ggplot(tailleL, aes(x=Time, y=Taille, colour=Sujet)) +
geom_point()+
geom_line(aes(group=Sujet))+
facet_wrap(~Sujet)+
theme_classic() Remarque : dans le cas de mesures répétées l’utilisation des boxplots est moins intéressante car elle ne permet pas de montrer que les observations ont été faites sur les mêmes unités expérimentales.
Question posée
On souhaite évaluer si, globalement, les tailles moyennes des sujets, aux trois temps de mesure, sont identiques ou bien si elles sont différentes pour au moins deux temps.
Jargon
non-indépendantes peuvent être appelées :
- modèles hiérarchiques
- analyses longitudinales (lorsque les données sont répétées dans le temps)
- modèles mixtes (plus généraliste)
- d’une ou plusieurs variables à effet fixe (ici le temps)
- une ou plusieurs variables à effet aléatoire (ici le sujet).
auraient pu être mesurés à leur place. Si nous refaisions l’expérience, d’autres sujets seraient mesurés, alors que les temps de mesures seraient identiques !
Principe
Décomposition de la dispersion
- une dispersion factorielle (SCF, ici le temps)
- une dispersion résiduelle (SCR, ce qui ne peut pas être affecté au temps).
- une dispersion factorielle (SCF : le temps)
- une dispersion due au sujet (SCSujet)
- une dispersion résiduelle (SCR’: ce qui ne peut pas être affecté au temps).
Impact sur la variance résiduelle

Formules
- i l’indice du cluster sous jacent (ici le sujet), va de 1 à n_i,
- j l’indice des modalités du facteur étudié (ici le temps), va de 1 à k,
- k le nombre de conditions,
- y_ij la mesure du sujet i au temps j,
- y_i la moyenne des mesures du sujet i,
- y_j la moyenne des mesures au temps j
- y_barre : la moyenne générale (grand mean)
Somme des carrés totaux (SCT)
\[\text{SCT} = \sum_{i=1}^{n_i}\sum_{j=1}^{k} (y_{ij } – \overline{y})^2\]
La SCT peut être représentée comme ceci :
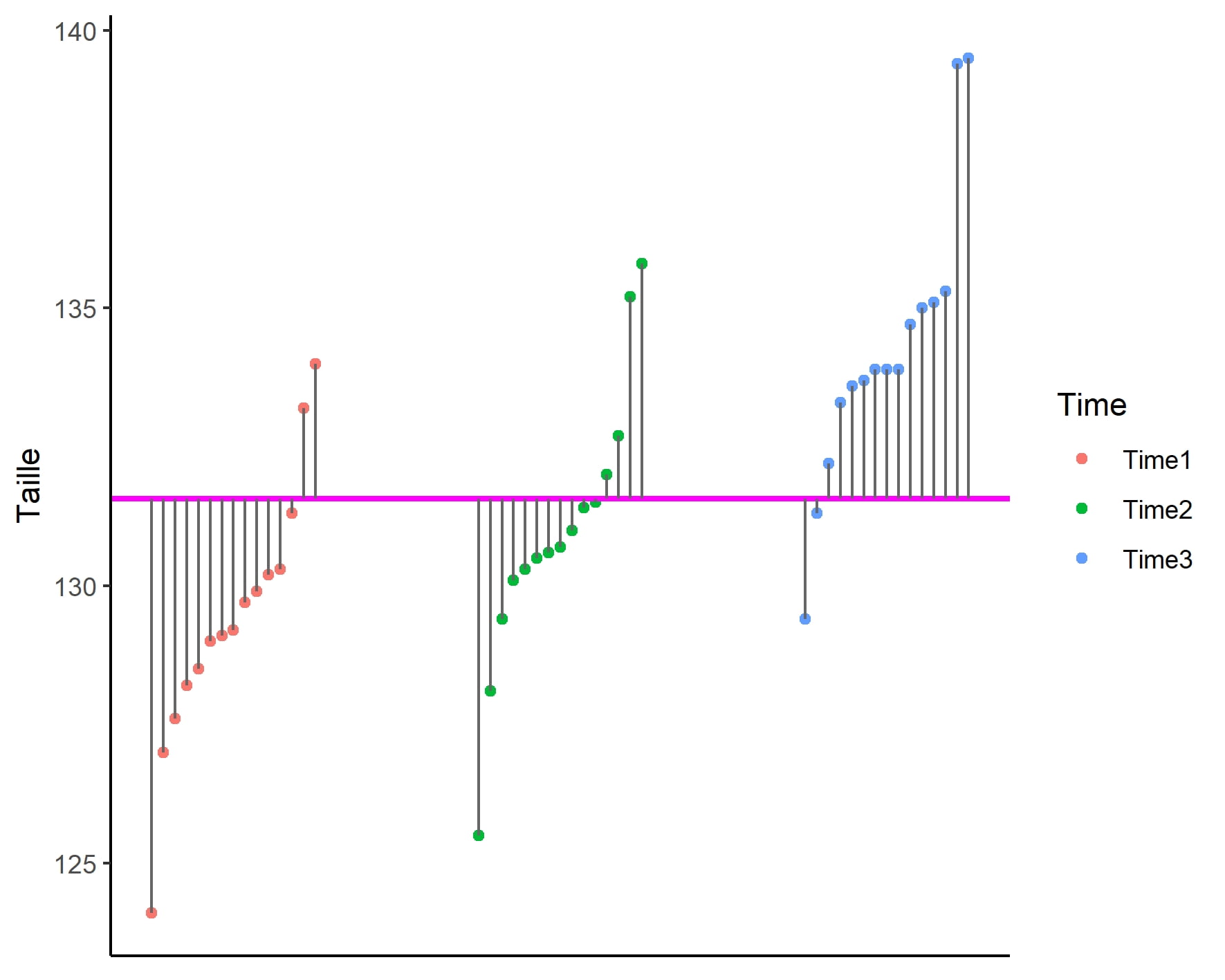
La SCT peut se calculer manuellement comme ceci:
mydfL <- tailleL
mydfL <- mydfL %>%
mutate(gm=mean(Taille))
SCT_val <- sum((mydfL$Taille-mydfL$gm)^2)
SCT_val
## [1] 448.3058 Somme des carrés factoriels (SCF)
\[SCF = \sum_{j=1}^{k} n_i \times({y_j} – \overline{y})^2 $\]
La SCF peut être représentée comme ceci :
mydfL <- mydfL %>%
group_by(Time) %>%
mutate(moy_Time=mean(Taille))
