Quel que soit le domaine dans lequel on travaille, il peut être intéressant de savoir construire des groupes d’observations qui se ressemblent. On appelle cela des clusters.
Il existe deux méthodes classiques pour réaliser des clusters :
Dans cet article, nous allons nous intéresser à la méthode des kmeans. C’est une approche que j’aime beaucoup parce que je trouve le principe vraiment astucieux !
La méthode des kmeans permet de regrouper les objets (ou sujets, ou sites, ou point, etc…) en K clusters distincts. Ce nombre K doit être spécifié, mais il existe des approches pour déterminer son nombre optimal.
La méthode des kmeans repose sur la minimisation de la somme des distances euclidiennes au carré entre chaque objet (ou sujet, ou point) et le centroïde (le point central) de son cluster.
La méthode des kmeans est une approche de clustering non-hiérarchique (à l’intérieur d’un cluster les objets ne sont pas ordonnés en fonction de leurs ressemblance).
La méthode des kmeans appartient aux algorithmes de classification non supérvisée, de machine learning. Les termes « non supervisée » signifie que les groupes n’existent pas avant d’être créés ; il ne s’agit d’apprendre à partir des données comment construire des clusters existants. Il s’agit seulement de regrouper les données.
Dans la méthode des kmeans, les objets (ou sujets, ou sites, ou points, etc.) appartiennent à un seul cluster, et les clusters ne se chevauchent pas
La distance euclidienne est à la base de la méthode des kmeans, puisqu’il s’agit d’attribuer un cluster à chaque point, de façon à ce que la somme des distances euclidiennes au carré entre chaque point et le centroide de son cluster, soit la plus faible possible. On parle de minimisation de la variation intra-cluster (within-cluster variation en anglais).
La distance euclidienne est simplement une généralisation du théorème de Pythagore qui dit que » le carré de la longueur de l’hypoténuse, qui est le côté opposé à l’angle droit, est égal à la somme des carrés des longueurs des deux autres côtés. »
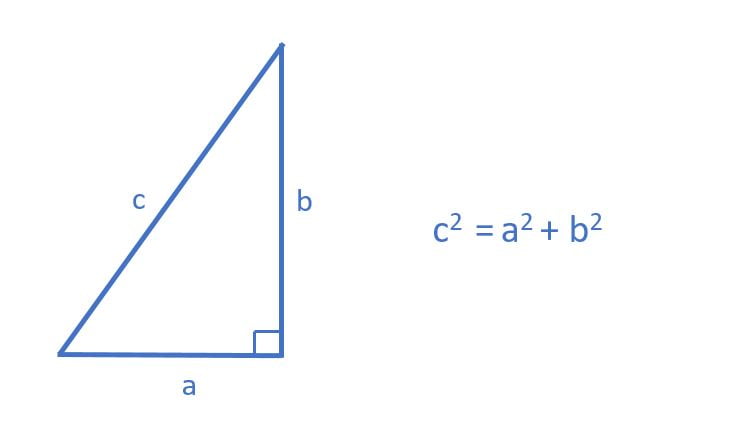
Ainsi, dans un espace à deux dimensions la distance euclidienne entre deux points peut être estimée par hypoténuse d’un triangle rectangle.
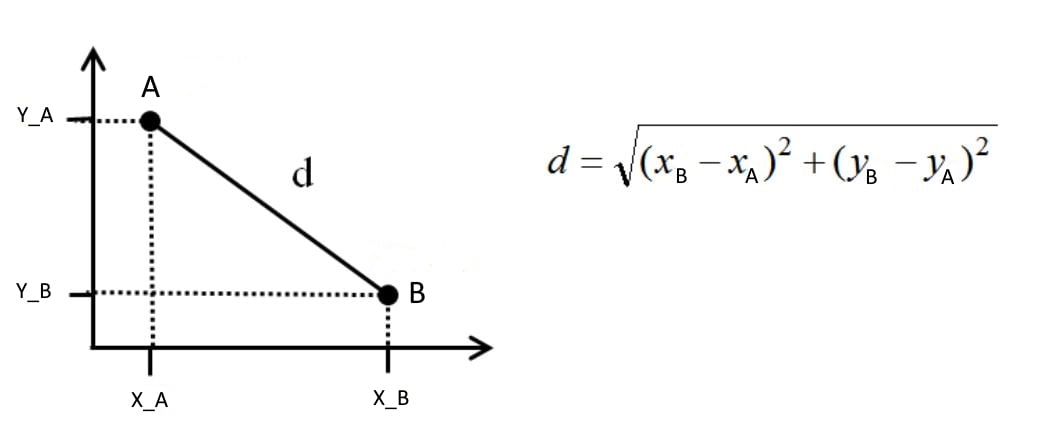
Dans un espace à n dimensions (u, v, …z), la distance euclidienne entre les points, ou deux observations A(u_A, v_A,…,z_A)$ et $B(u_B, v_B,…,z_B) , est définie par :
\[d(A,B) = \sqrt{(u_A – u_B)^2 + (v_A – v_B)^2 +…(z_A – z_B)^2 }\]
Ainsi, deux observations identiques ont une distance nulle.
