
Dans cet article, je vous propose d’aborder le paradoxe de Simpson. Il s’agit d’un phénomène statistique dans lequel la relation entre deux variables peut être renversée, selon que l’on analyse les données en globalité ou par sous-groupes.
C’est un phénomène qui peut laisser un peu perplexe la première fois qu’on le rencontre. Mais au-delà de l’étrangeté du phénomène, c’est surtout un piège de l’analyse de données qui peut nous conduire à conclure de manière erronée.
C’est donc important de le connaitre, de le comprendre, et de savoir l’identifier.
Dans cet article, je vous propose d’explorer deux situations dans lesquelles le paradoxe de Simpson peut se rencontrer.
Supposons que nous voulions comparer le taux de réussite de deux programmes de formation différents. Nous collectons des données auprès de 200 participants, et nous constatons que le taux de réussite est de 60% pour le premier programme, et de 50% pour le second.
# Charger le package dplyr
library(tidyverse)
# Créer les données
program <- c(rep("Programme 1", 100), rep("Programme 2", 100))
examen_entree <- c(rep("Eleve", 80), rep("Faible", 20), rep("Eleve", 20), rep("Faible", 80))
reussite = c(rep(1, 60), rep(0, 40), rep(1, 16), rep(0, 4), rep(1, 34), rep(0, 46))
mydata <- data.frame(program,examen_entree,reussite)
# Calculer les taux de réussite globaux
mydata %>%
group_by(program) %>%
summarise(taux_reussite = mean(reussite) * 100)
## # A tibble: 2 × 2
## program taux_reussite
## <chr> <dbl>
## 1 Programme 1 60
## 2 Programme 2 50 Nous pourrions donc être tentés de penser que le premier programme est globalement meilleur puisqu’il a un taux de réussite plus élevé.
Cependant, en examinant de plus près les données, nous apercevons qu’il existe deux groupes d’élèves : ceux ayant eu une note élevée à l’examen d’entrée et ceux ayant eu une note faible. On décide de regarder les taux de réussite pour chacun de ces sous-groupes.
Et là, patatra….la tendance s’inverse, c’est maintenant le programme 2 qui a un meilleur taux de réussite : 80% contre 75% dans le groupe des étudiants ayant eu une note élevée, et 42.5% contre 0% pour l’autre groupe !
# Calculer les taux de réussite par sous-groupe
mydata %>%
group_by(examen_entree, program) %>%
summarize(taux_reussite = mean(reussite) * 100)
## # A tibble: 4 × 3
## # Groups: examen_entree [2]
## examen_entree program taux_reussite
## <chr> <chr> <dbl>
## 1 Eleve Programme 1 75
## 2 Eleve Programme 2 80
## 3 Faible Programme 1 0
## 4 Faible Programme 2 42.5 Étonnant, non ?
WTF diraient certains !
Eh bien Welcome dans le monde du paradoxe de Simpson !
Le paradoxe de Simpson peut aussi survenir lorsqu’on s’intéresse à la relation entre deux variables quantitatives (de manière générale, il peut survenir dans n’importe quel modèle de régression linéaire). Pour illustrer cela, employons les données iris (automatiquement présentes dans R).
Si nous analysons la relation entre les variables Petal.Width et Sepal.Width pour l’ensemble des fleurs du jeu de données iris, nous allons mettre en évidence une relation négative :
library(ggplot2)
library(ggpubr)
g1 <- ggplot(iris, aes(y=Petal.Width, x=Sepal.Width))+
geom_point()+
geom_smooth(method="lm", colour="magenta")+
ggtitle("Toute espèce confondue")+
stat_regline_equation()
g1 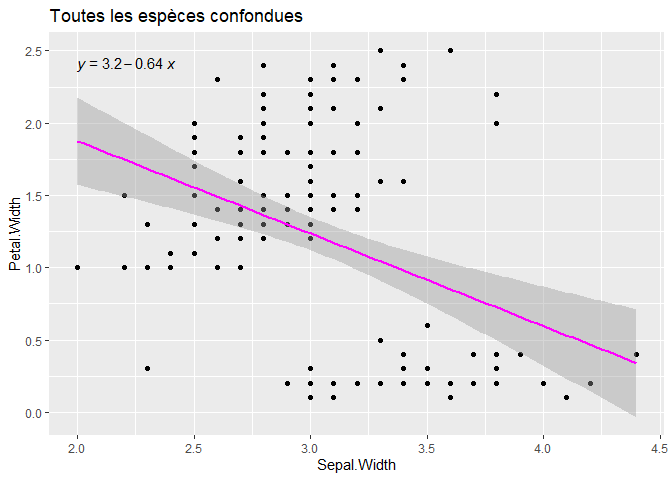
OK, elle n’est pas folichonne, mais c’est la meilleure droite de régression !
