Tutoriel : GLM sur données de comptage (régression de Poisson) avec R
Les GLM (modèles linéaires généralisés) sur données de comptage, ou régression de Poisson, sont des approches statistiques qui doivent être employées lorsque la variable à analyser résulte d’un processus de comptage (comme un nombre d’œufs pondus, un nombre de buts marqués, ou encore un nombre de visites sur un site internet). Ces approches sont indispensables, car dans cette situation les hypothèses des modèles linéaires classiques ne sont plus satisfaites.
De manière plus précise, les modèles de régression de Poisson, sont des GLM, comportant une fonction de lien log et une structure d’erreur de type Poisson.
Dans cet article, je vous propose quelques rappels d’ordre théorique concernant les GLM sur données de comptage, suivis d’un tutoriel pour mettre en oeuvre cette approche, en pas à pas, avec R, dans deux situations courantes : la régression linéaire, et l’ANOVA.
Rappels
Pourquoi les modèles linéaires classiques ne sont pas adaptés
Les modèles linéaires classiques ne sont pas adaptés pour analyser des variables à expliquer (ou réponses) de type « comptage », notamment parce qu’ils supposent que celles-ci sont distribuées selon une loi Normale. Cette hypothèse conduit alors à considérer que la variance des résidus est homogène, autrement dit constante, quelle que soit la valeur des comptages moyens prédits par le modèle. Or, les données de type comptage ne sont pas distribuées selon une loi Normale, mais selon une loi de Poisson. Et compte tenu de cette loi de distribution ,la variance des résidus n’est pas constante mais proportionnelle aux comptages moyens prédits par le modèle.
Cette différence n’est pas une nuance, elle est capitale ! Utiliser un modèle linéaire classique pour traiter des réponses de type « comptage » peut entraîner, entre autres, une estimation biaisée de l’erreur standard des paramètres du modèle, ce qui peut conduire à une estimation erronée de la p-value, et à une conclusion inexacte.
De plus, l’utilisation de modèles linéaires classiques pour analyser des données de type comptage peut conduire à des prédictions négatives. Voir un exemple ici .
La distribution de Poisson
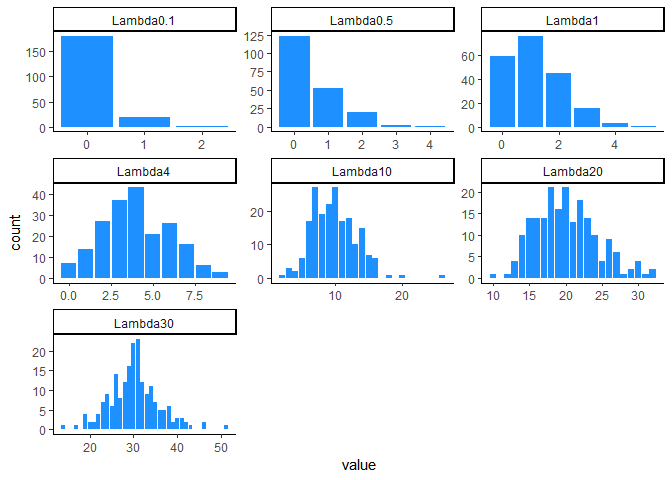
Plus Lambda augmente, plus la distribution de Poisson se rapproche d’une loi Normale. On dit qu’une loi de Poisson peur être approximée par une loi Normale quand Lambda est égal 20 ou 30 ( ça dépend des auteurs !).
La distribution de Poisson possède deux éléments remarquables :
- L’espérance ( ou moyenne) d’une variable aléatoire distribuée selon une loi de poisson est égale à Lambda :
\[ E(y) = \lambda \]
- La variance d’une variable aléatoire distribuée selon une loi de poisson est aussi égale à Lambda :
\[ Var(y) = \lambda \]
Caractéristiques des GLM pour données de comptage
Comme expliqué dans l’article d’introduction aux GLM, ces modèles sont constitués de trois éléments :
- un prédicteur linéaire,
- une fonction de lien Log
- une structure d’erreur de Poisson
Le prédicteur linéaire du GLM suppose simplement que les réponses prédites par le modèle linéaire généralisé vont l’être à partir d’une combinaison linéaire des variables prédictives.
\[ µ_y = \sum_{j=1}^{p}\;\beta_j\;X_{ij} \]
On nomme généralement ce prédicteur linéaire par la lettre ƞ (eta):
\[ \eta \; = \sum_{j=1}^{p} \beta_j\;X_{ij} \]
Cependant, contrairement aux modèles linéaires classiques, les valeurs prédites par le prédicteur linéaire du GLM ne correspondent pas à la prédiction moyenne d’une observation, mais à la transformation (par une fonction mathématique) de celle-ci. Dans le cas de la régression de Poisson il s’agit de la transformation log. Ce lien est défini par l’équation suivante :
\[log(µ_y) =\sum_{j=1}^{p} \beta_j\;X_{ij} \]
En pratique, cela signifie que les valeurs du prédicteur linéaire sont obtenues en transformant préalablement les valeurs observées par la fonction de lien. Autrement dit, les beta sont estimés après transformation des réponses par la fonction Log.
