La problématique de la puissance statistique est généralement liée à celle du calcul du nombre d’unités expérimentales. Ce calcul du nombre d’unités expérimentales (patients, animaux, plantes, etc..) est une question centrale en recherche clinique ou en expérimentation animale, mais aussi dans de nombreux autres domaines d’études. En effet, l’inclusion d’un trop grand nombre, ou au contraire d’un nombre insuffisant est problématique, à minima financièrement, mais aussi, souvent, éthiquement parlant. C’est particulièrement le cas lorsque l’unité expérimentale est sacrifiée (une souris par exemple) à la fin de l’expérimentation. Mais aussi, par exemple, lorsqu’on soumet, lors de son évaluation, plus de malades que nécessaires à un traitement qui se révèle être non efficace.
Le terme “nombre nécessaire” signifie, en réalité, “nombre nécessaire pour atteindre une certaine puissance de test” ; celle-ci est généralement fixée entre 80 et 90%.
Pour bien comprendre cette notion de puissance de test, quelques rappels sont nécessaires.
Les tests d’hypothèse classiques qui sont des tests de supériorité (il existe aussi des tests d’équivalence) s’appuient sur deux hypothèses :
Par exemple, lorsqu’on compare deux moyennes, en utilisant un test t de Student, ces hypothèses sont :
\[H_{0} : m_{A} = m_{B}\]
\[H_{1} : m_A \neq m_{B} \;(\;\text{hypothèse bilatérale})\]
Ces hypothèses peuvent être ré-écrites sous la forme :
\[H_{0} : m_{A} – m_{B} = 0\]
\[H_{1} : m_A – m_{B} \neq 0 \;(\;\text{hypothèse bilatérale}) \]
La statistique du test t est une différence standardisée, elle peut s’écrire :
\[T_{n_A+n_B-2} = \frac{d}{s_{d}}\]
En détaillant les éléments la statistique T est égale à :
\[T_{n_A+n_B-2} = \frac{m_{A} – m_{B}}{\sqrt{s^2 (\frac{1}{n_A}+\frac{1}{n_B})}}\]
Ou s² est la variance poolée :
\[s^2 = \frac{(n_{A}-1)s_{A}^2\;+(n_{B}-1)s_{B}^2}{(n_{A} + n_{B} -2)}\]
Cette statistique suit une distribution de Student à n_A + n_B -2 degrés de libertés.
Sous l’hypothèse H0, cette distribution est centrée sur 0 ; comme ceci par exemple, avec 98 degrés de liberté :

Cela signifie que, même si en réalité les deux moyennes ne sont pas différentes (cad que leur différence standardisée =0), en fonction de l’échantillonnage des unités expérimentales dans les traitements A et B, la statistique T peut prendre différentes valeurs. Mais que dans la grande majorité des cas, ces valeurs ne sont pas trop éloignées de 0, et qu’en moyenne, elles sont égales à 0.
Sous l’hypothèse H1, la distribution de la statistique T est centrée sur une autre valeur ( Delta_std), qui est la vraie différence standardisée entre les deux traitements (celle des populations), 3 par exemple :
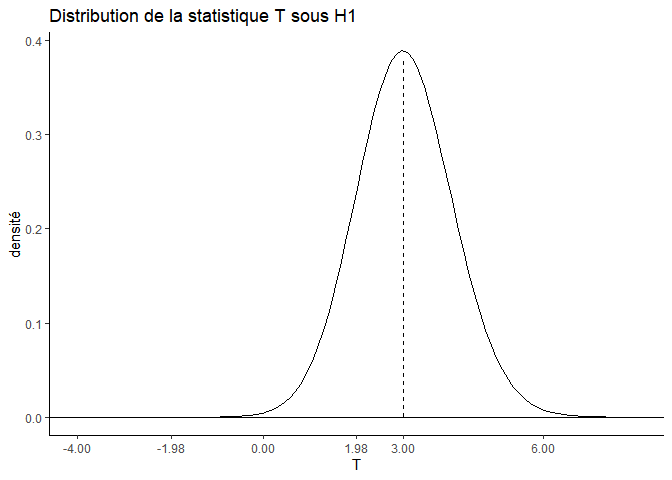
Cela signifie que, même si en réalité les deux moyennes sont différentes (cad leur différence standardisée = Delta_std), en fonction de l’échantillonnage des unités expérimentales dans les traitements A et B, la statistique T peut prendre des valeurs différentes. Mais que dans la grande majorité des cas ces valeurs ne sont pas trop éloignées de Delta_std, et qu’en moyenne, elles sont égales à Delta_std.
