Très récemment, j’ai travaillé sur la construction d’un score prédictif dans le domaine médical. Il s’agissait de construire un outil d’aide au pronostic de mauvaise réponse à un traitement donné, à l’aide d’une dizaine de variables prédictives.
La méthodologie classiquement employée consiste, à :
Au bout du compte, cette méthodologie nécessite de faire tourner de nombreux modèles de régression. Et comme on est dans le cadre de régressions logistiques (simples ou multivariées), les associations (simples ou ajustées) entre les variables prédictives et la variable réponse, se mesurent à l’aide d’un odds ratio. Cet odds ratio est obtenu par l’exponentielle du coefficient, fourni en sorti de la régression logistique.
Sur le principe calculer les odds ratio n’est pas particulièrement difficile. Ce qui est très chronophage, et profondément ennuyant, c’est de synthétiser tous les résultats obtenus dans des tables. En effet, pour un rapport, ou une publication, il est nécessaire de présenter les odds ratio, leur intervalle de confiance, et la p-value, obtenus à chaque étape,
c’est à dire :
C’est vraiment pénible. J’avais un demi pied dans la dépression 😉 quand j’ai découvert le package finalfit !
Ce package est absolument GENIAL ! Il fait quasiment tout le travail à votre place ! Et en plus, il est tidyverse compatible !
Pour illustrer l’utilisation du package finalfit, je vais employer les données heart_disease du package funModelling:
library(funModeling)
data("heart_disease")
HD <- heart_disease
head(HD)
## age gender chest_pain resting_blood_pressure serum_cholestoral
## 1 63 male 1 145 233
## 2 67 male 4 160 286
## 3 67 male 4 120 229
## 4 37 male 3 130 250
## 5 41 female 2 130 204
## 6 56 male 2 120 236
## fasting_blood_sugar resting_electro max_heart_rate exer_angina oldpeak
## 1 1 2 150 0 2.3
## 2 0 2 108 1 1.5
## 3 0 2 129 1 2.6
## 4 0 0 187 0 3.5
## 5 0 2 172 0 1.4
## 6 0 0 178 0 0.8
## slope num_vessels_flour thal heart_disease_severity exter_angina
## 1 3 0 6 0 0
## 2 2 3 3 2 1
## 3 2 2 7 1 1
## 4 3 0 3 0 0
## 5 1 0 3 0 0
## 6 1 0 3 0 0
## has_heart_disease
## 1 no
## 2 yes
## 3 yes
## 4 no
## 5 no
## 6 no Remarque : Par commodité, je ne vais pas stratifier les variables numériques, mais les utiliser comme telles (c’est à dire comme des variables numériques).
Pour obtenir les odds ratios des analyses logistiques univariées, il est nécessaire de définir :
Toutes les régressions logistiques univariées sont ensuite réalisées par la fonction `glmuni()`, et les résultats collectés et mis en forme par la fonction `fit2df()`
