Comme je l’expliquais dans l’article d’introduction à la puissance statistique, cette notion est généralement liée à la problématique du calcul du nombre d’unités expérimentales, ou nombre de sujets nécessaires. En effet, dans de nombreux domaines d’étude, notamment en recherche clinique ou en expérimentation animale, il n’est ni éthiquement, ni financièrement, acceptable de gâcher les unités expérimentales.
Pour tirer pleinement profit de cet article, je vous recommande de consulter, au préalable, les deux articles suivants :
En pratique, on rencontre deux situations. Dans la première, le nombre maximal d’unités expérimentales est connu à l’avance, car limité par une contrainte financière, ou logistique. Dans ce cas-là, on va chercher à évaluer la puissance théorique du test statistique que l’on souhaite employer, compte tenu de ce nombre limité d’unités expérimentales, et des autres paramètres qui l’influence. Dans le cadre d’une comparaison de deux moyennes il s’agit de :
Dans la seconde situation, on cherche, au contraire, à évaluer le nombre d’unités expérimentales qu’il est nécessaire d’inclure, compte tenu des paramètres cités précédemment (delta, sd, alpha), mais aussi surtout en fixant une puissance théorique. Autrement dit, en fixant un niveau de probabilité que le test soit significatif. Cette puissance est généralement fixée entre 80 et 90%.
Le package `stat` (chargé par défaut à chaque ouverture de session – vous n’avez donc pas besoin de le charger spécifiquement) contient trois fonctions dédiées au calcul de puissance et au calcul du nombre de sujets nécessaires :
Si les trois fonctions ci-dessus ne couvrent pas votre besoin, je vous recommande de consulter le package pwr qui contient des fonctions pour les principaux tests d’hypothèse. Voici la liste :
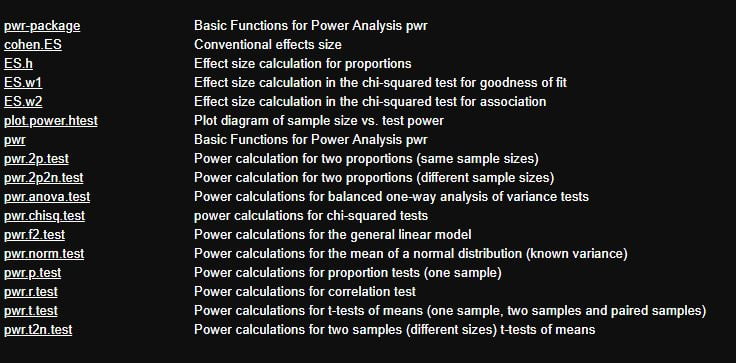
Ce package utilise la notion d’effect size
Vous trouverez la vignette (mode d’emploi de ce package ici ).
Il existe aussi de nombreux packages, disponibles sur CRAN, dédiées à l’analyse de puissance et au calcul du nombre de sujets nécessaires :

Et encore :

