Comment détecter les outliers avec R
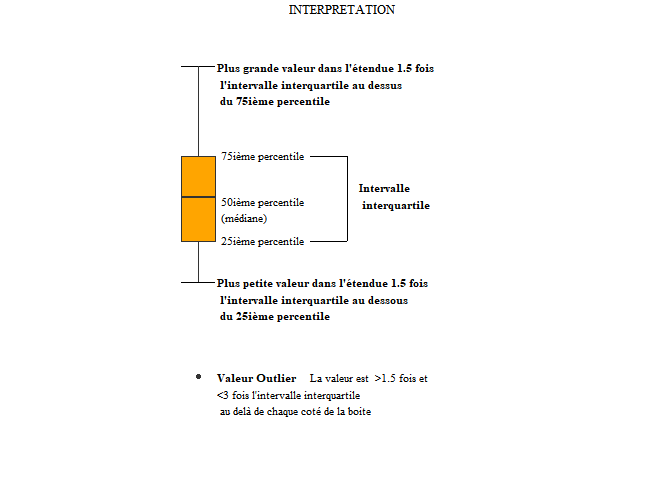
Table des matières
C'est quoi un outlier ?
Un outlier, ou donnée aberrante est « une valeur ou une observation qui est « distante » des autres observations effectuées sur le même phénomène, c’est-à-dire qu’elle contraste grandement avec les valeurs « normalement » mesurées. Une donnée aberrante peut être due à la variabilité inhérente au phénomène observé ou bien elle peut aussi indiquer une erreur expérimentale. Les dernières sont parfois exclues de la série de données ».(wikipedia)
Détection des outliers par boxplots ?
Une méthode classiquement employée pour détecter les outliers, consiste à réaliser un boxplot. On parle alors de méthode de détection univariée car elle ne concerne qu’une seule dimension, ou variable.
Réalisation des boxplots
Voici comment réaliser des boxplots avec le package ggplot2. Je prends ici comme exemple les données « mpg » contenues dans le package « ggplot2 », et je m’intéresse à la variable « hwy » (Highway miles per gallon) en fonction du type de véhicule (variable class)
library(ggplot2)
ggplot(mpg, aes( x=class,y=hwy, fill=class)) +
geom_boxplot()+
xlab(label = "Type of car") +
ylab(label = "Highway miles per gallon") +
theme(axis.text.x = element_text(angle=30, hjust=1, vjust=1))+
theme(legend.position="none")+
ggtitle("Exemple de boxplots sur les données mpg") 
Sur cette visualisation des données, les outliers sont représentés sous forme de points. Ils correspondent à des observations dont les valeurs sont :
- supérieures à la valeur du 3ème quartile plus 1.5 fois l’intervalle inter-quartile,
- ou inférieures à la valeur du 1er quartile moins 1.5 fois l’intervalle inter-quartile.
Règle d'interprétation des boxplots
Pour celles et ceux qui ne sont pas très familiers avec les boxplots, voici un rappel des règles d’interprétation (d’après Laura DeCicco).

Récupération des valeurs outliers
Imaginons, par exemple, que je souhaite obtenir les valeurs des observations outliers (concernant la variable hwy), correspondant aux voitures de type SUV (le boxplot rose sur grap du paragraphe 2.1). Pour cela, j’utilise la fonction boxplot.stats() :
# sélection des données suv
suv <- mpg %>%
filter(class=="suv")
boxplot.stats(suv$hwy)$out
## [1] 12 12 25 24 27 25 26 23 Récupérer l'indice des outliers
Il peut être intéressant de connaître sur quelles lignes du jeu de données se trouvent les outliers. Pour cela, on peut garder les valeurs outliers dans un objet, puis l’utiliser en argument de la fonction which(), comme ceci :
outlier_val <- boxplot.stats(suv$hwy)$out
outlier_val
## [1] 12 12 25 24 27 25 26 23
outlier_idx <-which(suv$hwy %in% c(outlier_val))
outlier_idx
## [1] 12 30 49 50 51 52 53 54 Pour vérifier, on peut afficher les lignes correspondant à outlier_idx:
suv[outlier_idx,]
## # A tibble: 8 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
##
## 1 dodge dura~ 4.7 2008 8 auto~ 4 9 12 e suv
## 2 jeep gran~ 4.7 2008 8 auto~ 4 9 12 e suv
## 3 subaru fore~ 2.5 1999 4 manu~ 4 18 25 r suv
## 4 subaru fore~ 2.5 1999 4 auto~ 4 18 24 r suv
## 5 subaru fore~ 2.5 2008 4 manu~ 4 20 27 r suv
## 6 subaru fore~ 2.5 2008 4 manu~ 4 19 25 p suv
## 7 subaru fore~ 2.5 2008 4 auto~ 4 20 26 r suv
## 8 subaru fore~ 2.5 2008 4 auto~ 4 18 23 p suv Juxtaposer les observations sur les boxplots
Lorsque je réalise un boxplot, j’ai pour habitude de faire également figurer les observations, parce que ça permet de se faire une meilleure idée du nombre de données et de leur répartition. Pour cela, j’utilise la couche geom_jitter().