Considérons, à présent, cette même relation, mais par espèce. Nous allons mettre en évidence trois relations, mais positives cette fois :
ggplot(iris, aes(y=Petal.Width, x=Sepal.Width, color=Species))+
geom_point()+
geom_smooth(method="lm")+
ggtitle("Par espèce")+
stat_regline_equation()
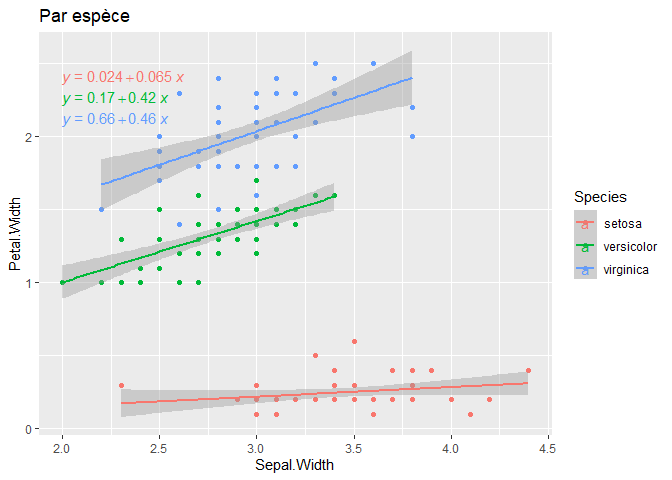
Hé oui !!
Non c’est pas un tour de magie, c’est un tour du facteur de confusion !
Il s’agit d’une variable qui est liée à la fois à la réponse (la réussite dans la première situation, la largeur des pétales dans la seconde), et la variable explicative (le programme de formation dans la première situation, et la largeur du sépale dans la seconde situation).
Regardons de plus près la première situation. La note obtenue à l’examen d’entrée est bien un facteur de confusion, car elle est liée à la réussite : les élèves ayant eu une note élevée à l’examen d’entrée ont un taux de réussite plus élevé (76%) que ceux ayant eu une note faible à l’examen d’entrée (34%).
mydata %>%
group_by(examen_entree) %>%
summarize(taux_reussite = mean(reussite) * 100)
## # A tibble: 2 × 2
## examen_entree taux_reussite
## <chr> <dbl>
## 1 Eleve 76
## 2 Faible 34 Et en même temps, la note obtenue à l’examen d’entrée est liée au programme car 80% des élèves ayant eu une note élevée à l’examen d’entrée ont suivi le programme 1, contre seulement 20% pour ceux ayant eu une note faibles à l’examen d’entrée.
mydata %>%
group_by(examen_entree, program) %>%
count()
## # A tibble: 4 × 3
## # Groups: examen_entree, program [4]
## examen_entree program n
## <chr> <chr> <int>
## 1 Eleve Programme 1 80
## 2 Eleve Programme 2 20
## 3 Faible Programme 1 20
## 4 Faible Programme 2 80 Ce sont donc les meilleurs élèves qui ont majoritairement suivi le premier programme. Ainsi, quand on considère toutes les données ensemble, ils tirent la tendance pour un meilleur taux de réussite du programme 1. Mais si on regarde à niveau constant de la note de l’examen d’entrée, le meilleur programme de formation est le programme 2 !
