Importer automatiquement les feuilles d'un fichier Excel dans R
J’ai déjà écrit plusieurs articles sur l’importation de données dans R, notamment à partir de fichiers csv , ou encore de fichiers txt.
Ou encore pour importer de façon automatique plusieurs fichiers csv qui sont préalablement placés dans un même dossier.
Mais comment faire, lorsque les données que l’on souhaite importer sont dans des feuilles séparées d’un fichier Excel ?
On peut évidemment passer chaque feuille en csv, les placer dans un dossier et toutes les importer de façon automatisée. Mais ce n’est pas très optimal, surtout quand on a plusieurs dizaine de feuilles.
Dans cet article, je vais donc vous montrer comment importer très simplement toutes les feuilles d’un fichier Excel. Et si ces feuilles ont le même format, vous aurez aussi sans doute besoin de les assembler dans un seul et même tableau de données. Je vais également vous montrer comment le faire.
Les data
Pour illustrer cet article, je vais utiliser les données des chiffres départementaux mensuels relatifs aux crimes et délits enregistrés par les services de police et de gendarmerie depuis janvier 1996. disponibles sur data.gouv.fr:
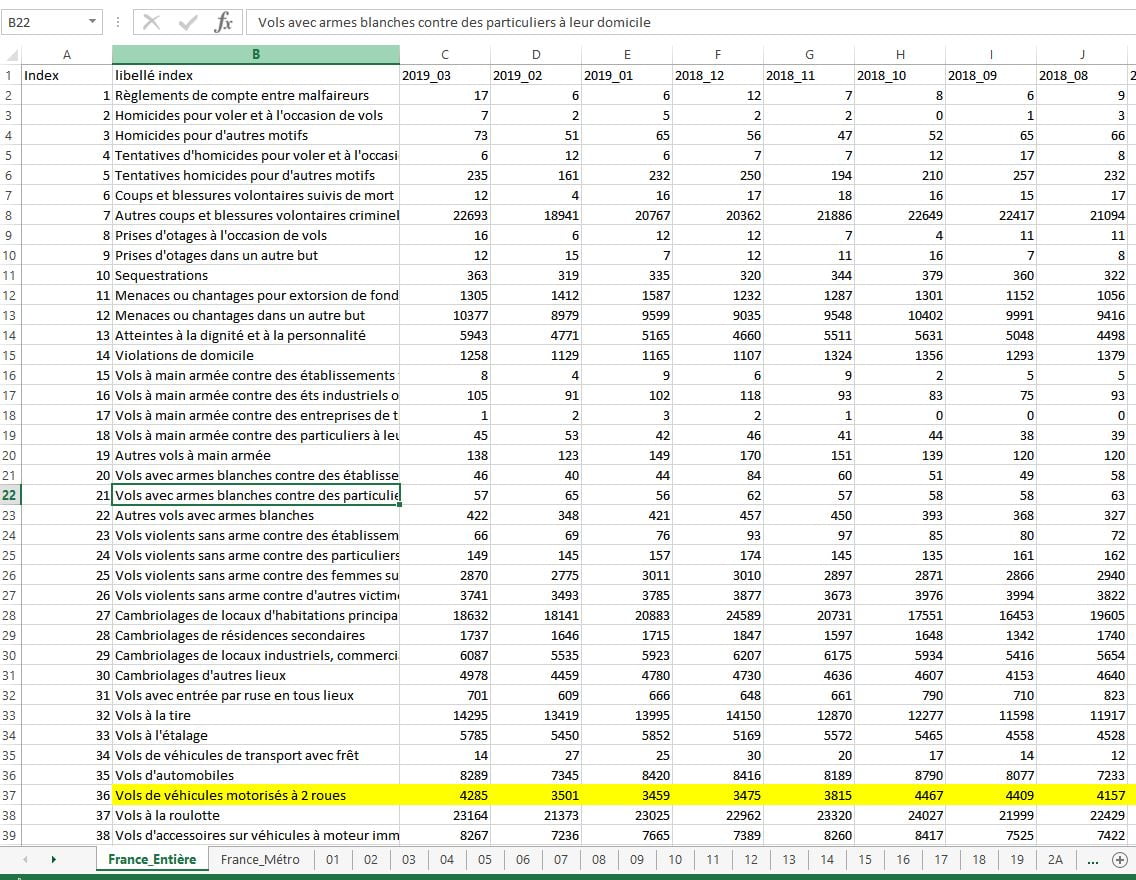
Le fichier Excel importé, nommé « tableaux-4001-ts (1) » contient les chiffres d’une centaine de délits recensés entre janvier 2000 et janvier 2019. La première feuille contient les données pour l’ensemble de la France, la seconde feuille contient les données de la France métropolitaine, et les feuilles suivantes contiennent les données pour chaque département, individuellement :
Organisation du travail
Je vous conseille d’organiser votre travail sous la forme d’un Rproject, avec un dossier « data » dans lequel vous placez le fichier Excel que vous souhaitez importer :

Pour plus d’informations sur les scripts en rmarkdown, consultez l’article Guide de démarrage en R markdown.
Importation des feuilles Excel
Pour réaliser cette importation, nous allons utiliser le package readxl:
library(readxl) A ma connaissance ce package n’a pas de cheatsheet mais il existe une page d’aide détaillée ici.
