Nettoyer et valider les données avec R
Après l’importation des données, et avant leur analyse à proprement parlé,les nettoyer et les valider est indispensable ! Dans cet article, je vous propose de passer en revue, quelques étapes importantes de ce processus.
Rappels concernant l'importation des données
Lorsqu’on souhaite importer des données dans R, celles-ci peuvent être sous différents formats de fichiers, par exemple .txt, .csv, .xlsx, .tsv. Néanmoins, le format csv est largement répandu, car il permet de visualiser les données dans un tableur, sans pour autant dépendre d’un logiciel en particulier (Excel, google sheet, open office etc…).
Importer un fichier csv
En Europe, les données au format csv utilisent généralement:
- le point-virgule (semi colon) comme séparateur de colonnes,
- la virgule (comma) comme séparateur de décimales.
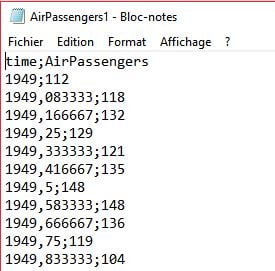
Mais il existe aussi des fichiers au format .csv qui utilisent :
- la virgule (comma) comme séparateur de colonnes,
- le point (dot) comme séparateur de décimales.

Pour importer correctement un fichier au format .csv dans R, il est nécessaire de connaître les caractères utilisés pour séparer les colonnes et pour séparer les décimales.
Si vous ne savez pas quels sont les caractères utilisés dans votre fichier à importer, ouvrez le fichier dans le bloc note : clique droit sur le fichier –> Ouvrir avec –> Bloc note.
Si votre fichier .csv est au format européen ( colonnes séparées par un point-virgule et une virgule pour séparer les décimales ), utilisez la fonction read.csv2() pour l’importer.
Par exemple, pour le jeu de données nommé AirPasengers1.csv, préalablement placé dans un dossier « data » du projet RStudio:
AP1 <- read.csv2("data/AirPassengers1.csv") Pour construire automatiquement le chemin d’accès, on peut utiliser la fonction here() du package here :
library(here)
AP1 <- read.csv2(here::here("data","AirPassengers1.csv")) Si votre fichier .csv utilise la virgule comme séparateur de colonnes et le point comme séparateur de décimales, utilisez la fonction read.csv() pour l’importer :
AP2 <- read.csv(here::here("data","AirPassengers2.csv")) Voici l’aide sur ces deux fonctions :


Importer un fichier txt
Les données à importer peuvent également être au format.txt. Dans ce cas, les colonnes sont généralement séparées par une tabulation :

Dans ce cas, en fonction du caractère employé pour séparer les décimales, vous pouvez employer les fonctions read.delim() and read.delim2() :

Par exemple :
rats <- read.delim2(here::here("data","rats.txt")) Importer d'autres formats de fichier
Selon le format de vos données, vous pouvez également utiliser les fonctions read_*() du package ‘readr’ :

Ces fonctions ont l’avantage d’être plus rapides que les fonctions présentées précédemment, qui appartient au package utils .
Et si vos données sont au format. xlsx, vous pouvez utiliser la fonction read.xlsx(“filename.xlsx”, sheet_numb) du package xlsx.
Vérifier l'importation et la structure de vos données
people <- read.csv2(here::here("data","people.csv")) Le code pour générer le jeu de données « people » est fourni à la fin de cet article.
Vérification de l'importation
Pour vérifier que l’importation des données s’est bien déroulée, j’utilise généralement les fonctions head() et tail() :
head(people,7)
## Name_FirstName Sex Age Height Hair Blue_Eye Brown_Eye Other_Eye
## 1 Smith_Emily F NA 1.68 Blond 1 0 0
## 2 Jonhson_Mikael M 253 1.93 Brown 0 1 0
## 3 Williams_Ashley F 38 1.55 Brown 0 1 0
## 4 Jones_Alex M 15 NA Other 0 0 1
## 5 Brown_Katie F 79 1.63 Blond 1 0 0
## 6 Davis_John M 56 1.70 Other 1 0 0
## 7 Miller_Megan F 63 1.50 0 1 0
tail(people,3)
## Name_FirstName Sex Age Height Hair Blue_Eye Brown_Eye Other_Eye
## 8 Wilson_Matthew M 19 1.87 Brown 0 0 1
## 9 Moore_Grace F 24 1.52 Blond 0 1 0
## 10 Taylor_Jack M -1 2.15 Brown 0 0 1 Contrôle de la structure
Pour contrôler la structure des données, j’utilise la fonction str ()
str(people) 
Cette fonction est très pratique, car elle permet de connaître :
- le format des données : ici un data frame
- les dimensions du jeu de données : ici 10 lignes (observations) et 8 colonnes (variables)
- le nom des variables : ici Name_FirstName, Sex, Age etc..