Remarque : si deux variables ne sont pas dans la même échelle, l’une pourrait avoir plus de poids dans le calcul de la distance euclidienne que l’autre. C’est pour cette raison qu’il est préférable de centrer réduire les données. En effet, le « centrage-réduction » permet d’obtenir des données indépendantes de leur unité.
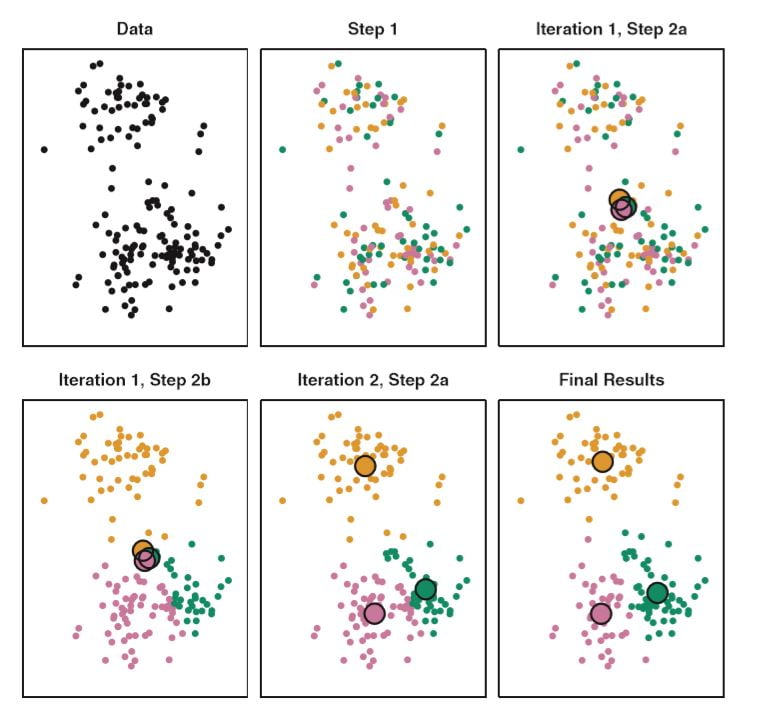
L’algorithme du kmeans est un algorithme itératif qui minimise la somme des distances entre chaque individu et le centroïde du cluster ; c’est la variabilité intra cluster.
Le principe est :
Voici un exemple de construction de 3 clusters avec 2 variables (2 dimensions) pour bien comprendre.
Ci-dessous, des graphiques montrant l’évolution de la somme de la variabilité intra-cluster, en fonction de l’évolution des clusters:

Vous trouverez plus d’informations sur ce calcul dans le livre An introduction to statistical learning, de James, G., Witten, D., Hastie, T., & Tibshirani, (2013).
Le résultat final, c’est-à-dire l’appartenance de chaque objet (ou sujet ou point) à un cluster donné peut dépendre de l’attribution initiale aléatoire des clusters qui a lieu dans la première étape de l’algorithme.
Pour contourner cette difficulté, il est nécessaire de lancer plusieurs fois l’algorithme et de regarder si la composition des clusters est modifiée ou non.
La fonction `kmeans()` réalise automatiquement ces multiples attributions aléatoires, et conservent uniquement les meilleurs résultats.
