La randomisation (qui vient du mot anglais “random” qui veut dire “au hasard” ou “aléatoire” ) est l’affectation aléatoire d’unités expérimentales dans un groupe de traitement.
C’est une approche qui est largement utilisée en recherche clinique, dans le domaine de l’expérimentation animale, ou encore dans la recherche en psychologie.
Le but de la randomisation est d’assurer la comparabilité des différents groupes. Autrement dit, la randomisation permet de constituer des groupes comparables, de patients par exemple, sur des facteurs de confusion potentiels, et ainsi éviter des biais de sélection.
Voici deux exemples pour fixer les idées.
Imaginons que vous voulez tester l’efficacité d’un nouveau médicament dans le traitement de migraine. Deux médecins généralistes libéraux (le Docteur A, et le Docteur B) vous adressent chacun 10 patients. Vous pourriez avoir l’idée de donner un placebo aux patients du Docteur A et le nouveau médicament aux patients du docteur B.

Vous le faites, vous analysez les données et les résultats mettent en évidence que le nouveau traitement est efficace contre la migraine. Mais en regardant les caractéristiques des patients, vous vous rendez compte que les patients du Docteur B sont significativement plus jeunes que les patients du Docteur A. Du coup, l’efficacité que vous avez observé, est elle liée au traitement, à l’âge des patients ou un peu de deux ?
Certains pourraient se dire qu’il suffit d’analyser les données avec un modèle de régression multiple, en ajoutant l’âge du patient comme co-variables. Comme ça l’efficacité du nouveau médicament sera évaluée tout en étant ajusté sur l’âge des patients. D’après mes connaissances,
ce n’est pas suffisant pour contrôler une répartition aussi déséquilibrée. Et puis autre argument : l’âge est un facteur de confusion potentiel classique, il est quasiment toujours collecté. Mais imaginons que les patients du docteur B soient de plus grands consommateurs de café que ceux du docteur A. Et que la consommation de caféine ait tendance à diminuer l’intensité des migraines, mais que cette information n’a pas été collectée. Comment ajuster sur un facteur de confusion dont vous n’avez pas idée , ou un facteur de confusion inconnu ?
La solution aurait consisté à répartir aléatoirement les patients des Docteurs A et B dans les deux groupes de traitement, afin qu’ils aient, en moyenne, les mêmes caractéristiques. Autrement dit, à randomiser les patients.

Un autre exemple dans le domaine de l’expérimentation animale : vous souhaitez comparer le comportement de souris placées dans un labyrinthe, en présence et en l’absence d’un stress sonore par exemple. Vous disposez de 10 souris contenues dans une grande cage. Vous pourriez avoir l’idée de soumettre les cinq premières souris que vous réussissez à attraper, au stress sonore et les cinq autres à une situation sans stress sonore. Mais est ce que les cinq première souris que vous avez réussi à attraper ne sont pas les cinq souris les plus fatiguées ? Est ce que cela ne pourrait pas avoir un impact sur votre étude ? C’est ce qu’on appelle un biais de sélection.
C’est assez simple de créer une liste de randomisation avec R. Je vais vous montrer comment le faire, dans plusieurs situations, avec le package blockrand et sa fonction du même nom.
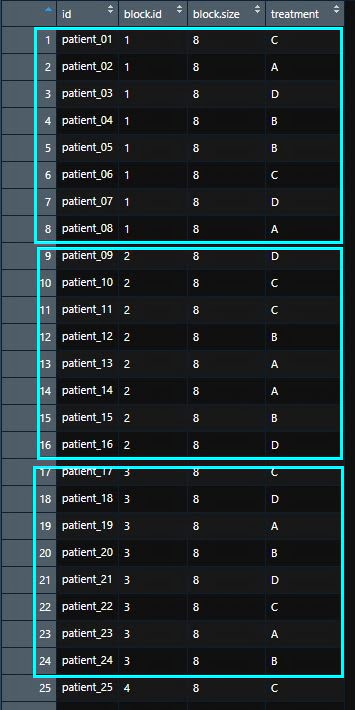
Vous voulez, par exemple, répartir 32 patients aléatoirement dans 4 groupes de traitement (A, B, C ou D). Vous pouvez choisir d’équilibrer la liste tous les quatre patients. Pour cela, vous indiquez `block.sizes = 1`.