SCF_val <- sum((mydfL$moy_Time-mydfL$gm)^2)
SCF_val
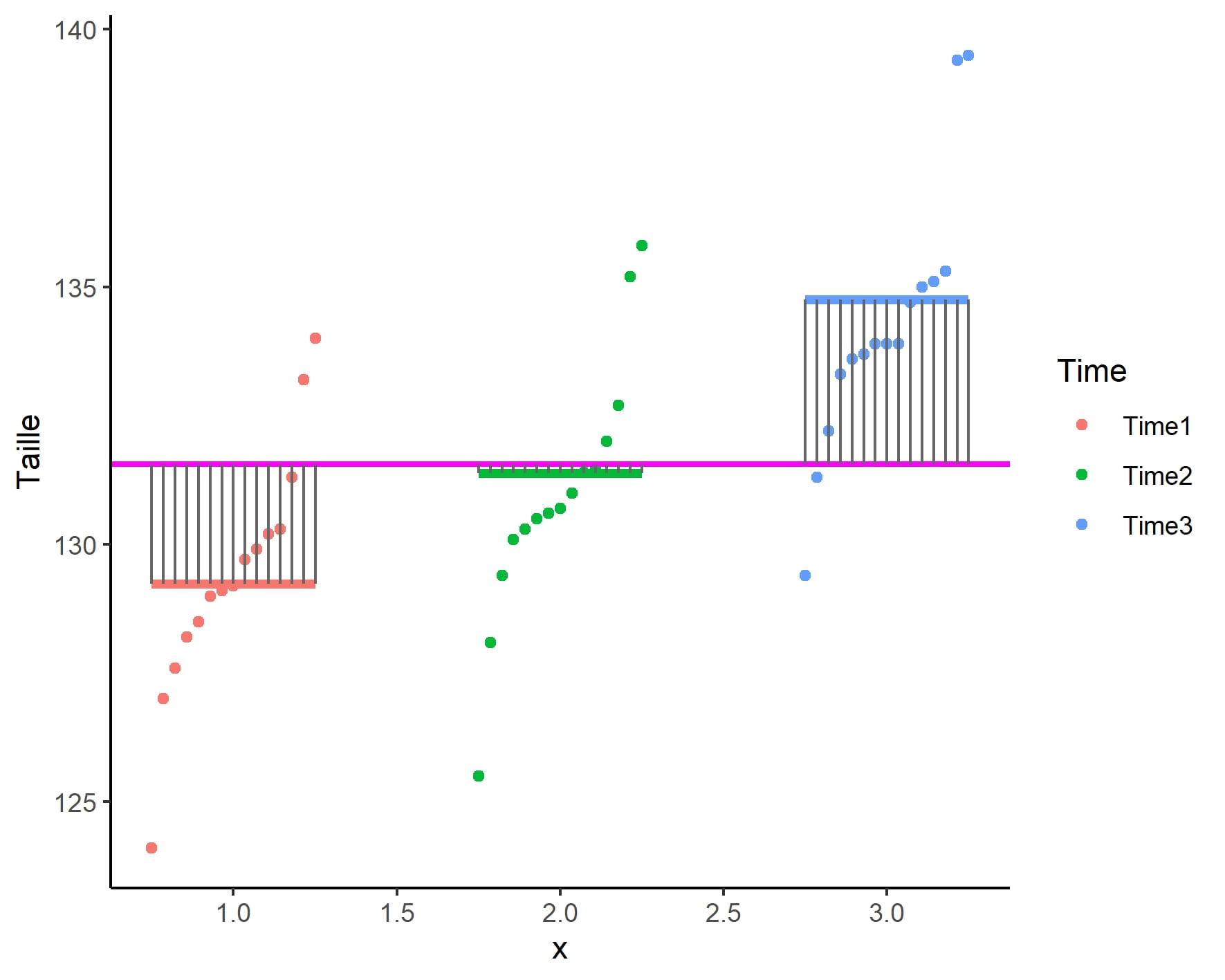
## [1] 184.6004 Somme des carrés sujets (SCSujet)
\[SCS_{ujet} = k\sum_{i=1}^{n_i}(y_i – \bar{y})^2$\]
Le calcul de cette somme des distances au carré peut être illustrée comme cela :
La somme des carrés sujets peut se calculer manuellement comme ceci :
mydfL <- mydfL %>%
group_by(Sujet) %>%
mutate(moy_sujet=mean(Taille))
SCSujet_val <- sum((mydfL$moy_sujet-mydfL$gm)^2)
SCSujet_val
## [1] 255.7324 SCR_prime_val=SCT_val-SCF_val-SCSujet_val
SCR_prime_val
## [1] 7.972889
Les carrés moyens
Le test
Conditions d'applications
- Normalité des résidus
- Homogénéité des variances et des co-variances (puisque les observations ne sont plus indépendantes, un terme de covariance doit à présent être considéré).
ANOVA sur mesures répétées avec R
L’ANOVA sur mesures répétées peut être réalisée sous R avec différents packages et fonctions. J’utilise généralement la fonction `aov` du package `stats` (chargé par défaut), la fonction `ezANOVA` du package `ez`, ou plus généralement la fonction `lmer()` du package `lme4` quipermet d’ajuster un modèle mixte.