Nous allons également nous servir de la fonction here() du package here pour créer le chemin du fichier de données « tableaux-4001-ts (1) » qui se trouve dans le dossier « data » du R project. Ce chemin sera passé en argument de la fonction d’importation.
Importation feuille par feuille Excel
Récupération du nombre de feuilles Excel
Pour cela, on utilise la fonction excel_sheets() :
library(here)
sheet_names <- excel_sheets(here::here("data","tableaux-4001-ts (1).xlsx"))
## affichage du nom des feuillles
sheet_names
## [1] "France_Entière" "France_Métro" "01" "02"
## [5] "03" "04" "05" "06"
## [9] "07" "08" "09" "10"
## [13] "11" "12" "13" "14"
## [17] "15" "16" "17" "18"
## [21] "19" "2A" "2B" "21"
## [25] "22" "23" "24" "25"
## [29] "26" "27" "28" "29"
## [33] "30" "31" "32" "33"
## [37] "34" "35" "36" "37"
## [41] "38" "39" "40" "41"
## [45] "42" "43" "44" "45"
## [49] "46" "47" "48" "49"
## [53] "50" "51" "52" "53"
## [57] "54" "55" "56" "57"
## [61] "58" "59" "60" "61"
## [65] "62" "63" "64" "65"
## [69] "66" "67" "68" "69"
## [73] "70" "71" "72" "73"
## [77] "74" "75" "76" "77"
## [81] "78" "79" "80" "81"
## [85] "82" "83" "84" "85"
## [89] "86" "87" "88" "89"
## [93] "90" "91" "92" "93"
## [97] "94" "95" "971" "972"
## [101] "973" "974" "975" "976"
## [105] "977" "978" "986" "987"
## [109] "988"
## recuperation du nombre de feuilles
nb_sheets <- length(sheet_names)
nb_sheets
## [1] 109 Il y a donc 109 feuilles
Remarque : dans la syntaxe précédente, `here::` correspond au package `here`, et le second here correspond à la fonction. Cette syntaxe permet donc de dire à R « prends la fonction `here()` du package `here` ». Cette précision du package permet de ne pas avoir de conflit avec d’autres packages qui contiendraient également une fonction `here()`. Pour bien comprendre la création du chemin, vous pouvez utiliser la commande suivante :
here::here("data","tableaux-4001-ts (1).xlsx")
## [1] "C:/Users/clair/Documents/@Blog_Stat_et_LogicielR/@POSTS/65_Import_Excel/data/tableaux-4001-ts (1).xlsx" Vous trouverez plus d’informations sur l’utilisation de cette fonction ici :
Création des data frames
Pour cela, on utilise une boucle for avec un indice allant de i=1 à i=109 (le nombre de feuilles). A chaque tour de la boucle, c’est à dire pour chaque feuille :
- On stocke le nom de la feuille Excel dans la variable name.
