La régression logistique par l'exemple
Prérequis
Dans cet article, nous allons voir comment réaliser, en pratique, une régression logistique avec le logiciel R. Pour tirer pleinement profit de cet article, je vous recommande de lire l’article d’introduction à la régression logistique.
Les données pour la régression logistique
Pour illustrer la réalisation d’une régression logistique, nous allons utiliser le jeu de données `heart_disease` du package `funModeling`. Ce dataset contient les données de 303 patients inclus dans un essai clinique dans le domaine de la cardiologie. Treize variables sont mesurées, comme l‘âge, le sexe, le niveau de douleur de la poitrine, la concentration de cholestérol dans le sang, etc…. La présence, ou l’absence d’une pathologie cardiaque est renseignée dans la variable `has_heart_disease` (no pour l’absence de pathologie, yes pour la présence).
Vous trouverez plus d’informations sur ces données sur le site de l’UCI.
Pour charger ces données dans R, nous utilisons les commandes suivantes :
library(funModeling)
head(heart_disease) ## age gender chest_pain resting_blood_pressure serum_cholestoral
## 1 63 male 1 145 233
## 2 67 male 4 160 286
## 3 67 male 4 120 229
## 4 37 male 3 130 250
## 5 41 female 2 130 204
## 6 56 male 2 120 236
## fasting_blood_sugar resting_electro max_heart_rate exer_angina oldpeak slope
## 1 1 2 150 0 2.3 3
## 2 0 2 108 1 1.5 2
## 3 0 2 129 1 2.6 2
## 4 0 0 187 0 3.5 3
## 5 0 2 172 0 1.4 1
## 6 0 0 178 0 0.8 1
## num_vessels_flour thal heart_disease_severity exter_angina has_heart_disease
## 1 0 6 0 0 no
## 2 3 3 2 1 yes
## 3 2 7 1 1 yes
## 4 0 3 0 0 no
## 5 0 3 0 0 no
## 6 0 3 0 0 no Dans cet exemple, nous allons chercher à évaluer si deux variables (la fréquence cardiaque maximale `max_heart_rate` et le sexe `gender`) sont significativement liées à la présence d’une pathologie cardiaque, et si c’est le cas, à caractériser ces relations.
Visualisations
Préambule à la régression logistique
Avant de commencer la régression logistique, nous chargeons le super package `tidyverse` qui sera largement utilisé pour manipuler les données, par l’intermédiaire du package `dyplyr` et du pipe`%>%`.
Pour plus d’information sur la manipulation de données, vous pouvez consulter cet article :
conflict_prefer() du package conflicted :library(conflicted)
conflict_prefer("filter", "dplyr")
conflict_prefer("select", "dplyr") has_heart_disease_num afin de recoder les modalités de la variable has_heart_disease : “no” en 0 et “yes” en 1, grâce à la fonction mutate().Nous en profitons aussi pour renommer heart_disease en HD (plus court) :HD <- heart_disease %>%
mutate(has_heart_disease_num = ifelse(has_heart_disease == "no",0, 1)) %>%
mutate(has_heart_disease_num =as.numeric(has_heart_disease_num )) Plots
ggplot(HD , aes(x= max_heart_rate , y=has_heart_disease_num)) +
geom_point() 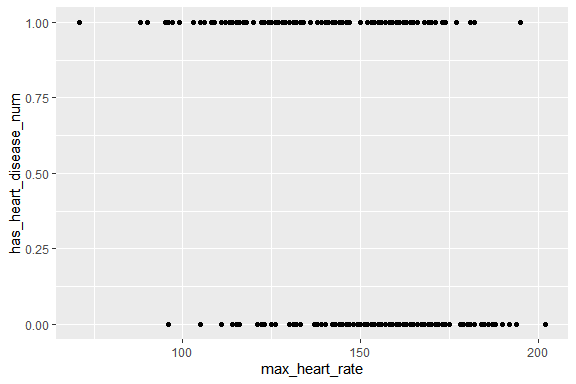
Il semble exister un lien : les sujets ayant une fréquence cardiaque maximale élevée apparaissant moins souvent atteints de pathologie cardiaque.
