Lorsque je réalise des séances de coaching individuelles, ou lorsque je fais des formations, je commence toujours par expliquer comment organiser efficacement son flux de travail sous R. Ce sont des étapes clés, qui a mon sens, doivent être engagées avant même de parler d’analyse de données !
C’est cette organisation que je partage aujourd’hui avec vous dans cet article.
La première chose à faire, quand vous débutez un nouveau projet d’analyse de données, c’est d’encapsuler votre travail dans un projet R spécifique.
Pour cela :
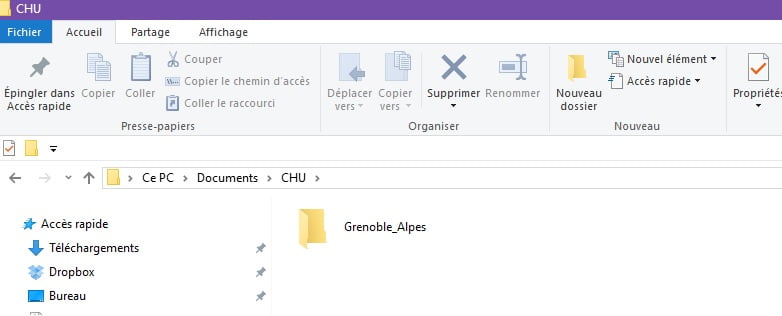
Puis, dans R Studio : File –> New Project –> Existing directory
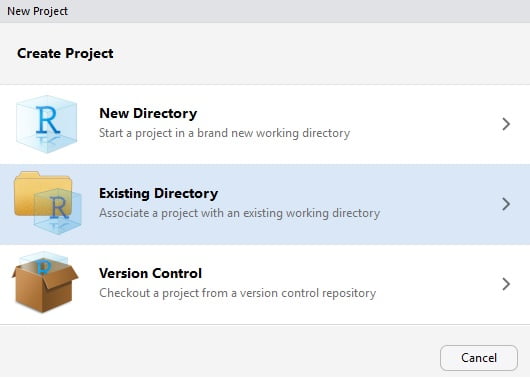

Maintenant que vous avez un projet R spécifique à votre projet d’analyse (que vous allez bientôt commencer), je vous recommande de le structurer en y ajoutant quelques dossiers qui vous permettrons de ranger efficacement vos documents, et évitez qu’ils se retrouvent tous à la racine du projet
Par exemple vous pouvez créer :

C’est cette organisation que j’utilise généralement, elle me convient bien.
Pour aller chercher les données dans le dossier “data”, ou les images dans le dossier “img”, ou encore sauvegarder les visualisations dans le dossier “plot” j’utilise le package “here” , qui permet de créer les chemins d’accès relatifs. Par exemple, pour importer un fichier de données nommé “mydata.csv” placé dans le dossier « data », on peut utiliser la commande suivante, qui est très simple :
read.csv2(here::here("data", "mydata.csv")) Le premier “here” correspond au nom du package, et le deuxième au nom de la fonction !
De même pour insérer dans un script en R markdown, une image stockée le dossier “data”, il suffit d’utiliser la commande :
include_graphics(here::here("img","workflowTree.JPG") ) Et pour sauvegarder des visualisations dans le dossier “plot”, par exemple:
library(ggplot2)
jpeg(here::here("plot","myplot.jpeg"), width = 15, height =12, units="cm", quality=75, res=300)
ggplot(iris, aes(y=Sepal.Length, x=Sepal.Width)) +
geom_point()+
geom_smooth()
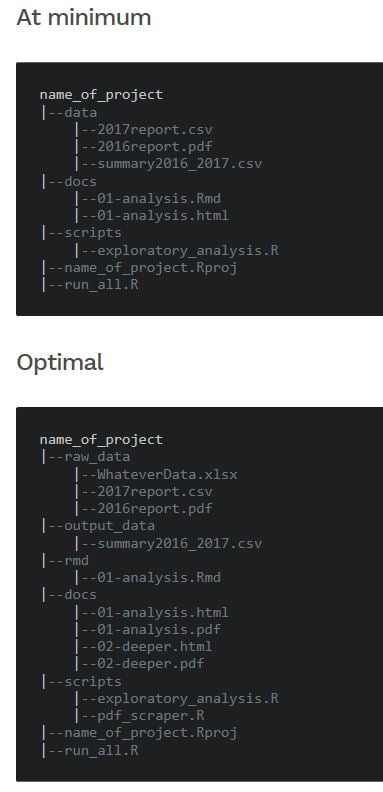
dev.off() D’autres structurations du projet R sont possibles. A long terme c’est à vous de trouver celle qui vous convient le plus. En attendant vous pouvez vous inspirer de celle là :