Dans le cas des données iris, nous pouvons voir que les trois espèces ont des caractéristiques morphologiques différentes, en termes de largeur de pétale et de largeur de sépale. Dit autrement, l’espèce affecte ses deux variables ; c’est donc un facteur de confusion de la relation entre la largeur du pétale et la largeur du sépale.
POur s’en convaincre, nous pouvons calculer l’effect size obtenu après une anova sur la largeur du pétale ; il est de 93% (cela signifie que 93% de la variation est expliqué par l’espèce). L’effet size est de 40% pour la largeur du sépale.
iris.aov1 <- aov(Petal.Width~Species, data=iris)
library(parameters)
parameters(iris.aov1,
effectsize_type = "eta",
type=2)
## Parameter | Sum_Squares | df | Mean_Square | F | p | Eta2
## --------------------------------------------------------------------
## Species | 80.41 | 2 | 40.21 | 960.01 | < .001 | 0.93
## Residuals | 6.16 | 147 | 0.04 | | |
##
## Anova Table (Type 2 tests)
iris.aov2 <- aov(Sepal.Width~Species, data=iris)
library(parameters)
parameters(iris.aov2,
effectsize_type = "eta",
type=2)
## Parameter | Sum_Squares | df | Mean_Square | F | p | Eta2
## -------------------------------------------------------------------
## Species | 11.34 | 2 | 5.67 | 49.16 | < .001 | 0.40
## Residuals | 16.96 | 147 | 0.12 | | |
##
## Anova Table (Type 2 tests) La relation entre la largeur du pétale et celle du sépale est donc sous-tendue par des modèles distincts pour chaque espèce, et ici de tendance croissante.
Mais en combinant les données de toutes les espèces d’iris, les modèles individuels propres à chaque espèce se mélangent et provoquent l’apparition d’une nouvelle tendance qui est, ici, inversée. Le rationnel est moins évident , mais le graphique est très parlant, je trouve.
Ces deux exemples nous montrent qu’il est essentiel de prendre en compte les facteurs de confusion dans notre analyse de données, sous peine de conclure complètement à côté de la plaque !
Mais en pratique, il n’est pas toujours facile d’identifier ces facteurs de confusion, certains sont évidents, et d’autres nécessitent un jugement d’expert.
Collaborer avec un expert métier est primordial pour ne pas passer à côté d’un facteur de confusion
Lorsqu’on analyse des données, la première chose à faire c’est toujours de les visualiser ! Mais prendre l’habitude de les visualiser globalement et par sous groupe, c’est encore mieux parce que ça peut vraiment nous permettre de mieux les comprendre, et de mettre en évidence de potentiels facteurs de confusion.