Nous allons utiliser des données mtcars, présentes dans le package dataset, chargé par défaut dans R.
str(mtcars)
## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ... Plus précisément, nous allons conserver les données réellement numériques continues :
library(tidyverse)
# selection des variables
mtcars_num <- mtcars %>%
dplyr::select(mpg,disp:qsec)
str(mtcars_num)
## 'data.frame': 32 obs. of 6 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ... Comme expliqué précédemment, avant d’employer l’approche des kmeans, il est nécessaire de standardiser (centrage réduction) les données. Pour cela, nous pouvons employer la fonction scale():
mtcars_num_sc <- scale(mtcars_num)
str(mtcars_num_sc)
## num [1:32, 1:6] 0.151 0.151 0.45 0.217 -0.231 ...
## - attr(*, "dimnames")=List of 2
## ..$ : chr [1:32] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" ...
## ..$ : chr [1:6] "mpg" "disp" "hp" "drat" ...
## - attr(*, "scaled:center")= Named num [1:6] 20.09 230.72 146.69 3.6 3.22 ...
## ..- attr(*, "names")= chr [1:6] "mpg" "disp" "hp" "drat" ...
## - attr(*, "scaled:scale")= Named num [1:6] 6.027 123.939 68.563 0.535 0.978 ...
## ..- attr(*, "names")= chr [1:6] "mpg" "disp" "hp" "drat" ... Les deux principaux arguments de la fonction kmeans() sont :
km.out = kmeans(mtcars_num_sc,centers=4,nstart =20) Pour obtenir à quel cluster appartient chaque point, nous pouvons employer :
km.out$cluster
# Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
## 4 4 4 4
## Hornet Sportabout Valiant Duster 360 Merc 240D
## 2 4 1 4
## Merc 230 Merc 280 Merc 280C Merc 450SE
## 4 4 4 2
## Merc 450SL Merc 450SLC Cadillac Fleetwood Lincoln Continental
## 2 2 2 2
## Chrysler Imperial Fiat 128 Honda Civic Toyota Corolla
## 2 3 3 3
## Toyota Corona Dodge Challenger AMC Javelin Camaro Z28
## 4 2 2 1
## Pontiac Firebird Fiat X1-9 Porsche 914-2 Lotus Europa
## 2 3 3 3
## Ford Pantera L Ferrari Dino Maserati Bora Volvo 142E
## 1 1 1 4 Et pour obtenir la valeur de la variabilité intra-cluster :
km.out$tot.withins
## [1] 50.94273 Trois méthodes sont généralement employées :
Elles sont décrites ici.
library(factoextra)
library(NbClust)
# Elbow method
fviz_nbclust(mtcars_num_sc, kmeans, method = "wss") +
geom_vline(xintercept = 4, linetype = 2)+
labs(subtitle = "Elbow method") 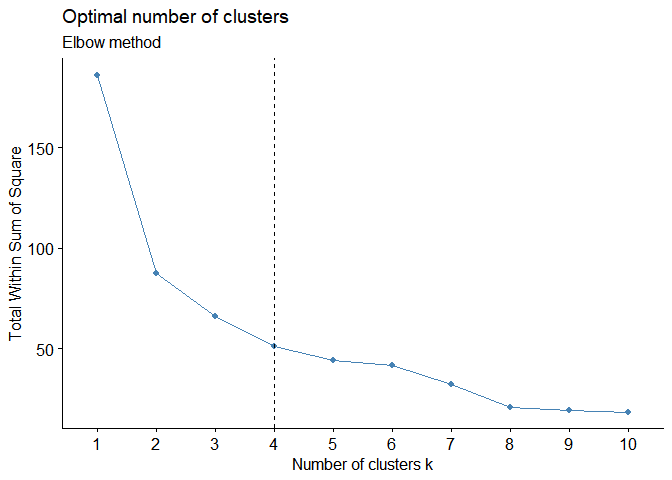
# Silhouette method
fviz_nbclust(mtcars_num_sc, kmeans, method = "silhouette")+
labs(subtitle = "Silhouette method") 
# Gap statistic
# nboot = 50 to keep the function speedy.
# recommended value: nboot= 500 for your analysis.
# Use verbose = FALSE to hide computing progression.
set.seed(123)
fviz_nbclust(mtcars_num_sc, kmeans, nstart = 25, method = "gap_stat", nboot = 50)+
labs(subtitle = "Gap statistic method") 
Ces trois méthodes ne conduisent pas forcément au même résultat. Ici, pour deux d’entre elles, le nombre optimal de clusters est 2.
Nous pouvons visualiser la relation entre les clusters et chacune des variables utilisées pour les construire avec la méthode des kmeans.