Le principe du test statistique est de rejeter H0 (l’hypothèse selon laquelle il ne se passe rien) si la statistique T dépasse un certain seuil. Communément, on accepte un risque de se tromper de 5% (c’est le risque alpha).
Lorsque l’on est dans le cadre d’une hypothèse bilatérale, il existe alors deux seuils, un à droite et un à gauche. Le seuil à droite correspond à la valeur de T (sous l’hypothèse H0) au-delà de laquelle moins de alpha/2 soit 2.5% des statistiques T se trouvent. Il est est de même, de façon symétrique à gauche.
Autrement dit, même si les moyennes ne sont pas différentes (leur différence standardisée =0), la statistique T peut prendre des valeurs extrêmes, mais on fixe une limite, au-delà de laquelle on conclura quand même à la différence. En théorie, seules 5% des valeurs de T dépassent cette limite, on prend donc un risque de 5% de se tromper.
Ces seuils peuvent être calculés avec la fonction qt(), qui prend en argument:
qt(p=0.975, df=98)
## [1] 1.984467
qt(p=0.025, df=98)
## [1] -1.984467 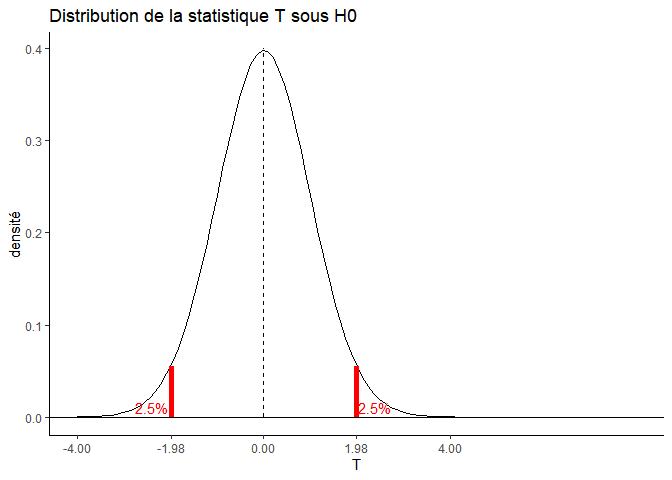
Si on superpose les courbes des distributions sous H0 et H1, on peut alors plus facilement visualiser ce que représente la puissance du test.
D’un point de vu « mathématique » il s’agit de l‘aire sous la courbe de distribution de la statistique T sous H_1 au-delà du seuil fixé par le risque alph

D’un point de vu statistique, la puissance du test est la probabilité de rejeter H0 (parce que la statistique du test est au-delà du seuil fixé par le risque alpha) si H1 est vraie (puisqu’on regarde la distribution de la statistique du test sous H1).
D’un point de vu plus pragmatique, cela signifie que, si l’on répétait l’expérimentation 100 fois, en échantillonnant à chaque fois des unités expérimentales dans les traitements A et B, alors en théorie la statistique T serait au delà du seuil fixé par le risque alpha (autrement dit le test serait significatif), dans 80 des cas.
La puissance statistique c’est donc la probabilité théorique, si la différence standardisée est égale à Delta_std, que le test T soit significatif.
Remarque : L’aire sous la courbe en deçà du seuil est appelé risque de seconde espèce, beta. La puissance est donc égale à 1-beta.