La fonction ezANOVA et le test de Mauchly
La fonction `ezANOVA` du package `ez` est très pratique, car elle renvoit le test de Mauchly pour évaluer l’hypothèse de spéhricité, et propose les corrections à utiliser en cas de rejet :
library(ez)
## Warning: package 'ez' was built under R version 3.6.2
mod1 <- ezANOVA(dv=Taille,
within=Time,
wid=Sujet,
data=tailleL)
## Warning: Converting "Time" to factor for ANOVA.
mod1
## $ANOVA
## Effect DFn DFd F p p<.05 ges
## 2 Time 2 28 324.1493 4.347843e-20 * 0.4117735
##
## $`Mauchly's Test for Sphericity`
## Effect W p p<.05
## 2 Time 0.6994327 0.09791486
##
## $`Sphericity Corrections`
## Effect GGe p[GG] p[GG]<.05 HFe p[HF] p[HF]<.05
## 2 Time 0.7688952 6.239033e-16 * 0.8452296 2.636179e-17 * ezPlot(tailleL, dv=Taille, wid=Sujet, within=Time, x=.(Time))
## Warning: Converting "Time" to factor for ANOVA 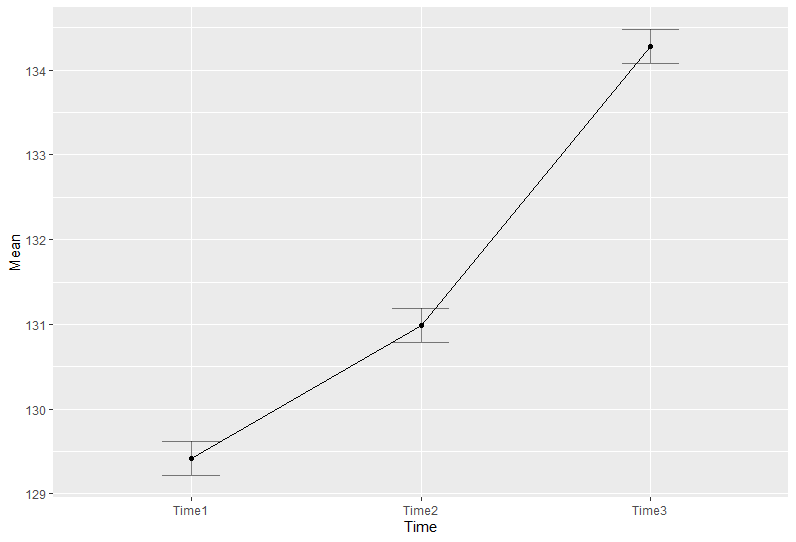
Obtenir la table de variance
mod1_aov <- aov(Taille~Time+Error(Sujet/Time), data=tailleL)
summary(mod1_aov)
##
## Error: Sujet ## Df Sum Sq Mean Sq F valuePr(>F)
## Residuals 14 255.7 18.27
##
## Error: Sujet:Time
## Df Sum Sq Mean Sq F value Pr(>F)
## Time 2 184.60 92.30 324.1 <2e-16 ***
## Residuals 28 7.97 0.28
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 - SCSujet = 255.7324
- SCF = 184.6
- SCR’=7.97
La fonction lmer et l'évaluation de l'hypothèse de normalité
library(lme4)
mod_rep <- lmer(Taille~Time+(1|Sujet), data=tailleL)
summary(mod_rep)
## Linear mixed model fit by REML ['lmerMod']
## Formula: Taille ~ Time + (1 | Sujet)
## Data: tailleL
##
## REML criterion at convergence: 132.8
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.58707 -0.63583 -0.04471 0.52597 1.78030