library(blockrand)
mylist1 <- blockrand(n=32,
num.levels = 4,
id.prefix='patient_',
block.sizes = 1,
levels=c("A", "B", "C", "D")) 
Vous pouvez aussi choisir d’équilibrer la liste tous les huit patients. Pour cela, il est nécessaire de préciser les tailles de tous les blocs par un vecteur, ici block.sizes = c(2,2,2,2), que vous pouvez remplacer par block.sizes = rep(2,4)
mylist2 <- blockrand(n=32,
num.levels = 4,
id.prefix='patient_',
block.sizes = rep(2,4),
levels=c("A", "B", "C", "D"))
Imaginons à présent que vous participez à un essai thérapeutique multicentrique, comportant 2 sites (2 CHU par exemple). Dans cette situation, vous aurez sans doute besoin de stratifier la liste sur le site.
Pour cela, vous pouvez créer deux listes en utilisant l’argument stratum, puis les regrouper en une seule, comme ceci:
Site1 <- blockrand(n=12,
num.levels = 4,
id.prefix='patient_',
block.prefix='Site1_',
stratum='Site1',
block.sizes = 1,
levels=c("A", "B", "C", "D"))
Site2 <- blockrand(n=12,
num.levels = 4,
id.prefix='patient_',
block.prefix='Site2_',
stratum='Site2',
block.sizes = 1,
levels=c("A", "B", "C", "D"))
mylist3 <- rbind(Site1,Site2) 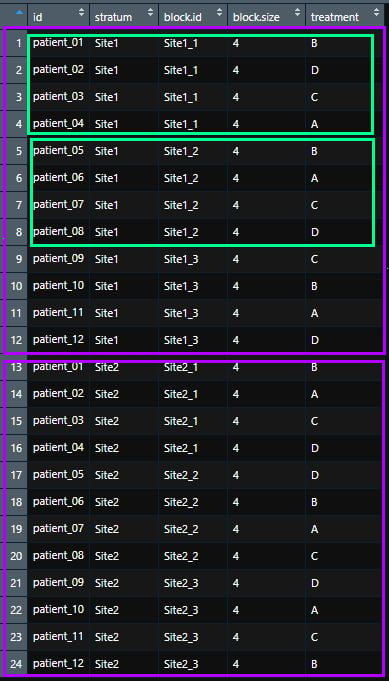
Et pour exporter la liste :
write.csv2(mylist3, "liste_randomisation.csv", row.names = FALSE) Voilà ! Et vous, est ce que vous avez déjà utilisé des listes de randomisation ? Dans quel domaine ? Quel était le schéma de la liste ? Avec quel outil vous l’avez créée ?
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photos :Image par Clker-Free-Vector-Images de Pixabay, mohamed Hassan de Pixabay, Peggy und Marco Lachmann-Anke de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
6 réponses
Bonjour Madame Claire!
j’ai lu votre article et ça m’a plu. Néanmoins j’ai du mal à comprendre la dernière partie. En concerne la stratification, vous avez décidé de la faire sur deux sites. Le nombre patient étant 32, je m’attendais à ce qu’on ait 16 patients par site (stratum). Mais ce que je vois c’est 12 patients par site et c’est les mêmes patients qui sont qui sont utilisés pour le site 1 et 2 si je dois me fier aux id (identifiant).
Bonjour et merci de ce tutoriel. J’ai réussi la manœuvre mais je n’ai pas bien compris. Comment retrouver chaque élément des groupes dans la population initiale. J’ai l’impression que les autres variables ne sont plus visibles.
Je pratique parfois la randomisation dans mes activités de routine d’épidémiologiste dans une agence des NU basée en Afrique. Avant j’utilisais Excel avec la fonction aléa. Je travaille désormais avec R après un DU en régressions obtenu à Bordeaux. C’est surtout pour choisir au hasard des témoins et parfois des cas dans une étude cas-témoin. Je crée une colonne avec les numéros (cbind) et j’en tire au hasard du genre (sample(6985, size=149, replace = FALSE).
Encore mercis de vos cours qui sont à mon chevet jour et nuit et pour lesquels je consacre plus de 10 heures par semaines.
Très bon article. Félicitations pour le travail
Merci beaucoup pour l’explication
Bonjour,
Je souhaitais tester cette fonction pour créer une liste de randomisation et hélas, cela ne fonctionne pas. J’ai essayé avec les exemples de « ?blockrand », mais c’est la même chose…
Merci,
Cordialement,
Julie PAUL
Après plusieurs tentatives, j’ai réussi ! Merci beaucoup pour tous vos articles, ils sont très intéressants.
Julie PAUL