Remarque : L’argument width de la fonction geom_jitter() permet de gérer la largeur de répartition des points à l’intérieur du boxplot.
ggplot(mpg, aes( x=class,y=hwy, fill=class, colour=class)) +
geom_jitter(width=0.25) +
geom_boxplot(alpha=0.5)+
xlab(label = "Type of car") +
ylab(label = "Highway miles per gallon") +
theme(axis.text.x = element_text(angle=30, hjust=1, vjust=1))+
theme(legend.position="none")+
theme_classic()+
ggtitle("Boxplot avec les observations") 
Le problème de ce type de boxplot, c’est que les outliers sont représentés deux fois: une fois en tant qu’observation et une fois en tant qu’outlier (les points sont plus clairs, ils sont particulièrement visibles dans la partie supérieure du boxplot rose).
Pour éviter cette double représentation, j’utilise l’argument outlier.shape=NA, ce qui permet de ne pas afficher la version outlier :
ggplot(mpg, aes( x=class,y=hwy, fill=class, colour=class)) +
geom_jitter(width=0.25)+
geom_boxplot(alpha=0.5, outlier.shape=NA)+
xlab(label = "Type of car") +
ylab(label = "Highway miles per gallon") +
theme(axis.text.x = element_text(angle=30, hjust=1, vjust=1))+
theme(legend.position="none")+
theme_classic()+
ggtitle("Boxplot avec les observations") 
A présent, les outliers sont simplement tous les points au delà des traits verticaux de part et d’autre de chaque boite.
Les autres méthodes de détection univariées
Méthode basée sur les percentiles
Il existe d’autres méthodes de détection des outliers. L’une d’elles consiste à considérer comme outlier les données se situant à l’extérieur de l’intervalle constituté par les percentiles 2.5 et 97.5 par exemple, ou encore par les percentiles 1 et 99.
pinf = 0.025 # fixe le percentile de limite inférieure
psup = 0.97 5# fixe le percentile de limite inférieure
binf <- quantile(suv$hwy,pinf) # calcule la borne inf de l'intervalle
binf
## 2.5%
## 13.05
bsup <- quantile(suv$hwy,psup) # calcule la borne sup de l'intervalle bsup
## 97.5%
## 25.475 On peut obtenir les indices des lignes des outliers comme ceci:
outlier_idx <- which(suv$hwy < binf | suv$hwy > bsup)
outlier_idx
## [1] 12 30 51 53 Puis leur valeur :
outlier_val <- suv[outlier_idx,"hwy"]
outlier_val
## # A tibble: 4 x 1
## hwy
##
## 1 12
## 2 12
## 3 27
## 4 26 La méthode de Hampel
Une autre méthode, dite de Hampel, consiste à considérer comme outliers les valeurs en dehors de l’intervalle constitué par la médiane, plus ou moins 3 déviation absolue de médiane :
\[ I=[median – 3\;\ast mad \;;\;median + 3\;\ast mad ] \]
Avec :
\[ mad = \text{Median Absolute Deviation} \]
Et:
\[ mad=median\;(|y_{i} – \tilde{y} |) \]
et
\[ \tilde{y} = median(y) \]
Parfois, une autre valeur que 3 est employée pour calculer l’intervalle.