Pour les visualiser en sous groupe, l’utilisation des couches facet_wrap() et facet_grid() peut se révéler ultra-précieuse. Pour le premier exemple, nous aurions pu, par exemple, faire ce type de graphique :
.
library(GGally)
ggplot(mydata,aes(as.factor(program), fill=as.factor(reussiteF), by=as.factor(program)))+
geom_bar(position="fill", colour="black")+
scale_fill_manual(values=c("#EB2F2CCC", "#34EB68D3"))+
geom_text(aes(by=as.factor(program)), stat = "prop", position = position_fill(.5))+
facet_wrap(~examen_entree)+
labs(fill="Reussite") 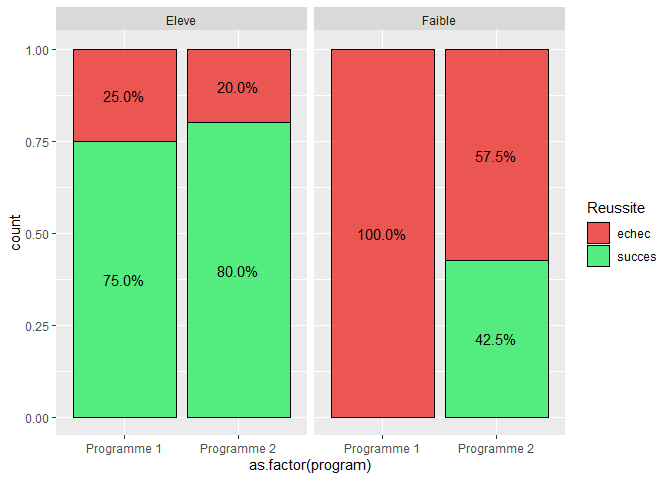
Pour le second exemple :
ggplot(iris, aes(y=Petal.Width, x=Sepal.Width, color=Species))+
geom_point()+
geom_smooth(method="lm")+
ggtitle("Par espèce")+
facet_wrap(~Species) 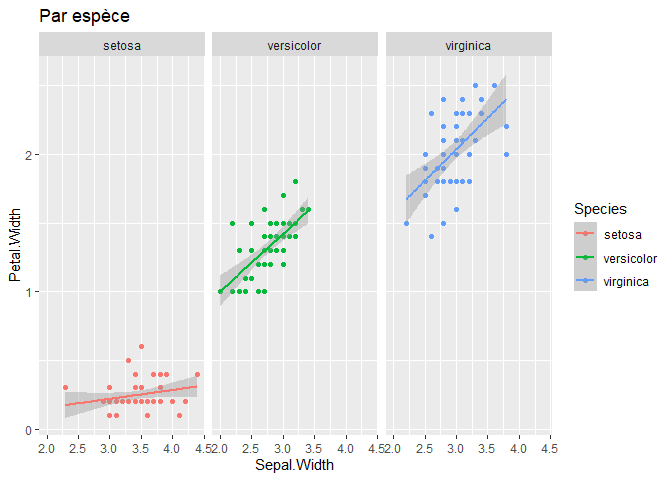
Si graphiquement, vous identifiez un facteur de confusion ( que vous mettez en evidence un effet groupe), il faudra absolument le prendre en compte dans l’analyse c’est-à-dire inclure un effet groupe, et commencer par modéliser une interaction.
Par exemple, dans la seconde situation, si ce que nous souhaitons faire c’est caractériser la relation entre les variables Petal.Width et Sepal.Width, nous allons :
modéliser la relation en incluant l’espèce avec un terme d’interaction entre Sepal.Width et Species afin de spécifier une droite distincte par espèce
comparer l’ajustement de ce modèle avec un modèle plus simple qui spécifie 3 droites, mais de pente identique
Sélectionner le meilleur modèle pour caractériser la ou les relations entre Petal . Width et Sepal.Width (celui qui est le plus adapté aux données)
Étape 1 : modélisation de trois droites différentes grâce au terme d’interaction Sepal.Width : Species
# modélisation de 3 droites différente grâce au terme d'interaction
lm1 <- lm(Petal.Width~Sepal.Width + Species + Sepal.Width:Species , data=iris)
library(parameters)
parameters(lm1)
## Parameter | Coefficient | SE | 95% CI | t(144) | p
## -----------------------------------------------------------------------------------------
## (Intercept) | 0.02 | 0.22 | [-0.42, 0.46] | 0.11 | 0.914
## Sepal Width | 0.06 | 0.06 | [-0.06, 0.19] | 1.00 | 0.317
## Species [versicolor] | 0.14 | 0.31 | [-0.47, 0.76] | 0.46 | 0.647
## Species [virginica] | 0.64 | 0.32 | [ 0.01, 1.27] | 2.02 | 0.046
## Sepal Width × Species [versicolor] | 0.35 | 0.10 | [ 0.15, 0.55] | 3.50 | < .001
## Sepal Width × Species [virginica] | 0.39 | 0.10 | [ 0.20, 0.59] | 3.95 | < .001
ggplot(iris, aes(y=Petal.Width, x=Sepal.Width, color=Species))+
geom_point()+
geom_smooth(method="lm")+
ggtitle("Par espèce") 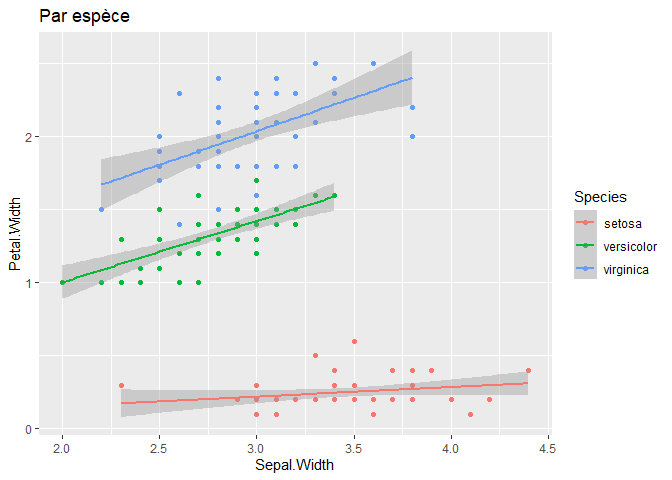
Étape 2 : modélisation de 3 droites de pentes identiques.