- le format de ces variables : ici Name_FirstName, Sex et Hair sont des variables catégorielles (factor), l’Age est une variable numérique de type entier, Height est une variable numérique continue
etc…
*Remarque* : Si vous ne voulez pas que les chaines de caractères soient converties en variables catégorielles dans R, vous pouvez utiliser l’argument `stringsAsFactor = FALSE` dans les fonctions d’importation :
people2 <- read.csv2(here::here("data","people.csv"), stringsAsFactors = FALSE)
str(people2)
## 'data.frame': 10 obs. of 8 variables:
## $ Name_FirstName: chr "Smith_Emily" "Jonhson_Mikael" "Williams_Ashley" "Jones_Alex" ...
## $ Sex : chr "F" "M" "F" "M" ...
## $ Age : int NA 253 38 15 79 56 63 19 24 -1
## $ Height : num 1.68 1.93 1.55 NA 1.63 1.7 1.5 1.87 1.52 2.15
## $ Hair : chr "Blond" "Brown" "Brown" "Other" ...
## $ Blue_Eye : int 1 0 0 0 1 1 0 0 0 0
## $ Brown_Eye : int 0 1 1 0 0 0 1 0 1 0
## $ Other_Eye : int 0 0 0 1 0 0 0 1 0 1 Le format souhaité : tidy !
Pour pouvoir être manipulées et analysées de façon optimale dans R, les données doivent être au format tidy :

C’est à dire avec :
- une ligne par observation,
- une variable par colonne,
- et une valeur au croisement d’une ligne et d’une colonne.
Gérer les problèmes de structure
Séparer une variable en deux colonnes
Si, par exemple, vous souhaitez séparer la variable « Name_FirstName » en une colonne « Name » et une colonne « First Name », vous pouvez le faire très simplement à l’aide de la fonction `str_separate()` du package `tidyr` qui fait parti du super package `tidyverse` :
library(tidyverse)
people <- people %>%
separate (Name_FirstName, c("Name", "FisrtName"))
head(people)