Par exemple, si nous conservons 2 clusters :
km.out2=kmeans(mtcars_num_sc,centers=2,nstart =20)
pairs(mtcars_num_sc, col=c(1:2)[km.out2$cluster]) 
fviz_cluster(). Le plan est celui d’une ACP qui est réalisée en amont de la représentation.library(factoextra)
fviz_cluster(km.out2, mtcars_num_sc, ellipse.type = "norm") 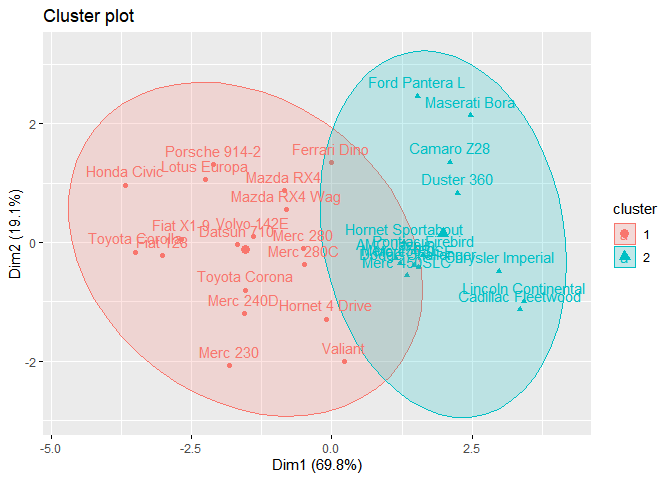


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
15 réponses
Bonjour Madame,
je suis intéressée par tout ce que vous faites pour élaircir les méthodes statistiques en appliquant R.
Comment interpréter le graphe (en sorte de matrice: les points rouge et points noir) dans le paragraphe visualisation?
Mes sincères salutations
Bonjour,
les points noirs correspondent à un premier cluster et les points rouges à l’autre cluster.
Bonne continuation
C’est trés intéressant , merci beaucoup pour vos efforts
Bonjour à vous
merci pour cette présentation
Bonjour Claire
L’illustration montre des clusters qui se chevauchent alors que le contexte indique que les clusters ne se chevauchent pas?
Bonjour,
Ce sont les ellipses qui se chevauchent, pas les clusters en eux-même.
Personnellement, quand je fais des clusters (hiérarchique ou K means), mes données de végétation sont d’abord transformées, par une double transformation : d’abord transformer les données d’abondance ( ,r, 1,2,3,4,5 selon la méthode phytosociologique) en tableau disjonctif et puis par une analyse non-symétrique des correspondances (souvent associée à une analyse factorielle multiple). Les coordonnées des variables sur les premiers axes de l’analyse sont utilisées pour calculer les distances euclidiennes. Le nombre utile d’axes est fixé par permutations.
Guy Bouxin
Bonjour Guy,
je ne connais pas la méthode de transformation phyotosociologique ! Quand je travaillais sur les abondances, j’avais l’habitude de faire une transformation de Hellinger puis une ACP. Est ce que vous auriez un publication d’introduction à me recommander ?
Super bien cet article, très très utile. Merci Claire
Bonjour,
merci de votre blog très pédagogique.
Concernant l’attribution à chaque observation du cluster qui lui est le plus proche, est-il possible de récupérer l’équation finale permettant de la calculer?
i.e. les coordonnées du centroïde?
Mon idée est dans l’hypothèse d’une nouvelle donnée, d’être capable d’estimer à quel cluster elle se rattache sans avoir à recalculer les kmeans.
Amicalement
Nicolas
Bonsoir Nicolas,
je pense que vous pouvez avoir accès aux coordonnées des centroides, avec les commandes suivantes :
km.out=kmeans(mtcars_num_sc,centers=4,nstart =20)
km.out$centers
Bonne continuation.
j’aime beaucoup votre blog, très pédagogue sans superflu. Je vais continuer à vous suivre! Merci claire de ce partage !
Merci Tao ! Je suis ravie si le blog vous aide, c’est le but !
Bonne continuation.
Bonjour ,
Merci de votre bloc très pédagogique, j’ai un sujet qui est : Quels sont les besoins en professionnels (kinésithérapeute, ergothérapeute et orthoprothésiste…) de la réadaptation pour les pays à bas et moyen niveaux de revenus ?
Proposition et application d’une méthode de calcul
j’ai pensé à votre méthode de calcul qui est la méthode K means. qu’est vous en pensez et comment je pourrai là mettre avec le logiciel R)?
Merci pour la clarté de vos explications