Intéressons-nous, à présent, à la relation entre la pathologie cardiaque et le sexe :
ggplot(HD , aes(gender, fill=has_heart_disease)) +
geom_bar(position="fill", col="black") +
scale_fill_manual(values=c("#43d8c9","#95389e")) 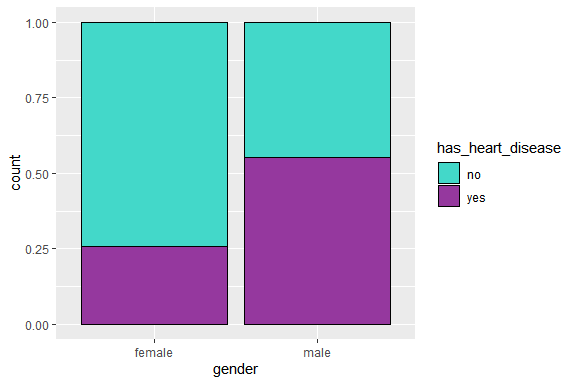
Réalisation de la régression logistique
Ajustement du modèle de régression logistique
glm(), et l’argument family=binomial:mod1 <- glm(has_heart_disease ~ max_heart_rate + gender, family = binomial, data = HD)
summary(mod1) ##
## Call:
## glm(formula = has_heart_disease ~ max_heart_rate + gender, family = binomial,
## data = HD)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.1779 -0.8724 -0.4687 0.9334 2.1654
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 5.601857 1.012870 5.531 3.19e-08 ***
## max_heart_rate -0.045089 0.006757 -6.673 2.50e-11 ***
## gendermale 1.406210 0.300763 4.675 2.93e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 417.98 on 302 degrees of freedom
## Residual deviance: 336.67 on 300 degrees of freedom
## AIC: 342.67
##
## Number of Fisher Scoring iterations: 4 Avant de pouvoir interpréter les résultats, il est nécessaire de vérifier que les conditions d’applications sont satisfaites.
Vérification des conditions d'application de la régression logistique
Nombre de cas suffisants
Pour réaliser une régression logistique, il est nécessaire d’avoir un nombre suffisant de données. En pratique, il est recommandé d’avoir au moins 10 fois plus d’événements que de paramètres dans le modèle.
En appliquant la fonction summary()nous voyons trois lignes, il y a donc 3 paramètres. Notre jeu de données doit donc contenir 3*10 malades.
C’est bien le cas ici, puisque nous avons 139 malades :
table(HD$has_heart_disease)
##
## no yes
## 164 139 Absence de surdispersion
Dans le cas des GLM, la variance résiduelle est estimée à partir d’une loi théorique, ici la loi binomiale (c’est la structure d’erreur du GLM).
Si la dispersion réelle des données est supérieure à celle prévue par la théorie, alors on parle de surdispersion.
En cas de surdispersion, l’erreur standard des paramètres est sous-estimée. Ceci peut conduire à des p-values (pour chacun des coefficients) excessivement faibles, et donc aboutir à des conclusions erronées.
La surdispersion est généralement évaluée par le ratio de la déviance résiduelle sur le nombre de degrés de libertés du modèle :
Si ce ratio est supérieur à 1, alors il y a surdispersion. Cette supériorité à 1 est un peu subjective, dans le sens où il n’existe pas de seuil (1.5, 2 ?) à partir duquel on considère qu’il y a surdispersion.