library(tidyverse)
library(finalfit)
dependent = "has_heart_disease"
explanatory = c("age","gender","chest_pain","resting_electro","fasting_blood_sugar", "max_heart_rate")
res_glm_uni <- HD%>%
glmuni(dependent, explanatory) %>%
fit2df(estimate_suffix=" (univarié)")
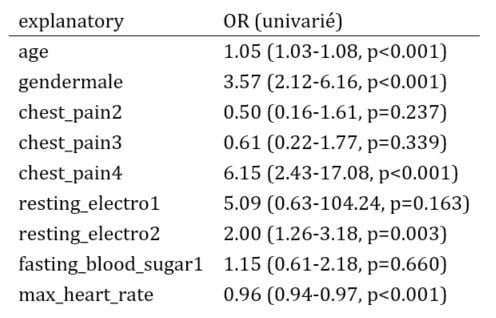
res_glm_uni
## explanatory OR (univarié)
## 1 age 1.05 (1.03-1.08, p<0.001)
## 2 gendermale 3.57 (2.12-6.16, p<0.001)
## 3 chest_pain2 0.50 (0.16-1.61, p=0.237)
## 4 chest_pain3 0.61 (0.22-1.77, p=0.339)
## 5 chest_pain4 6.15 (2.43-17.08, p<0.001)
## 6 resting_electro1 5.09 (0.63-104.24, p=0.163)
## 7 resting_electro2 2.00 (1.26-3.18, p=0.003)
## 8 fasting_blood_sugar1 1.15 (0.61-2.18, p=0.660)
## 9 max_heart_rate 0.96 (0.94-0.97, p<0.001) Pour obtenir un rendu élégant dans un document word ou pdf, on peut utiliser les lignes suivantes :
kable(res_glm_uni,row.names=FALSE, align=c("l", "l", "r", "r", "r", "r"))
Voici le rendu sous Word :
kable(), vous pouvez consulter l’article Guide de démarrage en R markdown.Pour cela, on utilise cette fois la fonction finalfit() :
res_glm_uni_multi <- HD %>%
finalfit(dependent, explanatory)
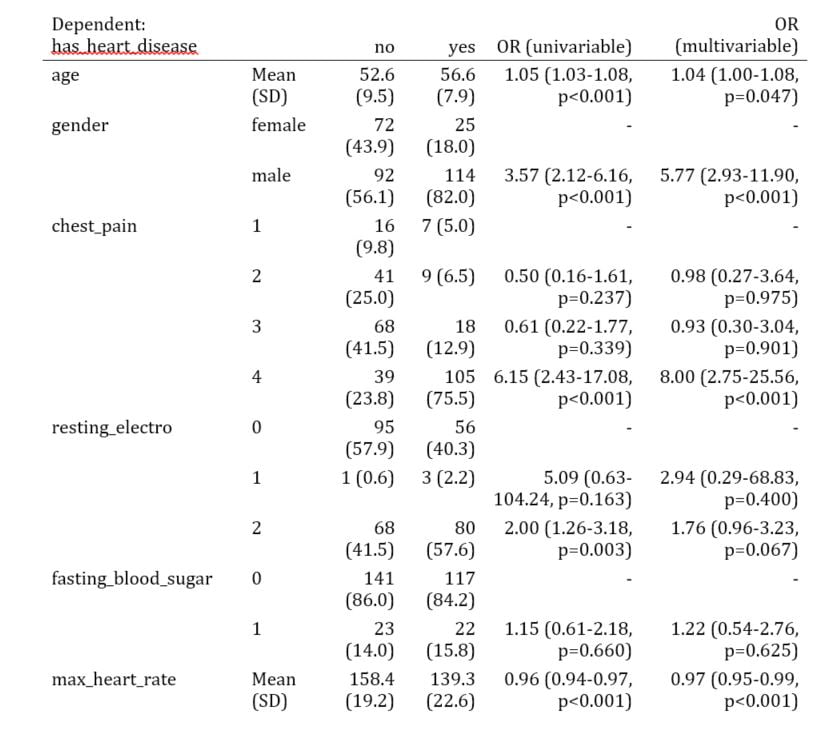
res_glm_uni_multi
## Dependent: has_heart_disease no yes
## 1 age Mean (SD) 52.6 (9.5) 56.6 (7.9)
## 8 gender female 72 (43.9) 25 (18.0)
## 9 male 92 (56.1) 114 (82.0)
## 2 chest_pain 1 16 (9.8) 7 (5.0)
## 3 2 41 (25.0) 9 (6.5)
## 4 3 68 (41.5) 18 (12.9)
## 5 4 39 (23.8) 105 (75.5)
## 11 resting_electro 0 95 (57.9) 56 (40.3)
## 12 1 1 (0.6) 3 (2.2)
## 13 2 68 (41.5) 80 (57.6)
## 6 fasting_blood_sugar 0 141 (86.0) 117 (84.2)
## 7 1 23 (14.0) 22 (15.8)
## 10 max_heart_rate Mean (SD) 158.4 (19.2) 139.3 (22.6)
## OR (univariable) OR (multivariable)
## 1 1.05 (1.03-1.08, p<0.001) 1.04 (1.00-1.08, p=0.047)
## 8 - -
## 9 3.57 (2.12-6.16, p<0.001) 5.77 (2.93-11.90, p<0.001)
## 2 - -
## 3 0.50 (0.16-1.61, p=0.237) 0.98 (0.27-3.64, p=0.975)
## 4 0.61 (0.22-1.77, p=0.339) 0.93 (0.30-3.04, p=0.901)
## 5 6.15 (2.43-17.08, p<0.001) 8.00 (2.75-25.56, p<0.001)
## 11 - -
## 12 5.09 (0.63-104.24, p=0.163) 2.94 (0.29-68.83, p=0.400)
## 13 2.00 (1.26-3.18, p=0.003) 1.76 (0.96-3.23, p=0.067)
## 6 - -
## 7 1.15 (0.61-2.18, p=0.660) 1.22 (0.54-2.76, p=0.625)
## 10 0.96 (0.94-0.97, p<0.001) 0.97 (0.95-0.99, p<0.001) Comme vous pouvez le voir la fonction finalfit() renvoie aussi les moyennes et écart type des variables numériques dans les deux groupes de la variable dépendante, ainsi que les pourcentages lorsque les variables sont catégorielles.