Voici comment constituer l’intervalle selon la méthode de Hampel.
k= 3
# calcule la borne inf de l'intervalle binf
binf <- median(suv$hwy) - k * mad (suv$hwy)
binf
## [1] 10.8283
# calcule la borne sup de l'intervalle bsup
bsup <- median(suv$hwy) + k * mad (suv$hwy)
bsup
## [1] 24.1717 Il est ensuite facile d’obtenir l’indice des lignes contenant les outliers :.
outlier_idx <- which(suv$hwy < binf | suv$hwy > bsup)
outlier_idx
## [1] 49 51 52 53
Puis leur valeur :
outlier_val <- suv[outlier_idx,"hwy"]
outlier_val
## # A tibble: 4 x 1
## hwy
##
## 1 25
## 2 27
## 3 25
## 4 26 Le test statistique de Grubbs
Le test statistique de Grubbs permet de tester si la valeur la plus élevée est un outlier. Son hypothèse nulle spécifie que la valeur la plus élevée n’est pas un outlier, alors que son hypothèse alternative spécifie que la valeur la plus élevée est un outlier. Si la p-value du test est inférieure au seuil de significativité choisi (en général 0.05) alors on concluera que la valeur la plus élevée est outlier. Pour réaliser ce test avec R, on utilise la fonction grubbs.test() du package « outliers » :
library(outliers)
grubbs.test(suv$hwy)
##
## Grubbs test for one outlier
##
## data: suv$hwy
## G = 2.97890, U = 0.85215, p-value = 0.06296
## alternative hypothesis: highest value 27 is an outlier Ici la p-value est proche du seuil de significativité, j’aurais tendance à considérer la valeur la plus haute (27) comme étant un outlier.
Il est possible de tester le caractère outlier de la plus faible valeur en utilisant l’argument opposite=TRUE :
grubbs.test(suv$hwy, opposite = TRUE)
##
## Grubbs test for one outlier
##
## data: suv$hwy
## G = 2.05810, U = 0.92942, p-value = 1
## alternative hypothesis: lowest value 12 is an outlie Ici, la plus faible valeur (12) n’est pas considérée comme un outlier.
Détection des outliers sur les résidus
Dans le cadre d’une régression, il est possible de mettre en évidence des outliers sur les résidus, en employant la fonction outlierTest() du package « car ». Je réalise ici une régression linéaire simple de la variable « hwy » (highway miles per gallon) en fonction de la variable « displ » (engine displacement, in litres) :
ggplot(suv, aes(x=displ, y=hwy))+
geom_point()+
geom_smooth(method="lm") 
fit <- lm(hwy~displ, data=suv) Les plots des distances de cook permettent déjà d’identifier certains points outliers, ici les données 51, 53, et 49.
plot(fit,4) 
library(car)
outlierTest(fit)
## No Studentized residuals with Bonferonni p < 0.05
## Largest |rstudent|:
## rstudent unadjusted p-value Bonferonni p
## 12 -2.644498 0.010466 0.64891 Ici, la p-value ajustée par la méthode de Bonferonni est très éloignée du seuil de 0.05. Le résidus le plus élevé, ne peut donc pas être considéré comme outlier. Pour vérifier quel est l’indice du résidu le plus élevé, on peut utiliser la commande suivante :
which.max(rstudent(fit))
## 51
## 51 Que faire des outliers ?
En premier lieu, les données détectées comme outliers doivent être vérifiées.
Pour la suite, il n’y a pas de réponse unique à cette question !
Dans certains domaines, comme en génomique ou protéomique, il n’est pas rare de supprimer les outliers du jeu de données, car ces données extrêmes sont considérées comme issues d’un processus qui a dysfonctionné.
Dans d’autres domaines, au contraire, ces données extrêmes sont conservées, mais les analyses statistiques sont conduites avec et sans, afin d’évaluer leur impact sur les résultats, voir un exemple dans le paragraphe 7 de cet article .
Pour aller plus loin
Vous trouverez d’autres méthodes d’identification des outliers dans le chapitre 7 du livre « R and Data Mining: Examples and Case Studies« .
Le package « Outliers » contient également plusieurs fonctions dédiées à la détection et à la gestion des outliers.
ls("package:outliers")
## [1] "chisq.out.test" "cochran.test" "dixon.test" "grubbs.test"
## [5] "outlier" "pcochran" "pdixon" "pgrubbs"
## [9] "qcochran" "qdixon" "qgrubbs" "qtable"
## [13] "rm.outlier" "scores" Le code des règles de décision du boxplot
J’ai adapté le code original développé par Laura DeCicco et disponible là.
