Lorsqu’on évoque le test de Student, il s’agit généralement du test de Student pour échantillons indépendants. Ce test est alors employé pour comparer deux séries de données quantitatives indépendantes, résumées par une moyenne.
Néanmoins, il existe également un test de Student apparié, pour échantillons appariés (paired en anglais), issus de protocoles expérimentaux dans lequel le sujet est sont propre témoin. Par exemple, lors d’expérimentations de type avant / après, ou encore lorsque des mesures sont faites sur différentes régions (bras droit / bras gauche) d’un même sujet. Dans ces situations, il y a, en réalité un seul échantillon, mais deux séries de données.
Deux principaux tests statistiques permettent de prendre en compte cette situation d’échantillons appariés :
Dans cet article, nous allons nous intéresser aux tests de Student et de Wilcoxon appariés.
Imaginons que l’on souhaite évaluer l’effet d’un nouveau régime alimentaire sur la perte de poids chez 20 sujets. Pour cela, on pèse ces 20 sujets avant de débuter le régime alimentaire, puis une seconde fois, à la fin de celui-ci (2 mois plus tard, par exemple).
Les données pourraient être celles-ci :
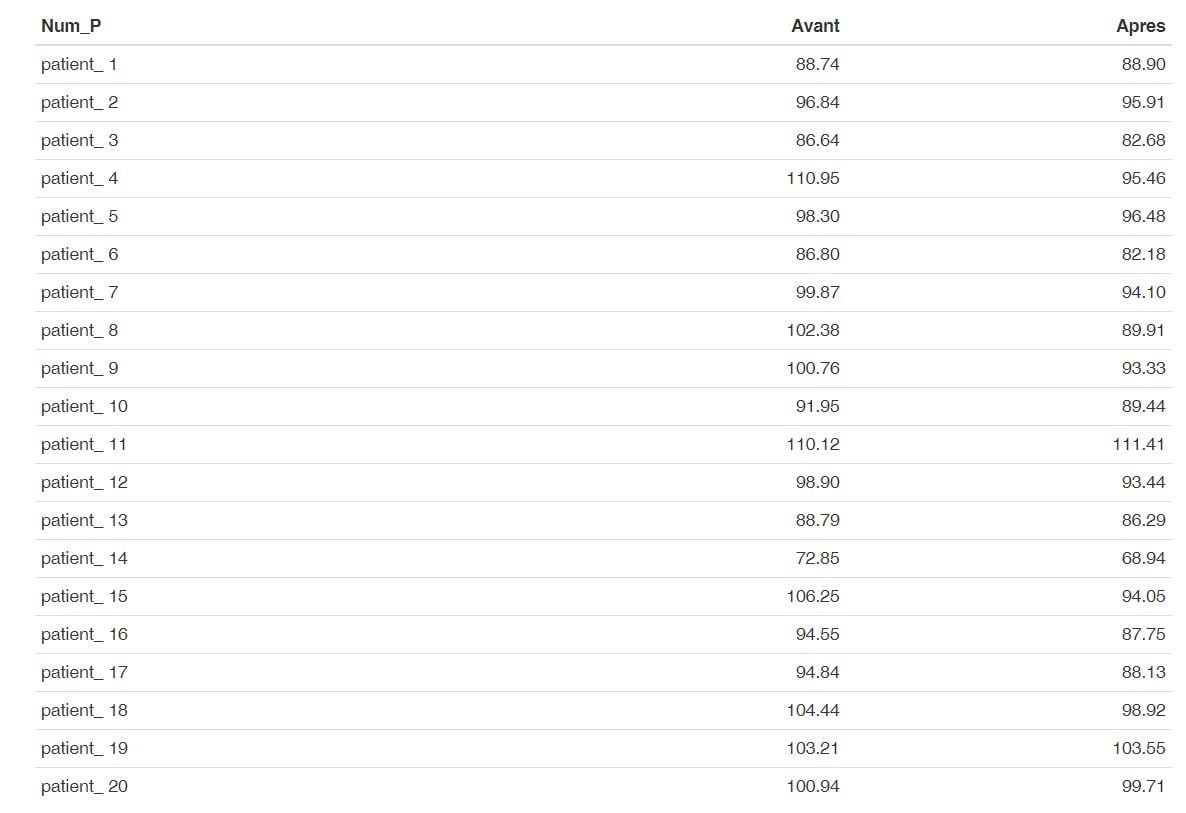
J’ai généré ces données avec le code suivant :
library(knitr)
set.seed(1)
p1 <- round(rnorm(20,95,10),2)
p2 <- round(p1*0.95+rnorm(20,0,5),2)
id= paste("patient_",1:20)
mydf <- data.frame(Num_P=id,Avant=p1,Apres=p2)
mydf library(tidyverse)
mydf_long <- mydf %>%
gather(time, value,-Num_P)
mydf_long$time <- fct_relevel(mydf_long$time, c("Avant", "Apres"))
library(ggplot2)
ggplot(mydf_long,aes(y=value, x=time, group=Num_P))+
geom_point(show.legend = FALSE, size=3, colour="blue")+
geom_line(show.legend = FALSE, size=1, colour="blue")+
theme_bw() 
Le test de Student apparié, va permettre de comparer ces deux séries de données, dont les moyennes sont 96.91 kg avant le régime et 92.03 kg après celui-ci.
mean(mydf$Avant)
## [1] 96.906
mean(mydf$Apres)
## [1] 92.029 Et ainsi de répondre à la question, est-ce que le poids moyen des sujets après le régime est différent du poids moyen de ces même sujets avant le régime ?