## Name FisrtName Sex Age Height Hair Blue_Eye Brown_Eye Other_Eye
## 1 Smith Emily F NA 1.68 Blond 1 0 0
## 2 Jonhson Mikael M 253 1.93 Brown 0 1 0
## 3 Williams Ashley F 38 1.55 Brown 0 1 0
## 4 Jones Alex M 15 NA Other 0 0 1
## 5 Brown Katie F 79 1.63 Blond 1 0 0
## 6 Davis John M 56 1.70 Other 1 0 0 La fonction inverse est la fonction unite().
Séparer les valeurs d'une colonne en deux lignes
Considérons le jeu de données suivant, avec dans la même colonne « Children » le nombre de garçons (B) et de filles (G) :
print(enfant)
## FirstName Children
## 1 Emily 1B/0G
## 2 Mikael 1B/2G
## 3 Ashley 0B/2G
## 4 Alex 3B/2G
## 5 Katie 1B/1G
## 6 John 1B/5G On pourrait vouloir créer une ligne pour le nombre de garçons (B) et une ligne pour le nombre de filles (G). Pour cela, on utilise la fonction separate_rows(), comme ceci :
enfant <- enfant %>%
separate_rows(Children, sep="/")
print(enfant)
## FirstName Children
## 1 Emily 1B
## 2 Emily 0G
## 3 Mikael 1B
## 4 Mikael 2G
## 5 Ashley 0B
## 6 Ashley 2G
## 7 Alex 3B
## 8 Alex 2G
## 9 Katie 1B
## 10 Katie 1G
## 11 John 1B
## 12 John 5G Quand le nom des colonnes sont des valeurs
people %>%
gather(Eye_Colour, Count,-c(Name:Hair)) %>%
arrange(Name) %>%
slice(1:10)
## Name FisrtName Sex Age Height Hair Eye_Colour Count
## 1 Brown Katie F 79 1.63 Blond Blue_Eye 1
## 2 Brown Katie F 79 1.63 Blond Brown_Eye 0
## 3 Brown Katie F 79 1.63 Blond Other_Eye 0
## 4 Davis John M 56 1.70 Other Blue_Eye 1
## 5 Davis John M 56 1.70 Other Brown_Eye 0
## 6 Davis John M 56 1.70 Other Other_Eye 0
## 7 Jones Alex M 15 NA Other Blue_Eye 0
## 8 Jones Alex M 15 NA Other Brown_Eye 0
## 9 Jones Alex M 15 NA Other Other_Eye 1
## 10 Jonhson Mikael M 253 1.93 Brown Blue_Eye 0 Dans un second temps, seules lignes avec un Count =1 sont conservées, puis la variable Count est supprimée.
Au final, le code utilisé est :
people <- people %>%
gather(Eye_Colour, Count,-c(Name:Hair)) %>%
filter(Count >=1) %>%
select(-Count)
print(people)
## Name FisrtName Sex Age Height Hair Eye_Colour
## 1 Smith Emily F NA 1.68 Blond Blue_Eye
## 2 Brown Katie F 79 1.63 Blond Blue_Eye
## 3 Davis John M 56 1.70 Other Blue_Eye
## 4 Jonhson Mikael M 253 1.93 Brown Brown_Eye
## 5 Williams Ashley F 38 1.55 Brown Brown_Eye
## 6 Miller Megan F 63 1.50 Brown_Eye
## 7 Moore Grace F 24 1.52 Blond Brown_Eye
## 8 Jones Alex M 15 NA Other Other_Eye
## 9 Wilson Matthew M 19 1.87 Brown Other_Eye
## 10 Taylor Jack M -1 2.15 Brown Other_Eye Modifier le nom des variables
Vous pouvez facilement modifier le nom des variables en utilisant la fonction name(). Par exemple pour changer « FirstName » en « Prenom » :
names(people)
## [1] "Name" "FisrtName" "Sex" "Age" "Height"
## [6] "Hair" "Eye_Colour"
names(people)[2] <- "Prenom"
names(people)
## [1] "Name" "Prenom" "Sex" "Age" "Height"
## [6] "Hair" "Eye_Colour" Les valeurs manquantes (NA)
Recherche des valeurs manquantes