library(tidyverse)
library(cowplot)
ggplot_box_legend <- function(family = "serif"){
# Create data to use in the boxplot legend: set.seed(100)
sample_df <- data.frame(parameter = "test", values = sample(500))
# Extend the top whisker a bit:
sample_df$values[1:100] <- 701:800
# Make sure there's only 1 lower outlier:
sample_df$values[1] <- -350
# Function to calculate important values:
ggplot2_boxplot <- function(x){ quartiles <- as.numeric(quantile(x, probs = c(0.25, 0.5, 0.75)))
names(quartiles) <- c("25ième percentile", "50ième percentilen(médiane)", "75ième percentile")
IQR <- diff(quartiles[c(1,3)])
upper_whisker <- max(x[x < (quartiles[3] + 1.5 * IQR)])
lower_whisker <- min(x[x > (quartiles[1] - 1.5 * IQR)])
upper_dots <- x[x > (quartiles[3] + 1.5*IQR)]
lower_dots <- x[x < (quartiles[1] - 1.5*IQR)]
return(list("quartiles" = quartiles, "25ième percentile" = as.numeric(quartiles[1]), "50ième percentilen(médiane)" = as.numeric(quartiles[2]), "75ième percentile" = as.numeric(quartiles[3]), "IQR" = IQR, "upper_whisker" = upper_whisker, "lower_whisker" = lower_whisker, "upper_dots" = upper_dots, "lower_dots" = lower_dots)) }
# Get those values:
ggplot_output <- ggplot2_boxplot(sample_df$values)
# Lots of text in the legend, make it smaller and consistent font:
update_geom_defaults("text", list(size = 3, hjust = 0, family = family))
# Labels don't inherit text:
update_geom_defaults("label", list(size = 3, hjust = 0, family = family))
# Create the legend:
# The main elements of the plot (the boxplot, error bars, and count) are the easy part.
# The text describing each of those takes a lot of fiddling to
# get the location and style just right:
explain_plot <- ggplot() + stat_boxplot(data = sample_df,aes(x = parameter, y=values),geom ='errorbar', width = 0.3) +
geom_boxplot(data = sample_df,aes(x = parameter, y=values), width = 0.3, fill = "orange") +
# geom_text(aes(x = 1, y = 950, label = "500"), hjust = 0.5) +
# geom_text(aes(x = 1.17, y = 950, label = "Nombre d'observations"),fontface = "bold", vjust = 0.4) +
theme_minimal(base_size = 5, base_family = family) +
geom_segment(aes(x = 2.3, xend = 2.3, y = ggplot_output[["25ième percentile"]], yend = ggplot_output[["75ième percentile"]])) +
geom_segment(aes(x = 1.2, xend = 2.3, y = ggplot_output[["25ième percentile"]], yend = ggplot_output[["25ième percentile"]])) +
geom_segment(aes(x = 1.2, xend = 2.3, y = ggplot_output[["75ième percentile"]], yend = ggplot_output[["75ième percentile"]])) +
geom_text(aes(x = 2.4, y = ggplot_output[["50ième percentilen(médiane)"]]), label = "Intervallen interquartile", fontface = "bold",vjust = 0.4) +
geom_text(aes(x = c(1.17,1.17), y = c(ggplot_output[["upper_whisker"]], ggplot_output[["lower_whisker"]]), label = c("Plus grande valeur dans l'étendue 1.5 foisn l'intervalle interquartile au dessusn du 75ième percentile", "Plus petite valeur dans l'étendue 1.5 foisn l'intervalle interquartile au dessousn du 25ième percentile")), fontface = "bold", vjust = 0.9) +
geom_text(aes(x = c(1.17), y = ggplot_output[["lower_dots"]], label = "Valeur Outlier "), vjust = 0.5, fontface = "bold") + geom_text(aes(x = c(1.9), y = ggplot_output[["lower_dots"]],label = " La valeur est >1.5 fois et"), vjust = 0.5) + geom_text(aes(x = 1.17, y = ggplot_output[["lower_dots"]], label = "<3 fois l'intervalle interquartilen au delà de chaque coté de la boite"), vjust = 1.5) +
geom_label(aes(x = 1.17, y = ggplot_output[["quartiles"]], label = names(ggplot_output[["quartiles"]])), vjust = c(0.4,0.85,0.4), fill = "white", label.size = 0) +
ylab("") +
xlab("") +
theme(axis.text = element_blank(), axis.ticks = element_blank(), panel.grid = element_blank(), aspect.ratio = 4/3, plot.title = element_text(hjust = 0.5, size = 10)) +
coord_cartesian(xlim = c(1.4,3.1), ylim = c(-600, 900)) +
labs(title = "INTERPRETATION") return(explain_plot) } Conclusion
Et vous, quelle méthode utilisez vous pour détecter les outliers ? Et comment les gérer vous dans la suite de vos analyses statistiques ?