Et pour un rendu élégant au format word,et/ou pdf :
kable(res_glm_uni_multi,row.names=FALSE, align=c("l", "l", "r", "r", "r", "r"))
Si vous souhaitez ne conserver que les résultats multivariés, vous pouvez simplement supprimer la colonne des résultats univariés, en utilisant la fonction select() du package dplyr :
res_glm_multi1 <- res_glm_uni_multi %>%
dplyr::select(-"OR (univariable)") Pour plus d’information sur l’utilisation de la fonction select() et du package dplyr, vous pouvez consulter l’article : Initiation à la manipulation de données avec le package dplyr.
Si vous n’êtes pas intéressé par la partie descriptive, vous pouvez utiliser la fonction glmulti() à la place de la fonction finalfit() :
res_glm_multi2 <- HD%>%
glmmulti(dependent, explanatory) %>%
fit2df(estimate_suffix="(multivarié)")
res_glm_multi2
## explanatory OR(multivarié)
## 1 age 1.04 (1.00-1.08, p=0.047)
## 2 gendermale 5.77 (2.93-11.90, p<0.001)
## 3 chest_pain2 0.98 (0.27-3.64, p=0.975)
## 4 chest_pain3 0.93 (0.30-3.04, p=0.901)
## 5 chest_pain4 8.00 (2.75-25.56, p<0.001)
## 6 resting_electro1 2.94 (0.29-68.83, p=0.400)
## 7 resting_electro2 1.76 (0.96-3.23, p=0.067)
## 8 fasting_blood_sugar1 1.22 (0.54-2.76, p=0.625)
## 9 max_heart_rate 0.97 (0.95-0.99, p<0.001) Il s’agit ici d’obtenir et de présenter les odds ratio :
Attention, la sélection des variables du modèles multivarié doit être réalisé par ailleurs. Pour donner un exemple, je le fais ici par une procédure descendante basée sur le score d’Akaïké (AIC), avec la fonction `stepAIC()` du package `MASS`.