##
## Random effects:
## Groups Name Variance Std.Dev.
## Sujet (Intercept) 5.9940 2.4483
## Residual 0.2847 0.5336
## Number of obs: 45, groups: Sujet, 15
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 129.4200 0.6470 200.04
## TimeTime2 1.5667 0.1948 8.04
## TimeTime3 4.8600 0.1948 24.94
##
## Correlation of Fixed Effects:
## (Intr) TimTm2
## TimeTime2 -0.151
## TimeTime3 -0.151 0.500
## Warning: package 'lmerTest' was built under R version 3.6.2
mod_rep <- lmerTest::lmer(Taille~Time+(1|Sujet), data=tailleL)
summary(mod_rep)
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: Taille ~ Time + (1 | Sujet)
## Data: tailleL
##
## REML criterion at convergence: 132.8
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.58707 -0.63583 -0.04471 0.52597 1.78030
##
## Random effects:
## Groups Name Variance Std.Dev.
## Sujet (Intercept) 5.9940 2.4483
## Residual 0.2847 0.5336
## Number of obs: 45, groups: Sujet, 15
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 129.4200 0.6470 14.8793 200.04 < 2e-16 ***
## TimeTime2 1.5667 0.1948 28.0000 8.04 9.35e-09 ***
## TimeTime3 4.8600 0.1948 28.0000 24.94 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) TimTm2
## TimeTime2 -0.151
## TimeTime3 -0.151 0.500 Cette sortie permet d’obtenir les variances inter sujet et résiduelle (dans la partie Random effects). La variance résiduelle est égale à 0.2847. Vous pouvez retrouver cette valeur dans sortie de la fonction `summary(mod1_aov)` présentée précédemment, au niveau de la lignes Residuals et de la colonne Mean Sq.
library(car)
Anova(mod_rep)
## Analysis of Deviance Table (Type II Wald chisquare tests)
##
## Response: Taille
## Chisq Df Pr(>Chisq)
## Time 648.3 2 < 2.2e-16 ***
## ---
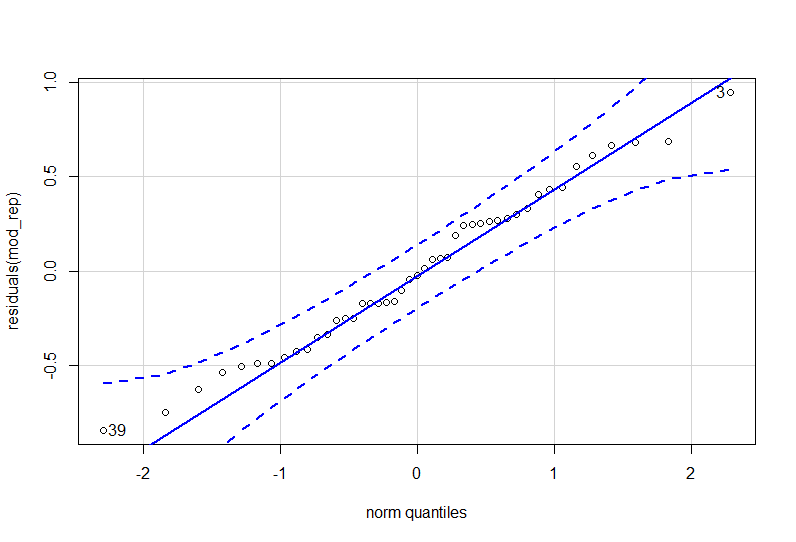
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 La normalité des résidus peut s’évaluer graphiquement par un qqPlot, et/ou par l’utilisation du test de Shapiro-Wilk:
library(car)
qqPlot(residuals(mod_rep))
## [1] 3 39
shapiro.test(residuals(mod_rep))
##
## Shapiro-Wilk normality test
##
## data: residuals(mod_rep)
## W = 0.98239, p-value = 0.717 Comparaisons multiples
Celles-ci peuvent être obtenues à l’aide du package `multcomp`.