- On crée une nouvelle variable name (name2) en ajoutant « sheet_ » devant le nom de la feuille (name). Cette étape est nécessaire pour stocker les données dans un objet, car R ne peut pas créer d’objet nommé uniquement avec des chiffres.
- On lit et stocke les données de la feuille i, en utilisant la fonction
read_excelet son argumentsheet.
4.On ajoute une colonne « sheet » dans laquelle on écrit le nom de la feuille (utile si on veut assembler plusieurs data frames par la suite).
5. On assigne les données au nouveau nom de la feuille (name2), c’est ce qui permet de créer le data frame avec le nom souhaité.
for (i in 1:nb_sheets){
name <- sheet_names[i] # récupère le nom de la feuille
name2 <- paste0("sheet_",name) #nouvelle variable name
data <- read_excel(here::here("data","tableaux-4001-ts (1).xlsx"), sheet = i) # lecture et stockage
data$sheet <- name # ajout d'une variable avec le nom original de la feuille
assign(name2,data) # création du data frame avec le nom souhaité
rm(name, name2,data) # suppression des objet intermédiaires
} Si tout se passe bien, vous allez voir apparaître les data frames dans la fenêtre « Global Environment » :

Remarque 1 : si vos feuilles ne sont pas nommées avec des chiffres, il n’est pas nécessaire de renommer la feuille dans la boucle.
Remarque 2 : plutôt que d’utiliser les indices dans la boucle for, il est aussi possible d’employer directement le nom des feuilles, en spécifiantsheet=name dans la fonction read_excel():
for(name in sheet_names){
name2 <- paste0("sheet_",name) #modification du nom de la feuille
data<- read_excel(here::here("data","tableaux-4001-ts (1).xlsx"), sheet = name)
data$sheet <- name
assign(name2,data)
} Importation des feuilles et création d'un seul fichier global
Ici, dans notre exemple, les feuilles des départements 1 à 95, ainsi que les deux départements de la Corse (2A, 2B) ont le même nombre de colonnes. On peut donc avoir envie de créer un seul fichier contenant les données de tous ces départements.
Récupération des indices des feuilles souhaitées
Ici, je souhaite compiler les feuilles relatives aux différents départements sans les DOM et les TOM. Je peux voir qu’il s’agit des feuilles correspondant aux indices 3 à 98.
sheet_names
## [1] "France_Entière" "France_Métro" "01" "02"
## [5] "03" "04" "05" "06"
## [9] "07" "08" "09" "10"
## [13] "11" "12" "13" "14"
## [17] "15" "16" "17" "18"
## [21] "19" "2A" "2B" "21"
## [25] "22" "23" "24" "25"
## [29] "26" "27" "28" "29"
## [33] "30" "31" "32" "33"
## [37] "34" "35" "36" "37"
## [41] "38" "39" "40" "41"
## [45] "42" "43" "44" "45"
## [49] "46" "47" "48" "49"
## [53] "50" "51" "52" "53"
## [57] "54" "55" "56" "57"
## [61] "58" "59" "60" "61"
## [65] "62" "63" "64" "65"
## [69] "66" "67" "68" "69"
## [73] "70" "71" "72" "73"
## [77] "74" "75" "76" "77"
## [81] "78" "79" "80" "81"
## [85] "82" "83" "84" "85"
## [89] "86" "87" "88" "89"
## [93] "90" "91" "92" "93"
## [97] "94" "95" "971" "972"
## [101] "973" "974" "975" "976"
## [105] "977" "978" "986" "987"
## [109] "988" Je vérifie que j’ai bien sélectionné les bons indices :
sheet_names[3:98]