Une méthode simple pour explorer les données manquantes est d’utiliser la fonction summary()
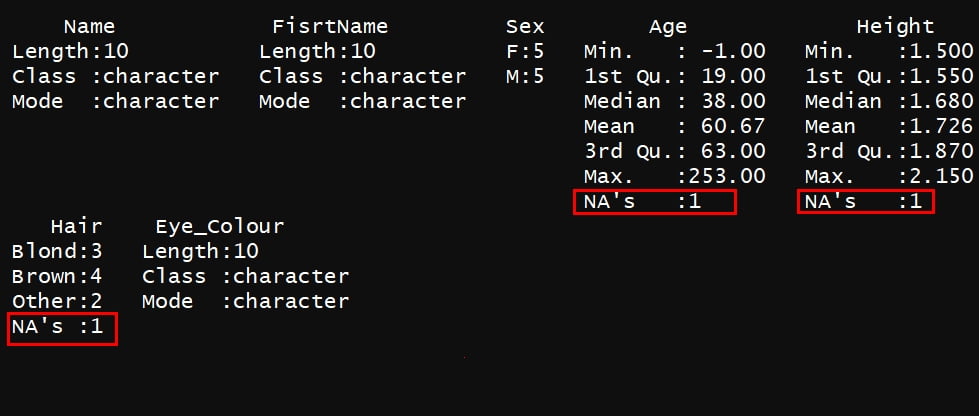
Une autre fonction très utile est la fonction `df_status()` du package `funModelling` qui renvoit, pour chaque variable, le nombre de valeurs égales à zéro, le nombre de valeurs manquantes, et le nombre de valeurs infinies (par exemple 1/0), ainsi que les pourcentages correspondant. Ici, appliquée au jeu de données heart_disease :
library(funModeling)
df_status(heart_disease)
## variable q_zeros p_zeros q_na p_na q_inf p_inf type
## 1 age 0 0.00 0 0.00 0 0 integer
## 2 gender 0 0.00 0 0.00 0 0 factor
## 3 chest_pain 0 0.00 0 0.00 0 0 factor
## 4 resting_blood_pressure 0 0.00 0 0.00 0 0 integer
## 5 serum_cholestoral 0 0.00 0 0.00 0 0 integer
## 6 fasting_blood_sugar 258 85.15 0 0.00 0 0 factor
## 7 resting_electro 151 49.83 0 0.00 0 0 factor
## 8 max_heart_rate 0 0.00 0 0.00 0 0 integer
## 9 exer_angina 204 67.33 0 0.00 0 0 integer
## 10 oldpeak 99 32.67 0 0.00 0 0 numeric
## 11 slope 0 0.00 0 0.00 0 0 integer
## 12 num_vessels_flour 176 58.09 4 1.32 0 0 integer
## 13 thal 0 0.00 2 0.66 0 0 factor
## 14 heart_disease_severity 164 54.13 0 0.00 0 0 integer
## 15 exter_angina 204 67.33 0 0.00 0 0 factor
## 16 has_heart_disease 0 0.00 0 0.00 0 0 factor
## unique
## 1 41
## 2 2
## 3 4
## 4 50
## 5 152
## 6 2
## 7 3
## 8 91
## 9 2
## 10 40
## 11 3
## 12 4
## 13 3
## 14 5
## 15 2
## 16 2 Gérer les valeurs manquantes
Supprimer les lignes comportant des NA
Pour ne conserver que les lignes du jeu de données ne comportant aucune donnée manquante, la fonction na.omit() peut être utilisée :
people_sans_NA <- na.omit(people)
summary(people_sans_NA)
## Name Prenom Sex Age
## Length:7 Length:7 F:3 Min. : -1.00
## Class :character Class :character M:4 1st Qu.: 21.50
## Mode :character Mode :character Median : 38.00
## Mean : 66.86
## 3rd Qu.: 67.50
## Max. :253.00
## Height Hair Eye_Colour
## Min. :1.520 Blond:2 Length:7
## 1st Qu.:1.590 Brown:4 Class :character
## Median :1.700 Other:1 Mode :character
## Mean :1.764
## 3rd Qu.:1.900
## Max. :2.150 Le nouveau jeu de données ne contient plus de NA. Il ne comporte plus que 7 lignes, contre 10 dans le fichier original.
dim(people_sans_NA)
## [1] 7 7 Remplacer les NA
Dans certaines situations, par exemple lorsque les données manquantes sont totalement aléatoires, on peut avoir envie de remplacer les NA par une moyenne, ou une médiane. Pour cela, on peut utiliser la fonction `replace_na` du package `tidyr`.
Par exemple, pour remplacer la valeur manquante de la variable Height, par la moyenne des valeurs :
people_rep <- people %>%
mutate(Height=replace_na(Height, mean(Height, na.rm=TRUE)))
summary(people_rep$Height)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.500 1.570 1.690 1.726 1.834 2.150
Il n'y a plus de données manquantes.