En cas de surdispersion, il est nécessaire d’utiliser une autre structure d’erreur, telle que la structure “quasi Binomiale“.Celle-ci va conduire à une augmentation de l’erreur standard des paramètres du modèle, par un facteur :summary()En cas de surdispersion, voici un exemple d’utilisation de la loi quasi binomial :mod1_qb <- glm(has_heart_disease~max_heart_rate+gender, family = quasibinomial, data = HD)
summary(mod1_qb) ##
## Call:
## glm(formula = has_heart_disease ~ max_heart_rate + gender, family = quasibinomial,
## data = HD)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.1779 -0.8724 -0.4687 0.9334 2.1654
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.601857 1.013476 5.527 7.07e-08 ***
## max_heart_rate -0.045089 0.006761 -6.669 1.24e-10 ***
## gendermale 1.406210 0.300943 4.673 4.50e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasibinomial family taken to be 1.001198)
##
## Null deviance: 417.98 on 302 degrees of freedom
## Residual deviance: 336.67 on 300 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 4 Interprétation des résultats de la régression logistique
summary(mod1)
##
## Call:
## glm(formula = has_heart_disease ~ max_heart_rate + gender, family = binomial,
## data = HD)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.1779 -0.8724 -0.4687 0.9334 2.1654
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 5.601857 1.012870 5.531 3.19e-08 ***
## max_heart_rate -0.045089 0.006757 -6.673 2.50e-11 ***
## gendermale 1.406210 0.300763 4.675 2.93e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 417.98 on 302 degrees of freedom
## Residual deviance: 336.67 on 300 degrees of freedom
## AIC: 342.67
##
## Number of Fisher Scoring iterations: 4 Comme pour la régression linéaire simple, la ligne correspondant à l’intercept a peu d’intérêt. En revanche, les lignes suivantes sont intéressantes.
Sur la ligne correspondant à la variable `max_heart_rate`, nous pouvons voir que le log OR = – 0.045, soit un OR = exp(-0.045)= 0.95. Cela signifie que plus la fréquence cardiaque maximale est élevée plus le risque d’être malade diminue (car le signe du coefficient est négatif, et que par conséquent l’OR<1).
Nous pouvons également voir que la pvalue associée est <0.05. Nous pouvons donc dire qu’il existe une association significative entre la fréquence cardiaque maximale et un risque de pathologie cardiaque, au risque (alpha) de 5%. Au final, on peut dire “si la fréquence cardiaque maximale augmente, alors le risque de la maladie cardiaque diminue“, ou encore “le risque de maladie cardiaque est significativement moins fort si la fréquence cardiaque est plus élevée“. Une fréquence cardiaque maximale élevée est ainsi un facteur protecteur du risque de maladie cardiaque.
Concernant la ligne relative à la variable `gender`, nous pouvons voir que l’intitulé est `gendermale`. Les résultats fournis concernent alors les hommes relativement aux femmes qui servent de référence, car `female` est devant `male` selon l’ordre alphabétique.
Les résultats nous montrent une association positive (log OR >0) et significative (p-value <0.05) entre le sexe masculin et le risque de maladie cardiaque. Nous pouvons aller plus loin en calculant l’OR:
OR_gender <-exp(coef(mod1)[3])
OR_gender
## gendermale
## 4.080461 Si la maladie cardiaque est peu fréquente dans la population étudiée (<10%), nous pouvons interpréter l’OR comme un risque relatif et dire que le risque de maladie cardiaque est 4 fois plus important chez les hommes que chez les femmes. Sinon, l’odds ratio traduit la réduction relative des odds (ce qui n’est pas très intuitif). On dira alors que la maladie est plus fortement associée chez les hommes que chez les femmes, mais sans quantifier cette relation.