Imaginons qu’une expérimentation ait pour but d’évaluer l’efficacité d’un traitement dans la baisse de la pression artérielle. Pour cela, des patients sont randomisés dans un groupe placebo et dans un groupe de traitement. Les paramètres attendus sont :
Pour réaliser ce calcul, nous allons utiliser la fonction power.t.test().
Pour plus de détails sur l’utilisation de cette fonction, vous pouvez consulter l’aide :
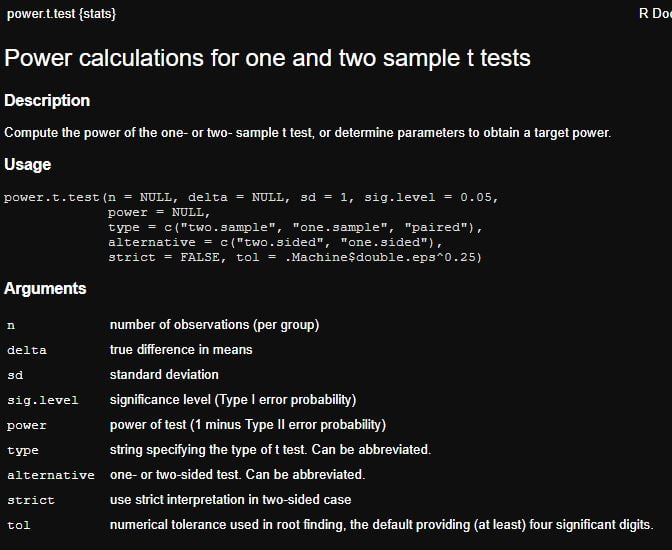
Il suffit alors d’entrer en argument :
La fonction power.t.test calcule le paramètre manquant, ici la puissance :
power.t.test(20,delta=5,sd=10,sig.level=0.05)
##
## Two-sample t test power calculation
##
## n = 20
## delta = 5
## sd = 10
## sig.level = 0.05
## power = 0.3377084
## alternative = two.sided
##
## NOTE: n is number in *each* group Le calcul de puissance nous indique que la probabilité de mettre en évidence une différence significative entre les deux moyennes, en employant un test t bilatéral, est théoriquement de 34%. C’est trop peu, pour envisager l’expérimentation tel quel.
Remarque : Cet exemple est tiré du livre *ample Size Table for clinical Studies (3ème édition) de David Machin et al.
Imaginons à présent, que l’on souhaite, toujours avec le même exemple, calculer le nombre de sujets nécessaires pour atteindre une puissance de 80%.
Il suffit alors d’indiquer la puissance désirée et de conserver les autres paramètres (à l’exception de n, évidemment) :
power.t.test(power=0.8,delta=5,sd=10,sig.level=0.05)
##
## Two-sample t test power calculation
##
## n = 63.76576
## delta = 5
## sd = 10
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group Le résultat du calcul montre que 64 patients dans chaque groupe seraient nécessaires pour atteindre une probabilité de 80% de mettre en évidence une différence statistiquement significative entre les deux moyennes si :
Pour atteindre 90% de puissance, il serait nécessaire d’inclure 85 patients dans chaque groupe :
power.t.test(power=0.9,delta=5,sd=10,sig.level=0.05)
##
## Two-sample t test power calculation
##
## n = 85.03129
## delta = 5
## sd = 10
## sig.level = 0.05
## power = 0.9
## alternative = two.sided
##
## NOTE: n is number in *each* group Si le calcul de puissance vous intéresse, je vous recommande l’excellent livre « Sample Size Table for clinical Studies (3ème édition) de David Machin et al » :

Et vous, quelles fonctions ou quels packages utilisez-vous pour réaliser vos calculs de puissance et de nombre de sujets nécessaires ? Indiquez-les moi en commentaire.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photo : par OpenClipart-Vectors de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
9 réponses
Bonjour, Claire.
Merci pour l’article.
Dans l’exemple, sur quelle base le sd a t-il été choisi?
Plus généralement, dans le cas d’utilisation de power.t.test(), sur quelle base choisi t-on le sd?
Merci
Coliasso
Bonjour,
en principe le sd est choisi sur la base d’une connaissance préalable, soit à partir de la littérature, soit à partir d’une observation faite sur une expérience pilote.
Bonne continuation
bravo c’est interessant cet article
Merci, c’est une bonne synthèse bien précise ! Comment faire avec 3 groupes qui auraient des effectifs différents ?
Bonjour,
peut être aller voir du coté de la fonction power.anova.test, ou du coté du package pwr.
Bonne continuation.
Bonjour Claire,
Merci pour cet intéressant article, je cherchais à évaluer le nombre de sujet nécessaire en y incluant aussi la prévalence. J’ai regardé la littérature sans succès.
Merci d’avance pour tes éclaircissements
Cordialement
Sidy
Bonjour,
Je souhaite comparer l’effet d’un traitement sur 2 populations avec comme critere de jugement une variable quanti discrete (type echelle EVA douleur)
Comment calculer l’effectif dans ce cas la ?
Help !!!
Merci
J
Bonjour Claire
Est ce que l’on calcule de la même façon le nombre de sujets nécessaires avec un Student apparié qu’avec un Student indépendant ?
Merc
Marilyn
Bonjour,
Le calcul est différent. Dans le cadre du test de student apparié, c’est la variance des différences entre les paires qui est employé, alors que dans le test de Student pour échantillon indépendant c’est la variance des données observées dans les 2 groupes qui est employée.
Bonne continuation