people_rep$Height
## [1] 1.680000 1.630000 1.700000 1.930000 1.550000 1.500000 1.520000
## [8] 1.725556 1.870000 2.150000 Et on peut voir que la donnée manquante a été remplacée par la valeur 1.725556.
Identifier les valeurs aberrantes
Les valeurs numériques
Fonction summary()
Les valeurs numériques aberrantes peuvent être identifiées grâce à la fonction summary(), notamment en prêtant attention aux valeurs min et max :
summary(people)
## Name Prenom Sex Age
## Length:10 Length:10 F:5 Min. : -1.00
## Class :character Class :character M:5 1st Qu.: 19.00
## Mode :character Mode :character Median : 38.00
## Mean : 60.67
## 3rd Qu.: 63.00
## Max. :253.00
## NA's :1
## Height Hair Eye_Colour
## Min. :1.500 Blond:3 Length:10
## 1st Qu.:1.550 Brown:4 Class :character
## Median :1.680 Other:2 Mode :character
## Mean :1.726 NA's :1
## 3rd Qu.:1.870
## Max. :2.150
## NA's :1 Par exemple, on peut voir ici que la variable Age dispose de deux valeurs aberrantes avec un minimum à -1 et un maximum 253 !
Tableur de RStudio
Pour identifier des valeurs numériques aberrantes, il peut aussi être utile, de visualiser la table de données dans le tableur de R Studio. Pour cela, cliquer sur le nom des données dans l’onglet Environnement, puis trier les valeurs :
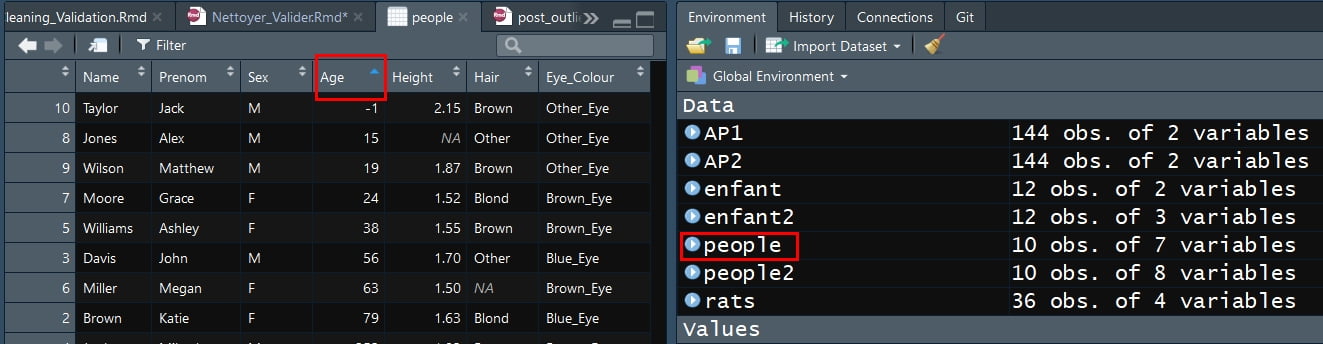
Pour ouvrir le tableur, vous pouvez aussi utiliser la fonction View()
View(people) Visualisations
Pour mettre en évidence des données aberrantes, il peut également être intéressant de réaliser des visualisations. On peut par exemple utiliser le code suivant pour ne sélectionner que les variables numériques et réaliser un dotplot pour chacune d’entre elles :
library(ggplot2)
people %>%
select_if(is.numeric) %>%
gather(variable, value) %>%
ggplot(aes(value))+
geom_dotplot()+
facet_wrap(~variable, scales="free") 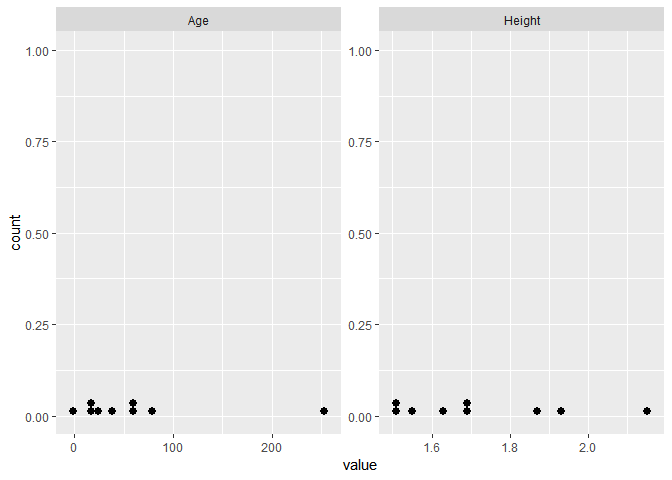
Les visualisations permettent d’identifier les valeurs extrêmes, ici 253 pour l’âge et une taille de plus de 2 mètres.