glm_full <- glm(has_heart_disease ~age + gender + chest_pain + resting_electro + fasting_blood_sugar + max_heart_rate,
data=HD, family=binomial )
library(MASS)
glm_multi_restreint <- stepAIC(glm_full, trace=FALSE)
library(car)
Anova(glm_multi_restreint)
## Analysis of Deviance Table (Type II tests)
##
## Response: has_heart_disease
## LR Chisq Df Pr(>Chisq)
## age 5.263 1 0.02179 *
## gender 27.142 1 1.891e-07 ***
## chest_pain 54.337 3 9.510e-12 ***
## max_heart_rate 15.361 1 8.882e-05 *** Les variables incluses dans le modèles multivarié final sont :
Pour compiler les résultats des 3 niveaux d’analyse (modèles univariés, modèle multivarié complet, et modèle multivarié final), la démarche consiste à :
dependent = "has_heart_disease"
explanatory_full = c("age","gender","chest_pain","resting_electro","fasting_blood_sugar", "max_heart_rate")
explanatory_final = c("age","gender","chest_pain", "max_heart_rate")
res_summary <- HD %>%
summary_factorlist(dependent, explanatory_full, fit_id=TRUE)
res_uni <- HD%>%
glmuni(dependent, explanatory_full) %>%
fit2df(estimate_suffix="(univarié)")
res_multi_full <- HD%>%
glmmulti(dependent, explanatory_full) %>%
fit2df(estimate_suffix="(ajustés - modèle complet)")
res_multi_final <- HD%>%
glmmulti(dependent, explanatory_final) %>%
fit2df(estimate_suffix="(ajustés - modèle final)")
tab_res <- res_summary %>%
finalfit_merge(res_uni) %>%
finalfit_merge(res_multi_full) %>%
finalfit_merge(res_multi_final) %>%
dplyr::select(-levels, fit_id, -index) # supression des colonnes qui ne sont pas nécessaires
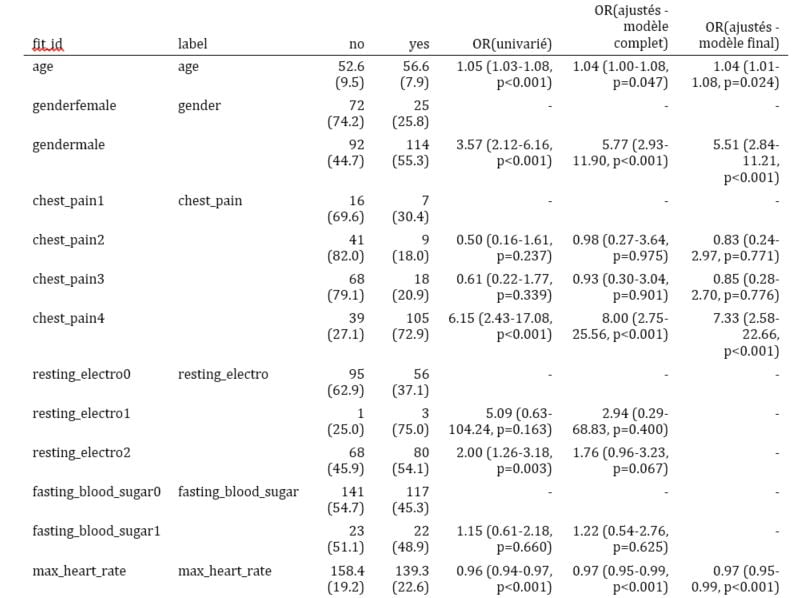
tab_res
tab_res
knitr::kable(tab_res, row.names=FALSE, align=c("l", "l", "r", "r", "r", "r", "r")) Voici le rendu sous Word :
Pour cela, il suffit d’employer la fonction or_plot()
HD %>%
or_plot(dependent, explanatory) 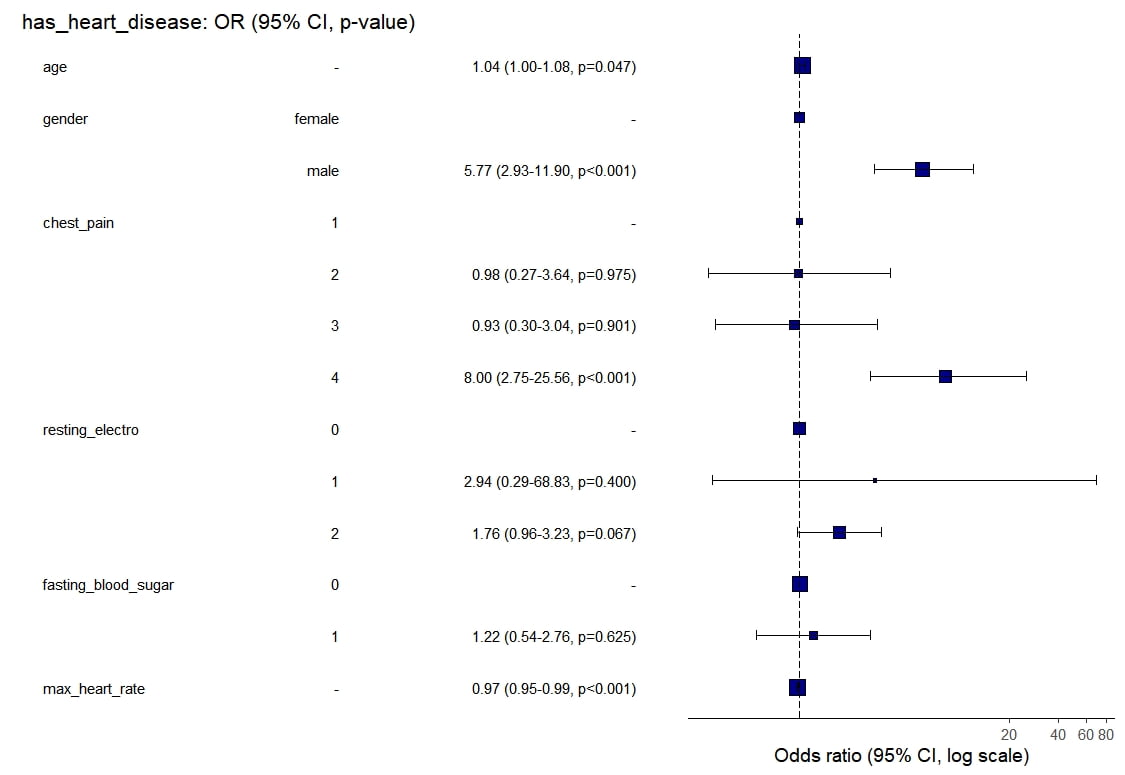
Les modèles de régression logistique construits par les fonctions du package finalfit utilisent une distribution binomiale des erreurs. Avant d’utiliser ces fonctions, il est nécessaire de vérifier qu’aucune surdispersion n’est présente. En cas de surdispersion, les intervalles de confiance et les p-values ne sont pas valides.