Ou encore de celles là :
C’est un format qui fonctionne avec des balises, un peu comme le langage html, et qui permet de générer automatiquement des rapports d’analyse.
Je vous recommande d’utiliser systématiquement ce format, et pas uniquement en fin d’analyse pour éditer le rapport d’analyse statistique.
C’est beaucoup plus efficace de mener une analyse de données sous ce format puisque vous pouvez faire figurer les commandes utilisées, les résultats obtenus, et commenter ces derniers. Ainsi, vous gardez toujours une trace de votre cheminement, des décisions que vous avez prises etc…Et à la fin vous pourrez simplement choisir de faire apparaître ou pas certaines partie de l’analyse dans le rapport final.
L’apprentissage de ce format est très simple, il y a seulement quelques éléments à connaître pour débuter. Cela vous demandera moins de 10 minutes d’investissement.
Pour vous aider à franchir le pas, j’ai écrit :
De plus le format R markdown permet également de générer des diapositives ou encore de créer un dashboard. Pour plus d’infos consulter le livre “R Markdown: The Definitive Guide”.

Avec ce format, non seulement vous réalisez votre analyse (avec le code R) mais en plus vous préparer aussi, dans le même temps, vos livrables (rapports) et vos supports de communications (slides, dashboard).
Maintenant que vous êtes bien organisé pour mener vos analyses de données, il reste tout de même une étape : celle de la création du fichier de données !
C’est une étape essentielle, et en adoptant quelques règles simples, vous vous éviterez de perdre un temps précieux au moment de l’importation, ou encore de vous arracher les cheveux pour reformater les données sous R.
Les deux points principaux de ces règles simples sont :

D’après Wickham, H., & Grolemund, G. (2016). R for data science: import,tidy, transform, visualize, and model data.
Le format csv est recommandé parce qu’il ne dépend pas d’un logiciel en particulier, contrairement au format xlsx qui est propre à Excel. Ainsi, en cas de perte de votre licence Excel, vous pourrez toujours accéder à vos données. Et de même, en cas de collaboration, tout le monde sera en mesure d’ouvrir un fichier csv en utilisant un logiciel libre, comme open office par exemple.
Vous trouverez d’autres conseils, par exemple pour gérer les données manquantes, ou encore les dates, dans mon article « 12 conseils pour organiser efficacement vos données dans un tableur « .
Bien sûr, certain type de données, comme des chaînes de caractères ou des textes ne peuvent pas se structurer comme cela.
A mes yeux, ces quatre étapes (projet R, structuration du projet R, utilisation de R markdown et mise en forme des données) représentent le noyau minimal des éléments à mettre en place avant toute analyse de données.
Mais si vous voulez être encore plus efficace, je vous propose de suivre trois étapes supplémentaires.
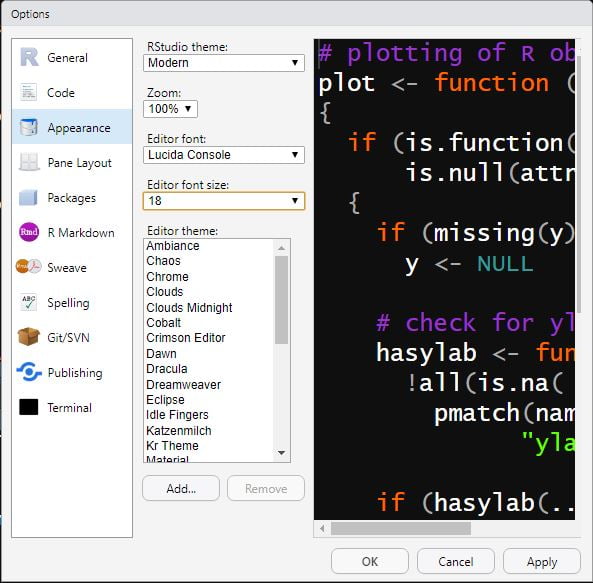
Il s’agit simplement de vous rendre l’utilisation de R Studio plus agréable. Par exemple, de nombreuses personnes (dont je fais partie) préfèrent travailler avec un fond d’écran sombre plutôt que clair. Certains encore préfèrent augmenter la taille de la police.
Pour faire ces modifications : Tools –> Global options –> Appearance
Pour s’organiser davantage, et ne pas avoir un dossier de travail saturé de différentes versions d’un même script (en R markdown !) il est possible de faire du versionnage depuis R Studio, avec git.
En pratique cela veut dire que vous allez pouvoir faire comme un cliché de votre script, à n’importe quel moment ( à la fin de votre séance de travail, ou avant une grosse modification par exemple). Vous devez accompagner ce “cliché”, que l’on appelle “commit” d’un message explicatif (destiné à vous même).