## [1] "01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12" "13" "14"
## [15] "15" "16" "17" "18" "19" "2A" "2B" "21" "22" "23" "24" "25" "26" "27"
## [29] "28" "29" "30" "31" "32" "33" "34" "35" "36" "37" "38" "39" "40" "41"
## [43] "42" "43" "44" "45" "46" "47" "48" "49" "50" "51" "52" "53" "54" "55"
## [57] "56" "57" "58" "59" "60" "61" "62" "63" "64" "65" "66" "67" "68" "69"
## [71] "70" "71" "72" "73" "74" "75" "76" "77" "78" "79" "80" "81" "82" "83"
## [85] "84" "85" "86" "87" "88" "89" "90" "91" "92" "93" "94" "95" Création du fichier assemblé
On charge le package dplyr pour pouvoir utiliser la fonction bind_rows() qui permet d’assembler les lignes de deux data frames :
library(dplyr) On commence par initialiser un data frame vide, que je nomme « delits_fr » :
delits_fr <- NULL On utilise ensuite une boucle for avec les indices des feuilles concernées, définis précédemment, c’est à dire de 3 à 98. A chaque tour :
- On récupère le nom de la feuille.
- On récupère et stocke les données relatives à la feuille considérée.
- On ajoute une variable contenant le code du département (le nom de la feuille).
- On colle les données aux données déjà assemblées contenues dans delits_fr (vide au premier tour) avec la fonction
bind_rows(). - On supprime les objet temporaires « name » et « data »
for (i in 3:98){
name <- sheet_names[i] #récupère le nom de la feuille
data <- read_excel(here::here("data","tableaux-4001-ts (1).xlsx"), sheet = i)# stock les données
data$code_dept=name # ajout d'une variable code_dpt
delits_fr<- bind_rows(delits_fr,data)
rm(name,data)
} Le fichier créé comporte 10272 lignes :
nrow(delits_fr)
## [1] 10272 Ce chiffre correspondent au 107 lignes de chaque feuilles * les 96 feuilles :
107*96
## [1] 10272 Export du fichier compilé
Si vous souhaitez exporter le fichier compilé créé, vous pouvez le faire avec la fonction write.csv2(), et en utilisant la fonction here(), comme ceci :
write.csv2(delits_fr, here::here("data","delits_fr.csv")) Le fichier est alors exporté dans le dossier « data » du R project.
Pour aller plus loin
Pour analyser ensuite les données, il peut être plus intéressant de les passer dans un format « long ». Pour plus de d’information, vous pouvez consulter mon article « Format wide et long : pourquoi, et comment ?«
Conclusion
J’espère que ce court article très pratico-pratique vous évitera quelques écueils dans l’importation des données contenues dans de multiples feuilles Excel, et qu’il vous permettra de gagner du temps dans vos analyses.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏
Crédits Photos : Esa Riutta.

Encore une fois merci !
bonsoir,
une variante sans utiliser de boucle for avec le package purrr:
resultat <- map_df(3:98,~read_excel("tableaux-4001-ts.xlsx",sheet =.x))
cordialement
Bonjour,
merci pour votre commentaire et le partage de la ligne de commande. Je connais mal ces fonctions map qui sont pourtant très pratiques. Je vais essayer de me pencher dessus dans les prochaines semaines.
Bonne journée.
Bonjour Claire,
Merci beaucoup pour cet article ! Vos posts sont une bonne source d’inspiration pour mon travail et projets personnels.
Continuez comme ça s’il vous plaît ! 🙂
Quelle clarté pédagogique!
Merci
Merci !
Bonjour,
Merci bien pour votre article,
S’il vous plais, comment on peut afficher le contenu de feuille sheet_names[1]?
sheet_names[1]$X affiche ‘error’
Merco bien