Il s’agit de vérifier si la modélisation de 3 droites de pentes identiques n’est pas aussi bien. Pour cela, on peut ajuster un modèle avec l’effet Species mais sans terme d’interaction, comme ceci :
# avec une pente identique
lm2 <- lm(Petal.Width~Sepal.Width+Species, data=iris)
parameters(lm2)
## Parameter | Coefficient | SE | 95% CI | t(146) | p
## ----------------------------------------------------------------------------
## (Intercept) | -0.73 | 0.15 | [-1.03, -0.42] | -4.74 | < .001
## Sepal Width | 0.28 | 0.04 | [ 0.20, 0.37] | 6.44 | < .001
## Species [versicolor] | 1.27 | 0.05 | [ 1.17, 1.36] | 27.31 | < .001
## Species [virginica] | 1.91 | 0.04 | [ 1.83, 1.99] | 46.13 | < .001
library(moderndive) # pour geom_parallel_slopes()
ggplot(iris, aes(y=Petal.Width, x=Sepal.Width, color=Species))+
geom_point()+
geom_parallel_slopes() 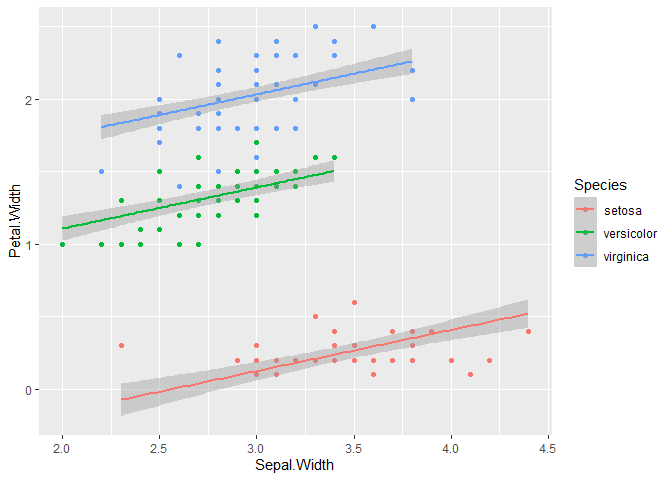
Pour savoir si l’ajustement de ce second modèle aux données est aussi satisfaisant que le premier modèle, plus complexe, nous pouvons comparer leur critère d’Akaiké (AIC) : plus la valeur est faible, meilleur est le modèle.
library(performance)
compare_performance(lm1, lm2)
## # Comparison of Model Performance Indices
##
## Name | Model | AIC (weights) | AICc (weights) | BIC (weights) | R2 | R2 (adj.) | RMSE | Sigma
## -------------------------------------------------------------------------------------------------
## lm1 | lm | -96.2 (>.999) | -95.4 (0.999) | -75.1 (0.991) | 0.951 | 0.950 | 0.168 | 0.171
## lm2 | lm | -80.8 (<.001) | -80.4 (<.001) | -65.8 (0.009) | 0.945 | 0.943 | 0.179 | 0.181 Ici le meilleur modèle est le modèle 1, avec 3 droites différentes. Ainsi, on caractérisera les relations, de façon différente, pour chaque espèce.