Le package finalfit n’est pas spécifiquement dédié à la régression logistique ! Il contient des fonctions similaires à celles présentées ici et qui peuvent être employés dans le cadre de régressions linéaires simples et multiples, dans le cadre de modèles à effets mixtes ou encoredans le cadre d’analyse de survie. Je vous encourage vivement à découvrir les possibilités de ce package en consultant sa vignette.
Et si vous souhaitez une bonne introduction, pratique, à la régression logistique dans un contexte médical / épidémiologique, je vous conseille cette vidéo de Tierry Ancelle,

ainsi que les deux articles suivants :
Alors, que pensez vous des possibilités de ce package finalfit ? Dites moi, en commentaire, quelle fonction vous parait la plus bluffante ?
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photos :Image par photosforyou de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
37 réponses
Merci claire pour ce riche article. Le package est vraiment génial. Merci également pour tout ce que tu fais pour nous des experts de la statistique et du logiciel R. Si tu pouvais nous aider avec un article sur l’analyse de survie.
1 . Conditions de réalisation
2. Définition des variables
3. Analyse et Interprétation
Merci de faciliter la voie des apprenants!!! Interessant!
tres belle reflexion, je suis tellement etonne’ de ta reflexion. Merci beaucoup!!!!!
Merci beaucoup pour ce tutoriel très claire et très intéressant!
J’aurai voulu savoir si avec ce package il serait possible de faire la même chose avec les risques relatifs plutôt que les OR et en prenant en compte les poids de sondage ? J’ai essayé de trouver un moyen de le combiner avec le package survey mais n’ai pas réussi :/
Très bonne journée à vous !
Et merci encore pour tout 🙂
Merci beaucoup pour cet article.
Merci pour cet article.
J’avais justement un rapport d’études statistiques à présenter et jumeler les coefficients, les odds ratios, les p-value sur un même tableau. J’ai dû tout programmer tout ça moi-même. J’ignorais qu’un package existait pour le faire. Vaut mieux tard que jamais 😁😁.
comment vérifier la surdispersion…Merci.
Comment faire pour utiliser cela avec RR (Relative risk ratio). MERCI.
Bonjour,
Merci pour ce tutoriel très clair.