Procédure de Tukey
La procédure de Tukey, consiste à réaliser toutes les comparaisons deux à deux :
library(multcomp)
mc_tukey <- glht(mod_rep,linfct=mcp(Time="Tukey") )
summary(mc_tukey)
##
## Simultaneous Tests for General Linear Hypotheses
##
## Multiple Comparisons of Means: Tukey Contrasts
##
##
## Fit: lmerTest::lmer(formula = Taille ~ Time + (1 | Sujet), data = tailleL)
##
## Linear Hypotheses:
## Estimate Std. Error z value Pr(>|z|)
## Time2 - Time1 == 0 1.5667 0.1948 8.04 <1e-10 ***
## Time3 - Time1 == 0 4.8600 0.1948 24.94 <1e-10 ***
## Time3 - Time2 == 0 3.2933 0.1948 16.90 <1e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method) Procédure de Dunnett
mc_dunnett <- glht(mod_rep,linfct=mcp(Time="Dunnett") )
summary(mc_dunnett )
##
## Simultaneous Tests for General Linear Hypotheses
##
## Multiple Comparisons of Means: Dunnett Contrasts
##
##
## Fit: lmerTest::lmer(formula = Taille ~ Time + (1 | Sujet), data = tailleL)
##
## Linear Hypotheses:
## Estimate Std. Error z value Pr(>|z|)
## Time2 - Time1 == 0 1.5667 0.1948 8.04 <1e-10 ***
## Time3 - Time1 == 0 4.8600 0.1948 24.94 <1e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method) Pour aller plus loin
- https://ademos.people.uic.edu/Chapter21.html#1210_afex_defaults
- http://www.pallier.org/easy-anova-with-r.html
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏



26 réponses
Bonjour,
Merci pour cet article (encore) très clair.
2 remarques:
1. Pour éviter de faire tourner “aov” pour obtenir la table de variance, il suffit d’ajouter return_aov=TRUE lorsqu’on effectue le calcul avec ezanova:
mod1 <- ezANOVA(dv=Taille,
within=Time,
wid=Sujet,
data=tailleL,
return_aov=TRUE)
il est alors possible de taper:
summary(mod1$aov)
2. Êtes-vous sûre que le test de Tukey est adapté aux données dépendantes ? Celui-ci s'appuie sur la statistique d'écart studentisée et, de ce que j'en comprends, ne prend pas en compte le fait que les données sont acquises sur les mêmes sujets dans chaque condition de temps.
Bonjour Gaël,
Merci pour l’astuce return.aov=TRUE !
Concernant le point 2, je dirais qu’il s’agit d’une procédure de Tukey plutôt qu’un test de Tukey. Procédure de Tukey voulant dire que toutes les comparaisons deux à deux sont réalisées.
Je suis assez persuadée que la fonction glht() prend en compte le caractère répété des données car les résultats obtenus avec une anova pour données indépendantes ne sont pas identiques (le pvalues sont plus élevée) car les erreurs standard sont alors plus élevées et donc les statistiques des tests plus faibles.
> tailleL$Time <- as.factor(tailleL$Time) > library(lmerTest)
> mod_rep <- lmer(Taille~Time (1|Sujet), data=tailleL) > #summary(mod_rep)
> library(multcomp)
> mc_tukey <- glht(mod_rep,linfct=mcp(Time="Tukey") ) > summary(mc_tukey)
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: lmer(formula = Taille ~ Time (1 | Sujet), data = tailleL)
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
Time2 – Time1 == 0 1.5667 0.1948 8.04 <1e-10 ***
Time3 - Time1 == 0 4.8600 0.1948 24.94 <1e-10 ***
Time3 - Time2 == 0 3.2933 0.1948 16.90 <1e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Adjusted p values reported -- single-step method)
> mod_ind <- lm(Taille~Time, data=tailleL) > #summary(mod_ind)
> mc_tukey_ind <- glht(mod_ind,linfct=mcp(Time="Tukey") ) > summary(mc_tukey_ind)
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: lm(formula = Taille ~ Time, data = tailleL)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
Time2 – Time1 == 0 1.567 0.915 1.712 0.21271
Time3 – Time1 == 0 4.860 0.915 5.312 < 0.001 *** Time3 - Time2 == 0 3.293 0.915 3.599 0.00231 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Adjusted p values reported -- single-step method)Bonne continuation
La nouvelle fonction pivot_longer du package “dplyr” ne marche pas avec ma version R 3.6.1
Quelles sont les procédures à suivre afin que cette fonction puisse s’exécutée?