Pour obtenir facilement une estimation des pentes et de leur intervalle de confiance à 95%, nous pouvons employer les commandes suivantes :
library(emmeans)
emtrends(lm1, pairwise ~ Species, var = "Sepal.Width")$emtrends
## Species Sepal.Width.trend SE df lower.CL upper.CL
## setosa 0.0647 0.0645 144 -0.0627 0.192
## versicolor 0.4184 0.0779 144 0.2645 0.572
## virginica 0.4579 0.0758 144 0.3082 0.608
##
## Confidence level used: 0.95 À présent, par curiosité, je vous propose d’ajuster le modèle de régression simple, c’est-à-dire, sans prise en compte du groupe :
# modèle sans le groupe : 1 seul droite
lm3 <- lm(Petal.Width~Sepal.Width, data=iris)
parameters(lm3)
## Parameter | Coefficient | SE | 95% CI | t(148) | p
## -------------------------------------------------------------------
## (Intercept) | 3.16 | 0.41 | [ 2.34, 3.97] | 7.64 | < .001
## Sepal Width | -0.64 | 0.13 | [-0.90, -0.38] | -4.79 | < .001
ggplot(iris, aes(y=Petal.Width, x=Sepal.Width))+
geom_point()+
geom_smooth(method="lm")+
ggtitle("Par espèce") compare_performance(lm1, lm2, lm3)
## # Comparison of Model Performance Indices
##
## Name | Model | AIC (weights) | AICc (weights) | BIC (weights) | R2 | R2 (adj.) | RMSE | Sigma
## -------------------------------------------------------------------------------------------------
## lm1 | lm | -96.2 (>.999) | -95.4 (0.999) | -75.1 (0.991) | 0.951 | 0.950 | 0.168 | 0.171
## lm2 | lm | -80.8 (<.001) | -80.4 (<.001) | -65.8 (0.009) | 0.945 | 0.943 | 0.179 | 0.181
## lm3 | lm | 327.6 (<.001) | 327.8 (<.001) | 336.7 (<.001) | 0.134 | 0.128 | 0.707 | 0.712 La comparaison des performances nous montre bien que ce modèle simple n’est absolument pas adapté aux données !
Alors, qu’est-ce que ça vous inspire ce paradoxe de Simpson ?
Dans tous les cas, j’espère que cet article vous permettra de le comprendre et de vous permettre de mieux analyser vos données, en ne tombant pas dans ce piège !!
En complément, je vous recommande la vidéo de ScienceEtonnante, sur ce sujet :
C’est possible en faisant un don sur la page Tipeee du blog 

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
9 réponses
Merci, très instructif !
Je suis interessse par ce Blog de Statistique avec R
Merci Claire de toute vos efforts Pour nous mettre à jour. Vraiment,je suis fier de vous
Bien connu dans les plans d’expériences, la traduction des facteurs de confusion par les fonctions attachées à ggplot est réellement un plus !
Merci pour cela !
En économétrie, on appelle cela le biais de variables omises. Il se manifeste lorsqu’une variable omise (qui fait donc partie du terme d’erreur et qui affecte la variable dépendante) est corrélée avec l’une ou l’autre des variables explicatives de la régression. Ainsi les aptitudes personnelles peuvent à la fois influencer le niveau de scolarité et le revenu de l’individu, ce qui fait qu’on a tendance à surestimer l’impact du niveau de scolarité sur le revenu de travail de l’individu.
Problème: comment bien contrôler pour les aptitudes personnelles ? On n’a pas toujours une variable de la sorte dans notre base de données…Idée: choisir une variable (un instrument) qui affecte le niveau de scolarité mais pas le niveau de revenu de travail (e.g. frais de scolarité,…).
Bonjour Bernard,
Merci pour cet exemple complémentaire, dans un tout autre domaine. Je suis certaine que cela aidera des lectrices et lecteurs à encore mieux appréhender ce phénomène.
Bien à vous.
Merci beaucoup pour cet article. Comme toujours, tes articles sont très intéressants et utiles. Je vais analyser mes données de manière beaucoup plus approfondie à l’avenir.
Bonjour Claire,
Merci beaucoup pour votre article ! C’est très instructif.
Bonjour Claire,
Merci pour cet article.
Je vais l’appliquer systématiquement beaucoup plus maintenant lors des analyses.