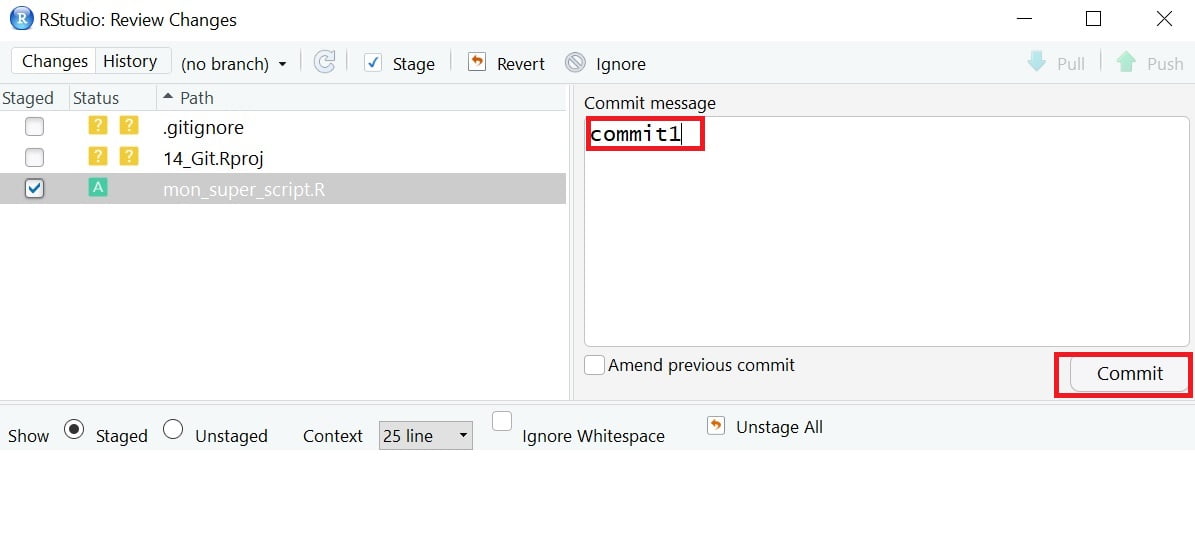
La version du script va alors être archivée, vous pourrez y avoir accès, depuis l’interface de R Studio, et vous repérer parmi les différentes versions grâce au message que vous aurez ajouté.
Et puis surtout, vous pourrez visualiser très rapidement les modifications que vous avez réalisé entre deux versions :