Bonjour,
je suis très étonnée, car je suis encore en version 3.6.1 et cela fonctionne.
Avez vous essayé les exemples de la page d’aide de la fonction pivot_longer ?
Bonne continuation.
Merci, cet article m’a permis d’apprendre encore plus. Il est très bien rédigé également
Bonjour,
J’ai réalisé une ANOVA, deux facteurs (Groupes-Temps) à mesures répétées.
Mon facteur groupe est divisé en deux modalités : Controle / MVC
Mon facteur Temps est divisé en quatre modalités : Pre T1 T2 T3
J’observe une différence significative pour le facteur groupe, et le l’interaction groupe/temps.
Je souhaites poursuivre mon analyse avec le test de DUNNETT, si j’applique votre code le test comparera la moyenne globale des deux modalités mélangées (MVC-CON) de mon facteur “groupe”, pour chaque modalités de T1 T2 T3. Est ce bien cela ?
Maintenant si je souhaites comparer les moyennes séparément de mes deux modalités (CON et MVC) au cours du temps (cad MVC-Pre avec MVC-T1, MVC-Pre avec MVC-T2, MVC-Pre avec MVC-T3 puis CON-Pre avec CON-T1, CON-Pre avec CON-T2, CON-Pre avec CON-T3), comment puis je le faire ?
Je débute en stat et sur R, j’espère avoir été clair…
Merci pour votre travail !
Bonjour,
je crois comprendre que vous faite une ANOVA avec une variable intra et une variable inter. Voici quelques ressources qui vous seront sans doute utiles : https://www.psychologie.uni-heidelberg.de/ae/meth/team/mertens/blog/anova_in_r_made_easy.nb.html et https://ademos.people.uic.edu/Chapter21.html
Bonne continuation
merci de ce post très agréable et utile.
Pouvez-vous commenter en pour/contre l’anova sur mesures répétées vs les modèles mixtes?
Il me semble que considérer la variable temps comme factorielle (cas de l’anova mais pas des modèles mixtes) peut être limitant et devrait faire préférer les modèles mixtes.
Bonjour Nicolas,
vous avez raison l’ANOVA sur mesure répétées permet d”expliquer une réponse numérique continue en fonction d’une variable catégorielle. Si cette variable explicative est du temps, il faut donc la considérer en catégorie. En revanche, le modèle mixte est plus général, et peut être l’équivalent d’une régression linéaire (mise en relation d’une variable réponse continue et d’une variable explicative numérique continue aussi) avec mesure répétées. Si le temps est la variable prédictive, il n’est plus nécessaire de la catégoriser. Les modèles mixtes sous l’angle de la régression feront sans doute l’objet d’un prochain article.
Bonne continuation
Merci beaucoup Claire pour ce formidable tutoriel!
Merci Ovide !
Bonjour,
Je vais sans doute bientôt passer de SAS à R.
Bon outil pour gagner beaucoup de temps.
Je vais largement partager avec mes collègues.
Bonjour Pascal,
et si vous avez besoin d’un accompagnement plus important pour faciliter ce passage de SAS à R, je peux vous proposer une formation intra-entreprise sur mesure. N’hésitez pas à prendre contact avec moi via le formulaire de contact.
Bonne continuation.
Bonjour,
Merci pour ce article. Il est beaucoup formateur
Bonjour,
Merci beaucoup pour ce tutoriel. J’ai utilisé la fonction lmerTest::lmer, mais j’ai de la difficulté à interpréter les résultats:
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.53418 0.09442 8.74820 5.658 0.000345 ***
condition1 0.37883 0.12876 42.25009 2.942 0.005271 **
condition2 -0.04740 0.12876 42.25009 -0.368 0.714589
pairing1 -0.16053 0.09113 44.45734 -1.762 0.085026 .
condition1:pairing1 0.01961 0.12876 42.25009 0.152 0.879680
condition2:pairing1 0.02261 0.12876 42.25009 0.176 0.861437
Qu’est-ce que signifie le fait que seul intercept et condition1 soit significatif?