Si la différence entre les moyennes augmente, et que tous les autres paramètres restent constants, alors T augmente :
d=3
s2=5
nA=nB=10
T = d/sqrt(s2*(1/nA+1/nB))
T
## [1] 3 d=4
s2=5
nA=nB=10
T = d/sqrt(s2*(1/nA+1/nB))
T
## [1] 4 Et si T augmente, alors la puissance augmente (graphe de droite) :
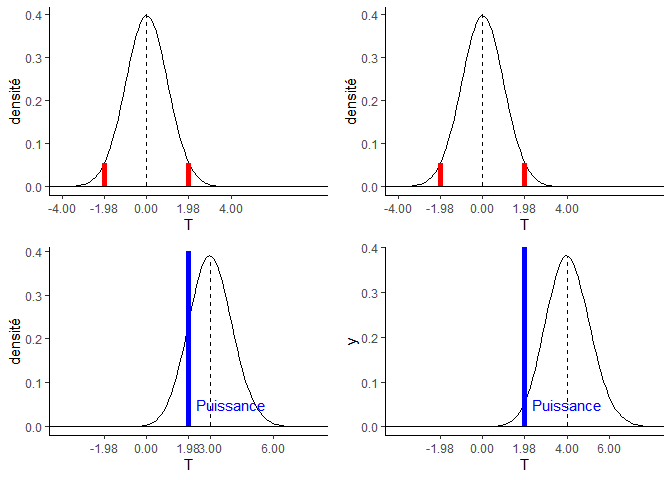
La puissance statistique augmente lorsque la différence des moyennes augment
Si la taille des échantillons augmente et que tous les autres paramètres restent constant alors T augmente :
d=3
s2=5
nA=nB=10
T = d/sqrt(s2*(1/nA+1/nB))
T
## [1] 3 d=3
s2=5
nA=nB=20
T = d/sqrt(s2*(1/nA+1/nB))
T
## [1] 4.242641 La puissance statistique diminue lorsque dispersion des observations augmente.
# alpha=5% (situation bilatérale)
qt(p=0.975, df=98)
## [1] 1.984467
# alpha=10% (situation bilatérale)
qt(p=0.95, df=98)
## [1] 1.660551 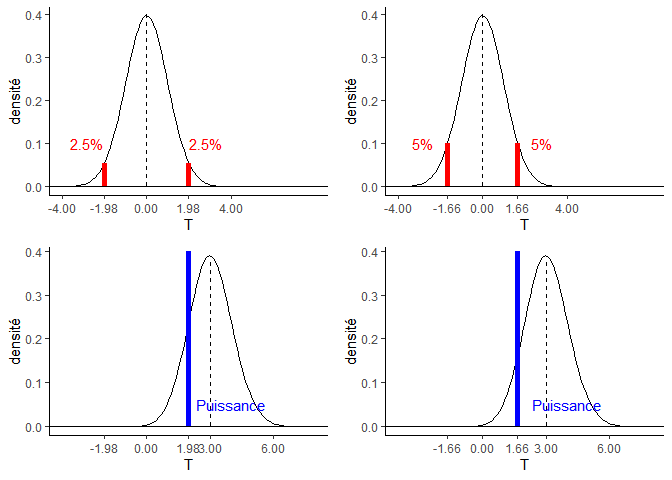
J’espère que cet article d’introduction à la puissance statistique permettra au plus grand nombre, notamment les débutants, de saisir ce concept.
Dans un prochain article, je vous montrerai comment estimer le nombre de sujets nécessaires pour atteindre une puissance donnée, en faisant varier les autres éléments.
Et vous, avez vous l’habitude de calculer le nombre d’unités expérimentales nécessaires en amont de vos expérimentations ? Si oui, quelles approches et quelles fonctions utilisez vous ?
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photos :Image par Alexander Gounder de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
6 réponses
Pouvons-nous avoir l’article au format pdf
Bonjour,
je reçois beaucoup de demandes pour obtenir les articles en pdf. Malheureusement cela n’est pas possible car je ne les ai pas sous ce format.
Bonne continuation.
Très bien résumée. Félicitations Claire
Bonjour,
et merci pour cet article, je pense que je viendrai souvent m’y référer quand je m’embrouille les pinceaux sur alpha, beta, et la puissance.
Quelques questions de néophyte :
– la démonstration est faite pour le test de Student, dans quelle mesure peut-on étendre à d’autres tests ?
– dans le point « 3.2 La puissance augmente quand la taille des échantillons augmente » pourquoi dans l’exemple la distance d entre les moyennes augmente également ?
Bonjour Claire,
merci pour ces articles très clairs et pédagogiques.
J’ai noté une erreur de frappe dans le calcul de la variance poolée: S2B et non S1B.
Bonne journée
Bonjour Véronique,
merci pour le signalement, je viens de corriger !