La régression logistique est une approche statistique qui peut être employée pour évaluer et caractériser les relations entre une variable réponse de type binaire ( par exemple : Vivant / Mort, Malade / Non malade, succés / échec), et une, ou plusieurs, variables explicatives, qui peuvent être de type catégoriel (le sexe par exemple), ou numérique continu (l’âge par exemple).
Tout comme la régression de Poisson, la régression logistique appartient aux modèles linéaires généralisés. Pour rappel, il s’agit de modèles de régression qui sont des extensions du modèle linéaire, et qui reposent sur trois éléments :
Les aspects théoriques et mathématiques de la régression logistique sont relativement complexes, c’est pourquoi nous ne les aborderons pas ici. Néanmoins, certains éléments caractérisant la régression logistique peuvent être retenus.
Remarque : La régression logistique peut également être utilisée comme un algorithme de classification supervisée, mais nous ne l’aborderons pas ici.
Dans la régression logistique, ce n’est pas la réponse binaire (malade/pas malade) qui est directement modélisée, mais la probabilité de réalisation d’une des deux modalités (être malade par exemple)
Cette probabilité de réalisation ne peut pas être modélisée par une droite car celle-ci conduirait à des valeurs <0 ou >1. Ce qui est impossible puisqu’une probabilité est forcément bornée par 0 et 1.
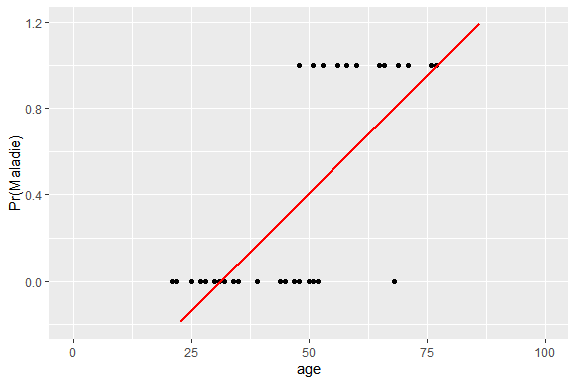
Remarque : les données représentées ici sont inspirées de celles disponibles sur cet article.
Cette probabilité, est alors modélisée par une courbe sigmoïde, bornée par 0, et 1 :
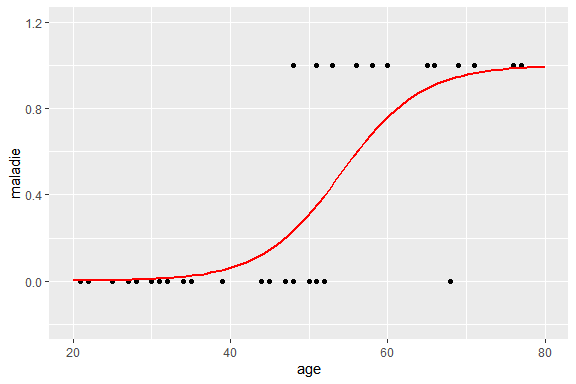
Cette courbe sigmoïde est définie par la fonction logistique, d’équation :
\[f(x) = \frac{exp(x)}{1+exp(x)}=p\]
Dans une situation de variables explicatives multiples l’équation se généralise en :
\[P(X) = \frac{exp(\beta_0+\beta_1X_1+…+\beta_nX_n)}{1+exp(\beta_0+\beta_1X_1+…+\beta_nX_n)}= \frac{exp(\sum\beta X)}{1+exp(\sum\beta_X)}\]
Le modèle précédent n’est pas linéaire dans l’expression des paramètres beta_X puisque la probabilité de réalisation ne s’exprime pas comme une addition des effets des différentes variables explicatives.
Pour obtenir un tel modèle (linéaire dans ses paramètres), il est nécessaire de passer par une transformation logit :
\[logit(p) = log(\frac{p}{1-p}) = \sum_{j=1}^{n} \beta_j\;X_{ij}\]
Cette transformation logit est la fonction de lien qui permet de mettre en relation la probabilité de réalisation (bornée entre 0 et 1), et la combinaison linéaire de variable explicatives.