Je bloque néanmoins à l’étape
res_glm_uni_multi %
finalfit(dependent, explanatory)
Ou lorsque j’applique à mon dataset j’obtiens l’erreur:
Error: Tibble columns must have consistent lengths, only values of length one are recycled:
* Length 82: Column `p`
* Length 83: Columns `explanatory`, `estimate`, `confint[, 1]`, `confint[, 2]`
Si vous avez un conseil, je suis preneur.
Bien à vous
Bonsoir,
non, là comme ça, je ne sais pas…navrée.
Bonne continuation.
Bonjour,
J’ai à peu près le meme problème que vous, l’avez vous résolu?
Je me demande si ce n’est pas à cause des données manquantes
Bonjour,
Merci pour cette fonction qui simplifie la vie !
Quelle test statistique utilisez vous dans l’analyse univariée pour les variables continues ? Il s’agit bien d’un test de Wilcoxon si les variables ne sont pas distribuées normalement ?
Bonjour,
je ne suis pas sûre de comprendre votre question.
Le test de Wilcoxon permet de comparer les médianes de deux groupes. On le présente généralement comme une alternative non paramétrique au test de comparaison de deux moyennes, de Student.
Bonne continuation
Merci c’est très interessant.
J’ai un blocage à cette étape:
res_glm_uni %
glmuni(dependent,explanatory) %>%
fit2df(estimate_suffix= »univarié »)
Error in eval(lhs, parent, parent) : objet ‘HD’ introuvable
Quelqu’un peut-il m’aider?
Merci beaucoup
Bonjour,
vous avez oublié de définir HD:
library(funModeling)
data (heart_disease)
HD <- heart_disease
Bonne continuation
Bonjour,
comment faire pour télécharger le tableau obtenu avec knitr::kable pour l’avoir au format word et / ou pdf pour l’intégrer dans mon outil de rédaction ?
Bien à vous.
Bonjour,
en knittant le document (en cliquant sur le bouton avec pelote) et en choisissant un rendu word, vouas allez obtenir une document word.
J’espère que ça vous aide…
Merci pour cet article… et pour tant d’autres !
J’ai un vague souvenir comme quoi quand une cellule d’une table de contingence contient moins de cinq cas, il faut utiliser le Fisher Exact Test pour obtenir l’OR.
Pouvons-nous faire confiance aux OR donnés par la régression logistique s’il existe des cas de valeurs de variables catégorielles avec moins de cinq cas ? Dans votre exemple, la variable resting_electro a deux cases avec n < 5.
Merci !
Bonjour Antoine,
je pense que ce sont les effectifs théoriques (et pas les effectifs observés) qui doivent être >5.
Lorsque ces effectifs théoriques sont <5, effectivement on utilise le test exact de Fisher pour obtenir l’OR.
Pour la régression logistique, à ma connaissance, il est seulement recommandé d’avoir au moins 10 fois plus d’événements que de paramètres dans le modèle. Mais je trouve votre question très pertinente…mais je n’ai pas la réponse.
Bonjour,
Merci pour cet article très clair, c’est dingue le temps qu’on peut gagner !
Une question toutefois. Si des transformations polynomiales sont nécessaires sur certaines variables quantitatives (j’utilise le package mfp), peut-on intégrer cela directement dans cette analyse ?
Merci beaucoup par avance !
Jerome
Bonjour Jérôme,
aucune idée, il faut essayer.
Bien à vous
Bonjour Claire,
Merci pour ce bel article!
Selon votre exemple, glmuni permet de générer plusieurs lignes d’OR pour les variables de 3 ou 4 classes, pourtant je ne retrouve pas ce résultat (mais une seule ligne pour chaque variable), auriez vous une explication ou un conseil pour que je puisse obtenir des OR pour chaque classe?
Merci d’avance,
Sarah R
Bonjour Sarah,
je pense que votre variable explicative, n’est pas considérée comme une variable catégorielle (ou facteur), mais comme une variable numérique.