Merci
Bonjour,
la significativité de l’intercept n’a pas d’intérêt.
Puisque les intercations sont NS, alors on peut regarder les effets propres des variables. Condition1 est significative, cela signifie que la moyenne associée à condition1 est significativement plus grande que celle associée à la condition de référence.
Bonne continuation
Merci pour votre réponse!
Encore une petite chose m’embête: qu’est-ce que R considère comme condition 1 et condition de référence? Mes conditions sont nommés S,B et T, et ils n’aparraissent jamais comme tel dans mes résultats. Mes données sont pourtant organisées de la même façon que les vôtres…
Bonjour Claire,
Article très intéressant et surtout bien expliqué merci beaucoup. Concernant ces données répétées peut-on appliquer la même démarche dans le cas où nous n’avons pas le même nombre d’observations aux différents temps.
Merci
Bonjour,
je n’ai pas essayé mais je pense que soit R va renvoyer une erreur, soit il va supprimer les lignes qui ont une donnée manquante.
Bonne continuation.
Bonjour,
Si nous utilisons un modele lineaire mixte “lmer” à 2 facteurs, faut il parametrer le modele avec les contrastes (contrasts=list(x1=contr.sum, x2=contr.sum)) et ensuite faire une Anova du modele de type III ?
Merci
Bonjour Aurélien,
oui c’est ça.
Bonne continuation.
Bonjour,
Merci beaucoup pour votre blog où j’ai trouvé de nombreuses aides pour R et la compréhension des tests statistiques !!
J’aurai une petite question : la fonction lmer permet d’effectuer des statistiques via des modèles linéaires mixtes dont l’Anova à mesures répétées fait parti. Ainsi, les pré-requis de l’Anova à mesures répétées (normalité des résidus et hypothèses de sphéricité) sont-ils à valider pour les modèles mixtes que je calcule via la fonction lmer ?
Si oui, comment puis-je faire le test de Mauchly après lmer sans effectuer une anova à mesures répétées via ezANOVA ?
Bonjour,
d’après ma compréhension, on peut utiliser un lmer pour faire une anova à mesure répétées, mais dans ce cas là, il n’existe pas (en tout cas à ma connaissance ) de test pour valider l’hypothèse de spéhricité.
Donc il vaut mieux utiliser ezANOVA.
Bonne continuation
Bonjour,
J’aurai deux questions au sujet de la prise en compte des données manquantes avec la fonction lmer :
– Comment puis-je savoir s’il prend en compte les données manquantes comme une valeur 0 ou si le logiciel ne les prend pas en compte ? –> comment traite-t-il les NA ?
– Comment puis-je utiliser la fonction lmer sans prendre en compte les données manquantes, bien écrites NA dans mon jeu de données ?
Merci par avance !!
Bonjour,
Il n’y a aucune raison pour que R substitue une NA par 0, il ne le fait pas !
Je pense que par défaut les données manquantes sont omises. Pour le voir, regardez la sortie de la fonction summary(), le nombre d’observations analysées est indiqué.
Par exemple :
library(lme4)
data(Orthodont,package=”nlme”)
Orthodont$nsex <- as.numeric(Orthodont$Sex==”Male”)
Orthodont$nsexage <- with(Orthodont, nsex*age)
mod1 <- lmer(distance ~ age (age|Subject) (0 nsex|Subject)
(0 nsexage|Subject), data=Orthodont)
summary(mod1)
Vous pouvez aussi supprimer les NA en faisant mydata2 <- na.omit(mydata), mais attention, toutes les lignes qui comporte une NA (au niveau d’une variable quelconque) seront supprimées.
Bonne continuation.
Bonjour et merci infiniment pour cet article très claire! Je me demandais juste s’il serait possible d’utiliser ce test dans le cas où nous avons des données agrégées et pas individuelles ? Ex: des données de prévalence agrégées par catégories d’âges (de 5ans) selon plusieurs pays au cours du temps ? Merci d’avance et très belle soirée à vous !