Et comme d’habitude, si cet article vous a plus, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee

Credits photos : geralt
Credits photos : geralt

Très riche
Il est vraiment un article très utile…bonne continuation.
Bonjour Claire, très intéressant l’article, il va nous être très utile car c’est notre prochain objectif : valider les données !
Merci et à bientôt
Miriam BASSO
Bonjour Miriam, ravie que cet article vous aide. Bonne continuation !
Bonjour,
je voudrais vous souhaiter une bonne année.
je suis entrain de préparer une publication sur l’écologie des dinoflagellés épiphytes. mes résultats comportent des outliers. votre article va m’aider beaucoup dans l’interprétation de mes graphes.
merci
Bonjour ,
j’ai aimé votre publication. je voudrais juste apporter juste une petite extension du test de grubbs. En fait ce test est itératif. par exemple si la plus grande valeur est aberrante, il faut continuer à test si la valeur qui vient avant cette valeur est aussi aberrante. vous pouvez revoir ce code.
compact% filter(class== »compact »)
nrow(compact)
grubbs.test(compact$hwy) #la born sup est abberant
##test de grubbs itératif
#names(grubbs.test(compact$hwy))
compact_bis<-compact
while(grubbs.test(compact$hwy)$p.value <0.05){
compact% filter(hwy<max(hwy,na.rm = T))
}
nrow(compact)
nrow(compact_bis)
outlier2 <-setdiff(compact_bis$hwy,compact$hwy) #"" compar 2 vecteu
compact_bis% mutate(out=hwy %in% outlier2)
compact_bis
Bonjour,
Merci beaucoup pour votre article !!
Petite question complémentaire, vous avez choisi de connaître les outliers uniquement de la catégorie SUV de votre variable class.
Si on souhaite obtenir les outliers de chaque catégorie de cette variable, quelle formule peut-on utiliser ? (A part filtrer une à une les catégories…)
En vous remerciant par avance,
Bonjour,
vous trouverez quelques éléments de réponses sur cette page : https://www.r-bloggers.com/combined-outlier-detection-with-dplyr-and-ruler/
Bonne continuation.
Bonjour Claire,
Comme toujours, vos articles sont très qualitatifs et apportent beaucoup d’informations pertinentes. Merci à vous pour ces publications.
En ce qui concerne la détection de valeurs aberrantes, je suis amené à les recherches dans le cadre des validations des méthodes d’analyse. Dans ce contexte, il semblerait que les tests privilégiés soient principalement les tests de Cochran et de Grubbs.
En ce qui concerne le test de Grubbs, on peut en mettre en oeuvre deux types : un pour rechercher une valeur extrême seulement (test de Grubbs simple) ou une paire de valeurs extrêmes (test de Grubbs double au cas où la valeur extrême serait « camouflée » par une valeur trop proche d’elle). Il y a aussi un test de Grubbs double qui teste les 2 valeurs extrêmes (la plus faible et la plus grande) à la fois (mais j’avoue ne pas bien comprendre l’intérêt de ce dernier).
De plus, comme les valeurs extrêmes sont toujours « délicates » à traiter (une donnée obtenue devant essentiellement être considérée comme existante et comprendre donc pourquoi elle est apparue…), il convient d’être prudent avant de la considérer comme aberrante. Ainsi, dans le protocole proposé pour les validations des methodes d’analyse, on considéra qu’une valeur est aberrante à partir du moment où la p-value du test renvoie une valeur inférieure à 1%. Si cette p-value est seulement inférieure à 5% (et supérieure à 1%), on considère alors que la valeur testée est suspecte.
La décision finale quant au devenir de cette valeur extrême reste néanmoins floue ou du moins à la discrétion de l’expérimentateur (on la supprime en général lorsqu’on la détectée comme aberrante mais la décision est laissée au choix lorsqu’elle n’est que suspecte)…
Bien cordialement
Bonjour Philippe,
Merci pour votre commentaire. Depuis la rédaction de cet article, j’ai découvert le package performance qui propose une fonction check_outliers(), qui permet d’utiliser plusieurs méthodes (celle de Tukey avec les IQR, celle bassée sur les percentiles etc..), il y a même des méthodes mutivariées.
Merci. J’ai découvert aussi le package rstatix qui permet d’obtenir facilement une table avec les outliers avec la méthode hors les « boxplot » : https://rdrr.io/cran/rstatix/man/outliers.html.