La statistique de ce test repose sur le calcul de :
Sa statistique est :
\[t_{n-1} =\frac{\bar{d}}{s_{\bar{d}}}\]
Pour calculer la statistique de ce test, les étapes suivantes doivent être conduites:
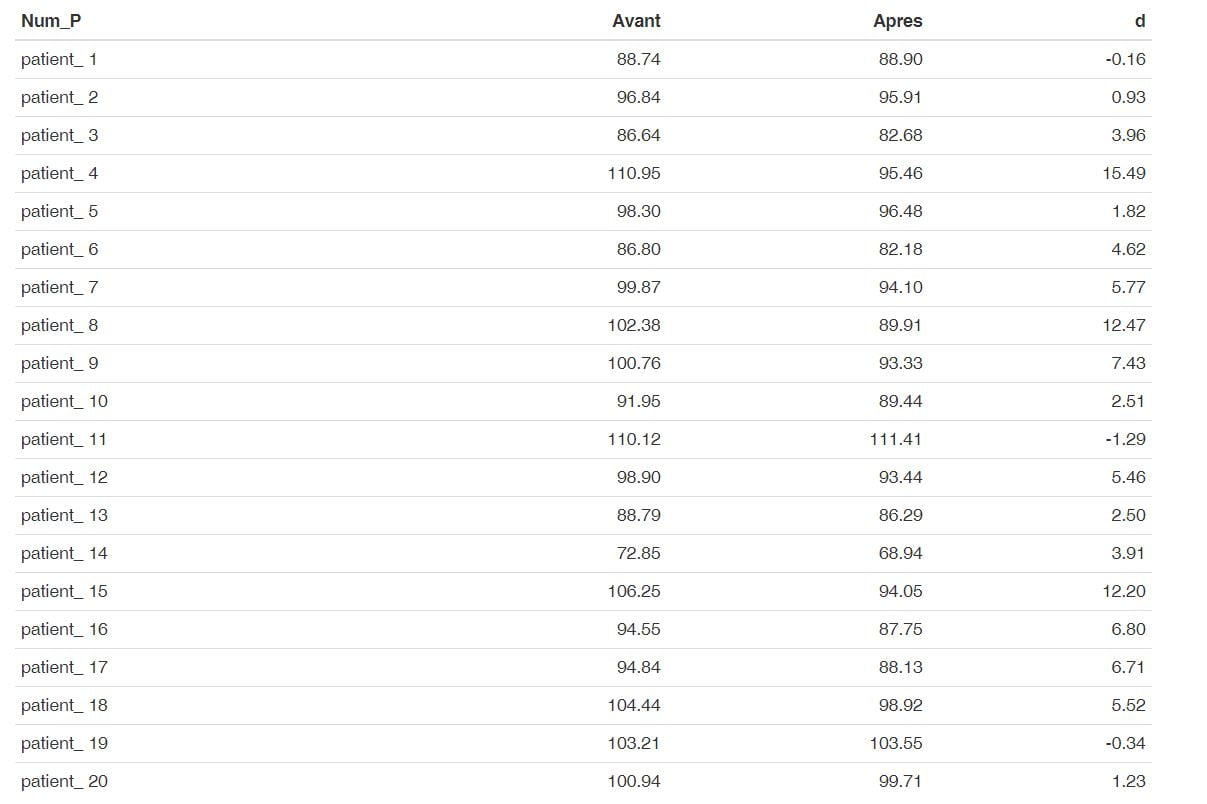
moy_d = mean(mydf$d)
moy_d
## [1] 4.877 var_d = var(mydf$d)
var_d
## [1] 20.05169 sd_moy_d = sd(mydf$d)/sqrt(20)
sd_moy_d
## [1] 1.001291 shapiro.test(mydf$d)
##
## Shapiro-Wilk normality test
##
## data: mydf$d
## W = 0.92696, p-value = 0.1349 
Pour réaliser un test de Student apparié, il suffit de rajouter l’argument paired=TRUE dans la fonction t.test()
t.test(mydf$Avant, mydf$Apres, paired=TRUE)
##
## Paired t-test
##
## data: mydf$Avant and mydf$Apres
## t = 4.8707, df = 19, p-value = 0.0001062
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 2.781273 6.972727
## sample estimates:
## mean of the differences
## 4.877 La p value du test est <0.05, l’hypothèse nulle d’égalité des moyennes est rejetée. Le test de Student apparié met en évidence une différence significative entre les deux moyennes, dans le sens d’une moyenne de poids plus faible après la mise en place du régime.