Pour plus de détails sur l’installation de git et le versionnage de vosvscripts, consultez l’article Versionnage de vos scripts avec RStudio + Git
C’est un processus que je ne fais pas toujours, loin de là, mais dans certaines situations, c’est vraiment chouette, et professionnel de pouvoir insérer des références bibliographiques propres dans un rapport d’analyse.
Pour cela, vous pouvez utiliser Mendeley. L’approche est assez simple à mettre en oeuvre, elle consiste à :
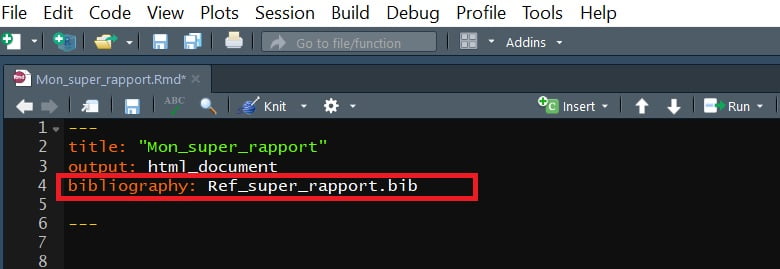
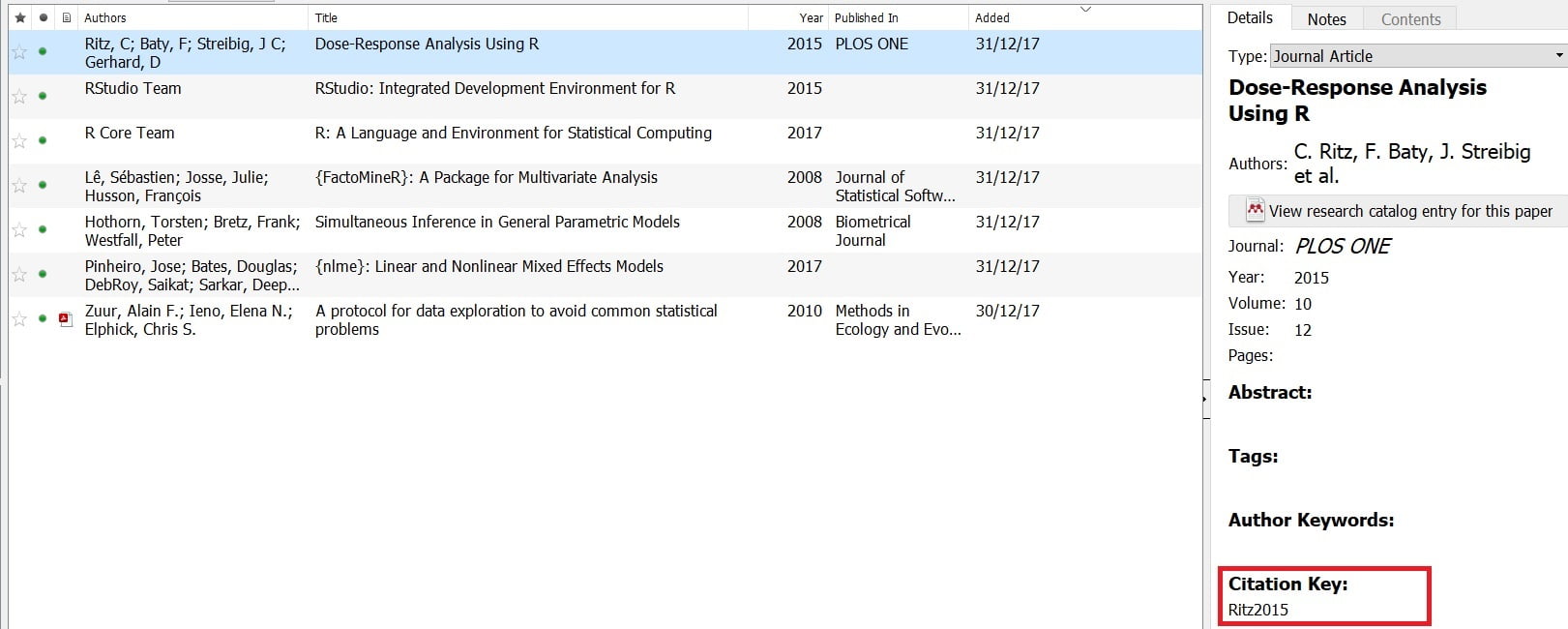
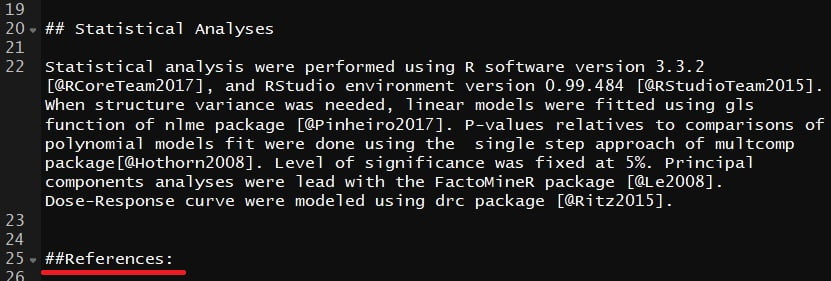
Voici ce que ça donne :

Pour plus de détails, vous pouvez consulter mon article » Comment insérer des références bibliographiques dans un document R markdown«
Excepté l’étape des références bibliographiques, j’utilise les sept autres au quotidien pour organiser mon flux de travail sous R. Dites moi en commentaire ce que vous en pensez. Et si vous avez d’autres habitudes, ou d’autres astuces qui vous aide à organiser votre travail d’analyse ou de développement de code sous R, partagez les avec les autres lecteurs du blog 😉
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photos : 3dman_eu

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
9 réponses
ces fiches d’organisations ont ete tres importantes pour moi et je vous en remercie.
Bonjour. Merci beaucoup pour cet article. C’est très édifiant. Cependant, j’ai un problème d’importation de mes données sous Rstudio. Je veux l’importer par l’environnent (import Database) fichier excel mais il refuse. Veuillez m’aider.
Bonsoir,
essayer de passer par un fichier csv.
Bonne continuation.
Super utile, merci
Utile et Instructif, Merci !
très utile.
merci
Merci
Bonsoir Claire,
Tout d’abord merci pour votre blog et votre investissement.
A propos de l’insertion de bibliographie est il possible d’utiliser Zotero plutôt que Mendeley…
Toute ma biblio depuis des années est stockée dans Zotero et j’ai pas trop envie d’utiliser autre chose… 😉
Honnêtement j’ai fais ce commentaire en mode fainéant …. Je n’ai pas cherché s’il existait l’alternative…
Merci encore !
Philippe
Bonjour Philipe,
une de mes collègues avait essayé et elle m’avait dit que cela fonctionne de la même façon que pour Mendeley. Vous trouverez également des infos sur cet article : https://christopherjunk.netlify.app/blog/2019/02/25/zotero-rmarkdown/
Bonne continuation.