Nous pouvons obtenir les effets propre des deux variables, à l’aide de la fonctionAnova du package car :library(car)
Anova(mod1)
## Analysis of Deviance Table (Type II tests)
##
## Response: has_heart_disease
## LR Chisq Df Pr(>Chisq)
## max_heart_rate 57.260 1 3.819e-14 ***
## gender 24.229 1 8.554e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Anova(mod1, test="F") Mise en forme et visualisation des résultats
Les résultats peuvent facilement être mis en forme à l’aide du package finalfit:
library(finalfit)
dependent = "has_heart_disease"
explanatory = c("gender","max_heart_rate")
res_glm_multi <- HD%>%
glmmulti(dependent, explanatory) %>%
fit2df(estimate_suffix="(multivarié)")
res_glm_multi
kable(res_glm_multi,row.names=FALSE, align=c("l", "l", "r", "r", "r", "r")) 
or_plot() du package finalfit:HD %>%
or_plot(dependent, explanatory,table_text_size = 4,
title_text_size = 16) 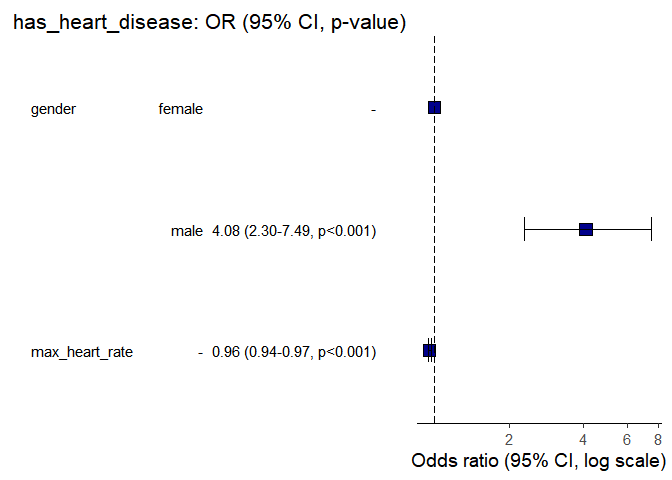
Conclusion
J’espère que cet article vous permettra d’appréhender plus facilement la régression logistique sous R, ainsi que l’interprétation des résultats.Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 

Images par PublicDomainPictures de Pixabay


15 réponses
Super, j’aimerais vraiment avoir plus d’articles pour apprendre le logiciel R. Svp avez vous des documents pour moi qui vont me permettre d’approfondir mes connaissances sur R
Merci pour cet article comme toujours très intéressant & pratique.
Petit problème technique dans le chapitre 3.2.2, les exemples ne s’affichent pas.
Wahooo tres bon. Merci bcp 🙏
Formidable article.
Merci infiniment Claire.
Bonjour, merci pour ce tutoriel
J’ai une petite question: Je recoit cette erreur, je ne sais pas son origine, veuillez m’aclaircir ce point , merci
> conflict_prefer(“filter”, “dplyr”)
[conflicted] Removing existing preference
[conflicted] Will prefer dplyr::filter over any other package
Ce n’est pas un message d’erreur, juste un message d’information.
Bonjour chère Claire,
Merci pour cet article. Comme pour tous vos articles, il est magnifique. Que du bonheur! La régression logistique est très utilisée en épidémiologie et là, pour la significativité d’association entre la variable réponse (souvent une maladie ou un décès) et les prédicteurs (facteurs de risque) , nous préférons souvent l’intervalle de confiance de l’OR au p (p-value). Pareil pour le risque relatif (RR).
Bonsoir Claire,
Merci pour la qualité de l’article. J’ai beaucoup apprécié les conditions de validité du modèle. Comme les autres articles, tu présentes les notions simplement et cela donne envie d’apprendre. Continue à m’envoyer les articles.
je voudrais avoir des notions suffisantes sur le logiciel R
Bonjour,
avez vous consulter la page débutants ? : https://statistique-et-logiciel-r.com/debutants-commencez-ici/
Bonne continuation
Super merci…
Comment tracer la courbe ROC du modèle logit estimé ? Merci
Bonjour Rachid;
ça fera peut être l’objet d’un prochain article…
Bonne continuation
Bonjour,
Est il possible, avec la commande or_plot, de faire apparaitre les résultats des odd ratios en univarié (et non en multivarié comme réalisé par défaut)?
Merci
Bonjour Theo,
A priori non. Je n’ai pas trouvé d’argument susceptible de répondre à ce besoin dans la page d’aide de la fonction or_plot().
Bonne continuation.
Bonjour,
Tout d’abord un grand merci pour votre site et votre pédagogie hors norme pour rendre les statistiques accessibles au plus grand nombre ! 🙂
J’effectue une régression logistique et la condition d’application d’absence de surdispersion n’est pas vérifiée. J’utilise donc la structure “quasibinomiale” comme conseillé … Vous dites que cela engendre une diminution de la statistique des tests et donc une augmentation de la p-value. Moi c’est le contraire qui est observé et cela pour deux analyses distinctes … Cela traduit un souci ?
Je vous remercie d’avance pour votre réponse et vous remercie à nouveau pour vos articles !
Jeanne