Comme précédemment, il suffit de rajouter l’argument `paired=TRUE` dans la fonction `wilcox.test()`:
wilcox.test(mydf$Avant, mydf$Apres, paired=TRUE)
##
## Wilcoxon signed rank test
##
## data: mydf$Avant and mydf$Apres
## V = 202, p-value = 4.768e-05
## alternative hypothesis: true location shift is not equal to 0
Comme vous avez pu le voir, il est vraiment très facile de réaliser un test de Student, ou de Wilcocon apparié sous R. Dans un prochain article, je vous parlerai du test de Mac Nemar, qui permet de comparer deux proportions mesurées sur des séries appariées.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

mage par Screamenteagle de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
13 réponses
Merci Claire pour tes riches articles
Un très bon site d’apprentissage
Merci beaucoup Claire.
Tes fiches sont très pratiques.
Merci ! Très claire !
Merci Claire,
j’ai une petite commentaire concernant les condition d’application.
il y a des articles scientifiques publiés dans des journaux de haute valeur scientifique et qui utilise le « t.test » pour comparer des groupes de faible effectif (n=4).
est ce que l’effectif n’est pas exigé pour faire un test paramétrique?
merci encore une fois.
Merci Claire pour cet article! Je viens juste de donner une formation sur le sujet !
Merci Claire pour l’article.
Très bon article, surtout avec des codes R. C’est génial
Merci beaucoup pour cet article. Il a été d’une grande utilité pour moi
Merci beaucoup claire , seulement j’ai du mal à calculer la valeur de « d » c’est a dire y’ a t’il un code pour l’avoir sous R ? Merci
Salut Claire très bon article qui nous éclairer.
Bonjour, merci pour votre article, j’ai une petite question
J’ai 46 patientes,
23 patientes pour chaque bras.
Pour chaque patiente j’ai deux scores, un en pré consultation et un autre en post consultation (données appariés)
• Groupe Expérimental
o Moyenne Pré-Consultation
o Moyenne Post-Consultation
• Groupe Contrôle
o Moyenne Pré-Consultation
o Moyenne Post-Consultation
Quels est la modélisation statistique que je devrais l’utiliser en comparant les deux bras et pré et post consultation à la fois
Je voudrais utiliser logiciel R
Voici ma base fictive de données.
ID Groupe pré-Consultation Post-Consultation
1 1 Groupe Expérimental 49 43
2 2 Groupe Expérimental 53 44
3 3 Groupe Expérimental 71 33
4 4 Groupe Expérimental 56 58
5 5 Groupe Expérimental 56 52
6 6 Groupe Expérimental 72 39
7 7 Groupe Expérimental 60 63
8 8 Groupe Expérimental 42 54
9 9 Groupe Expérimental 48 47
10 10 Groupe Expérimental 51 59
11 11 Groupe Expérimental 67 59
12 12 Groupe Expérimental 59 58
13 13 Groupe Expérimental 59 57
14 14 Groupe Expérimental 56 56
15 15 Groupe Expérimental 49 49
16 16 Groupe Expérimental 73 47
17 17 Groupe Expérimental 60 46
18 18 Groupe Expérimental 35 43
19 19 Groupe Expérimental 62 48
20 20 Groupe Expérimental 50 37
21 21 Groupe Expérimental 44 72
22 22 Groupe Expérimental 53 62
23 23 Groupe Expérimental 45 39
24 24 Groupe Contrôle 51 61
25 25 Groupe Contrôle 50 35
26 26 Groupe Contrôle 63 17
27 27 Groupe Contrôle 54 50
28 28 Groupe Contrôle 58 33
29 29 Groupe Contrôle 55 33
30 30 Groupe Contrôle 55 50
31 31 Groupe Contrôle 69 37
32 32 Groupe Contrôle 53 28
33 33 Groupe Contrôle 70 42
34 34 Groupe Contrôle 40 39
35 35 Groupe Contrôle 61 40
36 36 Groupe Contrôle 56 44
37 37 Groupe Contrôle 57 36
38 38 Groupe Contrôle 59 46
39 39 Groupe Contrôle 50 38
40 40 Groupe Contrôle 52 43
41 41 Groupe Contrôle 45 51
42 42 Groupe Contrôle 44 44
43 43 Groupe Contrôle 58 37
44 44 Groupe Contrôle 59 51
45 45 Groupe Contrôle 56 50
46 46 Groupe Contrôle 64 45
Merci pour votre article !
Il m’a été d’une grande aide et a éclairci tous mes points d’ombre sur le sujet.