Les variables catégorielles
Pour identifier d’éventuelles fautes de frappe, ou d’orthographe dans les modalités des variables catégorielles, vous pouvez utiliser la fonction levels() :
levels(people$Hair)
## [1] "Blond" "Brown" "Other" Je vous recommande également l’utilisation du package `stringr` qui permet de nombreuses manipulations des chaînes de caractères. Vous trouverez sa cheat sheet ici :
Détecter les outliers
Un outlier, est une valeur ou une observation qui est « distante » des autres observations effectuées sur le même phénomène, c’est-à-dire qu’elle contraste grandement avec les valeurs « normalement » mesurées. Un outlier peut être du à la variabilité inhérente au phénomène observé, il peut aussi être la marque d’ une erreur expérimentale, ou d’une erreur lors de l’entrée des données.
Selon les causes de cette valeur distante des autres, l’outlier peut être conservé ou supprimé.
Pour détecter les outlier, on utilise fréquemment un boxplot. Les outliers sont alors représentés sur le graph, par un point :
people %>%
select_if(is.numeric) %>%
gather(variable, value) %>%
ggplot(aes(y=value,x=variable, fill=variable, colour=variable))+
geom_boxplot(alpha=0.5)+
facet_wrap(~variable, scales="free") 
Pour rappels, les règles de lecture du boxplot sont les suivantes :
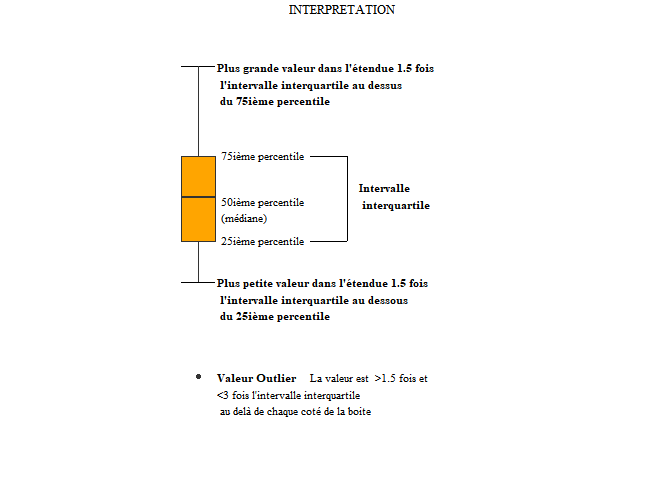
Pour connaître les valeurs des outliers, on peut utiliser la fonction boxplot.stat():
outlier_age <- boxplot.stats(people$Age)$out
outlier_age
## [1] 253 Ici seul 253 apparaît comme un outlier.
Pour connaître l’indice de la ligne comportant cette valeur outlier, on peut utiliser la commande suivante :
outlier_idx <- which(people$Age %in% c(outlier_age))
outlier_idx
## [1] 4
Ici, l'âge 253 se situe sur la ligne 4. Pour le vérifier :
people[4,]
## Name Prenom Sex Age Height Hair Eye_Colour
## 4 Jonhson Mikael M 253 1.93 Brown Brown_Eye Les jeux de données utilisés dans cet article
Name_FirstName <-c("Smith_Emily", "Jonhson_Mikael", "Williams_Ashley", "Jones_Alex", "Brown_Katie", "Davis_John","Miller_Megan", "Wilson_Matthew", "Moore_Grace", "Taylor_Jack")
Sex <- c("F", "M","F", "M","F", "M","F", "M","F", "M")
Age <- c(NA, 253L,38L, 15L, 79L, 56L, 63L, 19L, 24L,-1L)
Height <- c(1.68, 1.93, 1.55, NA, 1.63, 1.70, 1.50, 1.87, 1.52, 2.15)
Hair <- c("Blond", "Brown", "Brown", "Other", "Blond", "Other", NA, "Brown", "Blond", "Brown")
Blue_Eye <- c(1,0,0,0,1,1,0,0,0,0)
Brown_Eye <- c(0,1,1,0,0,0,1,0,1,0)
Other_Eye <- c(0,0,0,1,0,0,0,1,0,1)
people <- data.frame (Name_FirstName=Name_FirstName,
Sex =Sex ,
Age=Age,
Height=Height,
Hair=Hair,
Blue_Eye=Blue_Eye,
Brown_Eye=Brown_Eye,
Other_Eye=Other_Eye
)
FirstName <-c("Emily", "Mikael", "Ashley", "Alex", "Katie", "John")
Children <- c("1B/0G", "1B/2G", "0B/2G","3B/2G", "1B/1G", "1B/5G" )
enfant <- data.frame(FirstName ,Children) Conclusion
Et vous, quelles fonctions utilisez vous fréquemment lorsque vous nettoyer vos données ? Indiquez-les-moi en commentaire pour les partager.