Les données de base employées dans une régression logistique dont des données binaires (oui/non). Celles-ci sont distribuées selon une loi binomiale B(1,p). Il en est alors de même pour les erreurs : elles sont distribuées selon une loi binomiale B(1,p).
Le terme p/(1-p) est un rapport de cote (RC) ou Odds Ratio (OR), en anglais. Ce paramètre permet de mesurer la relation entre la variable explicative (X) et la réponse Y (vivant par exemple).
Les coefficients beta_j issus de la régression logistique sont donc des log odds ratio.
Un odds ou cote est le rapport de deux probabilités complémentaires : la probabilité P de survenue d’un événement (risque), divisé par la probabilité (1-P) que cet événement ne survienne pas (non risque, c’est-à-dire sans l’événement).
Par exemple, si on s’intéresse au risque de récidive d’une pathologie chez les hommes et les femmes, et que le risque de récidive est de 80% chez les hommes et de 40% chez les femmes, alors :
$OR = \frac{\frac{0.8}{0.2}}{\frac{0.4}{0.6}}=6$
Ici l’odds des hommes est 6 fois plus élevé que celui des femmes. On dira, par la suite (voir plus loin) que le risque de récidive est plus important chez les hommes. Pour plus d’information, consultez cet article.
Il s’agit des résultats d’une régression logistique visant à étudier le lien entre la présence d’une maladie cardiaque et le sexe des patients :
| Estimate | Std.Error | z value | Pr(>|z|) | |
| (Intercept) | -1.05779 | 0.2321396 | -4.556699 | 5.2e-06 |
| gendermale | 1.27220 | 0.2711647 | 4.691614 | 2.7e-06 |
Le coefficient (Estimate) de la ligne « gendermale » correspond au log OR. Pour obtenir l’OR, il est donc nécessaire d’employer une transformation
exponentielle :
OR_gender <- exp(1.27)
OR_gender
## [1] 3.560853 Lorsque la variable explicative est de type numérique, le coefficient obtenu est également un log(OR). Sa transformation, par la fonction exponentielle, permettra d’obtenir un OR qui caractérisera la force de la relation entre la probabilité de réalisation et la variable explicative.
Ici, il s’agit des résultat d’une régression logistique visant à étudier le lien entre l’apparition d’une maladie et l’âge des patients :
| Estimate | Std.Error | z value | Pr(>|z|) | |
| (Intercept) | -10.496783 | 3.4901907 | -3.007510 | 0.002634 |
| age | 0.194039 | 0.0665538 | 2.915519 | 0.003551 |
OR_age <-exp(0.19)
OR_age
## [1] 1.20925 Dans cette situation, il existe deux cas de figure :
Dans cette situation, on n’interprète pas non plus la valeur de l’OR. Dans l’exemple précédent l’OR relatif à l’âge = 1.23. On ne peut pas dire « une augmentation d’un an d’âge augmente le risque de maladie d’un facteur 1.23 ». Dans cette situation on se contente de regarder le signe de l’OR, et s’il est significativement différent de 1 (pvalue du log OR <0.05), on pourra dire « il existe une association significative entre l’âge et le risque de maladie, au risque de 5%, le risque de maladie augmente lorsque l’âge augmente ».
J’espère que cette courte introduction à la régression logistique vous permettra d’en comprendre les principes et les éléments fondamentaux.
Et si vous voulez, allez plus loin, et apprendre comment réaliser une régression logistique sous R, je vous conseille de consulter mon article La régression logistique par l’exemple.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
11 réponses
Merci Claire de nous éclairer la lanterne au travers de cet article super bien rédigé.
Merci pour cet article !
Une petite question : Dans la partie ‘Interprétation de l’OR’, > ‘Lorsque que la variable explicative est catégorielle’ = Est-il possible d’avoir plus de détails et des explications quant à la fréquence de réalisation (rare ou pas rare) ? Pourquoi avons nous le droit d’interpréter dans un cas et pas dans l’autre (convention, règle mathématique, logique ?). Le cutoff de 10% est strict ?
Merci pour vos réponses et votre travail !