Pour vérifier vous pouvez utiliser la commande str(dataset) et regarder s’il est écrit « factor » en face de vos variables epxlicatives. Pour convertir une variable (codée 1, 2, 3 4 par exemple) et considérée comme une variable numérique vers une variable « facteur », il faut employer dataset$var1 <- as.factor(dataset$var2). Vérifiez ensuite avec str(dataset). Si la variable est une chaîne de caractères je ne sais pas trop comment finalfit agit, mais vous pouvez aussi la transformer en facteur avec la même commande. En espérant que cela vous aide ! Bonne continuation.
Merveilleux, cela fonctionne <3
Et cela semble également aider avec finalfit, bien que mes données manquantes paraissent toujours un problème (Error in `contrasts<-`(`*tmp*`, value = contr.funs[1 + isOF[nn]]) :
contrasts can be applied only to factors with 2 or more levels)
Comment les gérez vous en général?
J'ai peur de perdre en puissance si je supprime toutes les lignes avec NA…
Merci pour cet article. Le package finafit permet effectivement d’avoir de beaux résultats sauf quand une des bornes de l’intervalle de confiance est très grand ce qui donne :
256767.04 (0.00-NA, p=0.991)
4519200.20 (0.00-273031300566351634988629643284026843358029946781144721659057830021038396153344099941264537598271134713830912854328018982506231153640683125541674002469186976352306901753445021518770733056.00, p=0.992)
Très moche.
Ha oui ! C’est une belle performance. J’aimerais bien voir les données d’entrée. L’IC a été construit sur combien de données ?
Données de m…, nb de cas ridicule (110 cas exploitables). Mais le chef veut des stats…
Message d’erreur :Error in eval(family$initialize) : y values must be 0 <= y <= 1
Nécessité d'une stratification des variables numériques ? Comment réaliser une stratification des variables numériques ?
Merci beaucoup
Bonjour Claire, merci bcp pour cette article que je viens de découvrir , mieux vaut tard que jamais.
Je ne suis pas expert en stats, mais je comprends que ce package est pour une analyse en régression logistique binaire.
Est ce bien cela ?
Et sais-tu si on peut trouver le même genre pour faire une analyse de survie en cox ?
Merci bcp
Bonjour Philippe,
Il me semble que le package finalfit permet la même chose avec les hazrd ratio. Vous trouverez de la doc ici : https://finalfit.org/reference/coxphuni.html
Bonne continuation.
Merci bcp +++
C’est super !
Encore merci pour le blog qui regorge d’astuces simples pour les novices
Bonjour,
Merci pour cette très belle présentation.
J’ai une question cependant : lors de l’étape
res_glm_uni %
+ glmuni(dependent, explanatory) %>%
+ fit2df(estimate_suffix= » (univarié) »)
R me renvoie « could not find function « fit2df » », malgré l’appel de library final fit..
Comment faire ?
Merci d’avance,
Bien cordialement,
Bonjour Martin,
je suis embêtée parce que je viens de re-essayer, et tout fonctionne.
Quelques pistes : êtes-vous certain que la library finalfit est bien chargée ? Si vous écrivez dans la console ?fit2df, vous devez voir la page d’aide de la fonction qui s’ouvre sur la droite.
Si cela ne fonctionne toujours pas, je vous conseille de suivre les étapes de la vignette : https://github.com/ewenharrison/finalfit
Et sinon, vous pouvez ouvrir une issue ici : https://github.com/ewenharrison/finalfit/issues
Tenez nous au courant.
Merci
Bonsoir !
SVP je débutant et j’ai besoin d’aide avec mes données quand j’utilise le package finalfit pour les analyses univariées, ça me renvoi ceci :
Error in str2lang(x) : :1:11: unexpected symbol
1: Résultats Syphilis
Merci d’avance
Bonjour Claire,
j’ai une question bête : A quoi correspond le « SD » lorsqu’il s’agit d’une variable catégorielle et non numérique ? Par exemple dans votre exemple « gender ».
Merci d’avance
Guillaume
Bonjour Guillaume,
Lorsque la variable est catégorielle, les nombres correspondent aux nombre d’observations, et entre parenthèses sont affichés les pourcentages correspondants.
Bonne continuation