En attendant, j’espère que cet article permettra aux débutants d’acquérir les bases, et les bons réflexes, pour nettoyer et valider plus facilement leurs données.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 
Crédits photos : blickpixel

Merci Claire pour cet article qui vient renforcer de façon coriace nos connaissance. Grand merci à toi Claire une de plus.
Génial cet article où les différentes méthodes d’importation des données sont regroupées.
Je suis néanmoins resté sur ma faim en ce qui concerne les nettoyages de données comme avec la fonction tsclean.
Tu-Anh.
Bonjour,
tsclean est pour les données temporelles, c’est vrai que je n’ai pas abordé ce sujet. Je pense que je vais faire un article sur le package lubridate et je regarderai comment parler de cette fonction. Dans tous les cas, merci pour le partage.
Bonjour et bonne année 2019. Je voudrais avoir la version pdf de vos cours sur R.
Bonjour, je n’ai pas de version pdf de mes articles, mais vous pouvez faire une impression « pdf » à partir de votre navigateur. Bonne continuation.
Bonjour et bonne année 2019. Comment parameter mon logiciel R pour avoir une console de couleur noire?
Bonjour, il suffit d’aller Tools –> Global options –> Appearance et choisir un thème.
Bonne continuation
Vraiment géniales vos articles !!! Merci.
Bonjour Claire 🙂
Merci pour tes articles parce que j’en ai déjà lus plusieurs sans jamais commenté mais je profite du coup de l’occasion pour te remercier d’un seul coup pour tout ce que j’ai déjà lu. Merciiiii !!!
Une question toutefois, je ne parviens pas à saisir le sens des codes %in%, %>%, %blablabla% alors que je les vois partout. A quoi servent-elles, sont-elles indispensables ? Je n’ai pas trouvé d’articles à se sujet sur ton site et j’ai pas compris les explications sur les autres sites ouverts.
Bonne journée
Bonjour Doni,
merci pour votre message.
Le symbole %>% est appelé « pipe », on peut le traduire par « et puis ». Dans l’exemple :
mydata %>%
mutate(my_new_var = my_var1 * 2)
C’est un peu comme si on disait à R « prends mydata ET PUIS crée une nouvelle variable en multipliant par 2 les valeurs de la variable my_var1 ».
Le symbole %in% est utilisé par le package dplyr pour dire « dans cette condition » ou « appartenant à cette condition ». Par exemple :
iris %>%
filter(Species %in% c(« setosa », « virginica »))
On pourrait traduire par « prends le jeu de données iris ET PUIS sélectionne (fonction filter) les lignes dont la variable Species appartient à setosa ou a virginica ».
C’est un peu expliqué dans cet article : https://wp.me/p93iR1-BV
J’espère que ça vous aide.
Bonne continuation
Bonjour Claire.
Je n’avais pas reçu le mail de la notification pour ta réponse mais je viens d’en prendre connaissance. Merci pour ces informations, je vais porter mon attention sur le lien que tu m’as transmis. Pour ce qui est de ton second exemple, j’avais l’habitude de la coder ainsi :
Set_Vir<-c(iris[iris$species=="Virginica",],iris[iris$species=="Setosa"])
Mais je pense que l'utilisation de ces symboles sera plus pratiques.
Merci bien 🙂
Merci pour ces explications.