Bonjour,
D’après ma compréhension, on ne peut pas interpréter l’OR comme un RR car on est plutôt dans une situation d’expérimentation cas-témoins, dans laquelle le nombre de sujets malades est contrôlé, ou choisit . Or les RR sont basés sur un ratio d’incidence, et n’ont de sens que lorsque le nombre de sujets malades n’est pas contrôlé.
Je pense que lorsque la prévalence de la maladie est inférieure à 10%, les estimations des RR et des OR doivent être relativement similaires et donc que l’estimation du RR par l’OR ne soit pas être trop biaisé.
Si quelqu’un à une meilleure réponse, n’hésitez pas à laisser un commentaire !
Merci, c’est très instructif.
Lorsque la variable explicative est catégorisée ( sexe par exemple), on peut dire que la probabilité que la maladie récidive est 4 fois plus grande chez les hommes par rapport aux femmes . Ici la catégorie ^femme^ Est prise comme référence, autrement dit un choix du chercheur.
Merci et bien à vous.
Du coup ma question étant, comme mesuré l’effect size si on ne peut pas vraiment interpréter les odd ratio? D’autant plus que, de mémoire, les R² ne sont pas toujours considéré comme très pertinent pour ce type de model.
Merci Claire pour ce articles. J’ai beaucoup appris.
Excellent !!!
article très intéressant! j’apprends quelques choses de nouveaux tous les jours que je visite cette plateforme.
Très intéressant, merci!
Bonjour,
Un grand merci pour ces explications très claires !
J’ai une petite question : dans mon analyse univariée, mon OR est de 1.57 [0.97;2.51]. Lorsque je réalise la régression logistique et que j’ajuste sur d’autres variables il passe à 0.81 [0.45;1.46].
Bien que ce ne soit pas significatif dans les deux, il est assez rare qu’un OR « change de sens » ce qui change son interprétation et son effet. Y a-t-il une explication à cela ?
Merci
Bonjour,
Le changement de direction de l’odds ratio, également appelé inversion de l’effet, peut se produire lorsque des variables de confusion (c’est-à-dire des variables qui sont associées à la fois à l’exposition et au résultat) sont ignorées dans une régression univariée.
Dans votre cas, la variable explicative ajoutée dans la régression ajustée peut agir comme une variable de confusion. Si cette variable est fortement associée à l’exposition et au résultat, alors elle peut masquer ou biaiser l’effet de l’exposition lorsqu’elle est ignorée dans la régression univariée.
Supposons que nous étudions l’association entre l’utilisation de contraceptifs oraux (CO) et le risque de cancer du sein chez les femmes, en utilisant les données d’une grande étude cas-témoins.
Dans un premier temps, nous ajustons un modèle de régression logistique univariée pour évaluer l’association entre l’utilisation de CO et le risque de cancer du sein. Nous obtenons un odds ratio estimé de 1,43, avec un intervalle de confiance à 95% (IC) de 1,29 à 1,59. Ce résultat suggère une association positive entre l’utilisation de CO et le risque de cancer du sein.
Ensuite, nous ajustons un modèle de régression logistique multivariée, en ajoutant l’âge et l’indice de masse corporelle (IMC) en tant que variables explicatives. L’âge et l’IMC sont des variables de confusion potentielles, car elles sont associées à la fois à l’utilisation de CO et au risque de cancer du sein. Après ajustement pour l’âge et l’IMC, l’odds ratio pour l’utilisation de CO est maintenant de 0,82 (IC à 95%: 0,74 à 0,90).
Dans cet exemple, l’odds ratio univarié suggère une association positive entre l’utilisation de CO et le risque de cancer du sein. Cependant, l’ajout de l’âge et de l’IMC dans le modèle multivarié révèle que ces variables sont des facteurs de confusion importants, qui masquent l’effet réel de l’utilisation de CO sur le risque de cancer du sein. Après ajustement pour l’âge et l’IMC, l’odds ratio pour l’utilisation de CO est maintenant inférieur à 1, ce qui suggère une association négative ou protectrice.
J’espère que cela vous aide.
Bonne continuation.