Pour obtenir la prédiction moyenne, il est alors nécessaire d’appliquer la fonction inverse du Log, c’est à dire la fonction exponentielle :
\[ µ_y = e^{\sum_{j=1}^{p} \beta_j\;X_{ij}} \]
Les modèles de régression de Poisson ont une structure d’erreur de Poisson. Cette structure d’erreur, permet notamment de spécifier correctement la relation entre la moyenne et la variance. Cette relation est utilisée par l’approche de maximum de vraisemblance pour estimer les coefficients et les erreurs standard des paramètres du modèle GLM.
Les conditions de validité du modèle de régression de Poisson
Les résultats issus des modèles de régression de Poisson sont valides si:
- les réponses sont indépendantes.
- les réponses sont distribuées selon une loi de Poisson, de paramètre Lambda.
- il n’existe pas de surdispersion
L'indépendance des réponses
L’indépendance des réponses signifie qu’elles ne doivent pas être corrélées entre elles. Par exemple, il ne doit pas avoir de lien entre une réponse et celle de la ligne suivante, ou précédente, dans le jeu de données. On voit cela, lorsque des données sont répétées sur des sujets, ou des unités expérimentales identiques.
L’indépendance des réponses se valide par l’étude du plan expérimental : pour réaliser une régression de Poisson, il ne doit pas avoir de données répétées. Si c’est le cas, il faut utiliser un autre type de modèle, comme un modèle linéaire généralisé à effet mixte (Generalized Linear
Mixed Models, ou GLMM).
La distribution des réponses selon une loi de Poisson
La distribution des réponses (selon une loi de Poisson) est généralement supposée. Néanmoins, cette hypothèse peut être explorée en comparant la distribution des comptages observés à la distribution théorique des comptages sous une loi de poisson de paramètre Lamda, estimé par la moyenne des comptages observés. Si cette hypothèse est rejetée, un autre structure d’erreur devra être utilisée dans le GLM.
Absence de surdispersion
La variance des réponses est, selon la théorie, c’est à dire selon la loi de Poisson, égale à la moyenne des réponses. On dit qu’il y a surdispersion lorsque la variance réelle est supérieure à cette variance théorique. Cela est problématique car dans cette situation, l’erreur standard des paramètres des modèles de régression de Poisson sera sous estimée. Ceci peut conduire à une p-value excessivement faible, et donc aboutir à une conclusion erronée sur la significativité de la liaison entre les comptages observés et la ou les variables explicatives.
Le paramètre phi permet d’estimer si la variance réelle des observations n’est pas trop éloignée de la variance théorique :
$ \phi = \frac{\text{variance observée}}{\text{variance théorique}} = \frac{\text{variance observée}}{\text{moyenne}} = \frac{\text{variance observée}}{\lambda} $
En pratique, phi est estimé par le ratio de la déviance résiduelle sur le nombre de degrés de libertés du modèle :
\[ \widehat{\phi} = \frac{{deviance\; residuelle}} {nddl} \]
Si ce ratio est supérieur à 1, alors il y a surdispersion. Mais cette supériorité à 1 est un peu subjective, dans le sens ou il n’existe pas de seuil (1.5, 2 ?) à partir duquel on considère qu’il y a surdispersion. En réalité ce seuil dépend aussi du nombre de données considérées.
Certains packages, notamment `AER`, propose un test statistique pour aider à la prise de décision.
Les principales cause des surdispersion sont :
- une corrélation entre les réponses,
- l’absence d’une variable explicative importante,
- un sur-représentation des valeurs zéro par rapport à ce qui est attendue selon la distribution de Poissson de paramètre Lambda.
En cas de surdispersion, il est nécessaire d’utiliser d’autres structures d’erreur, telles que les structures « quasi Poisson » ou « négative binomiale« .Celle-ci vont conduire à une augmentation de l’erreur standard des paramètres du modèle, par un facteur :
\[ \sqrt(\widehat{\phi}) \]
Pour plus d’informations sur la surdispersion, vous pouvez consulter ces diapositives crées par Arthur Charpentier.
Les data
Dans la suite de cet article, je vais vous montrer comment réaliser une régression linéaire simple lorsque la variable réponse est de type comptage. Puis dans un second temps, je vous montrerai, dans la même situation, comment réaliser une analyse de type ANOVA à un facteur.
Pour illustrer ces deux types d’analyse, je vais utiliser le jeu de données « Orstein » du package « car ».
library(car)
data(Ornstein) Ce jeu de données concerne les 248 compagnies les plus importantes du Canada dans les années 70. Il comporte 4 variables :
- interlocks : nombre de postes d’administrateurs partagés avec d’autres grandes entreprises. Il s’agit de la variable de type comptage à expliquer.
- assets : actifs de la compagnie en millions de dollars ; il s’agit d’une variable de type numérique continue
- sector : secteur industriel de la compagnie, il s’agit d’une variable catégorielle à 10 modalités
- nation : nation contrôlant la compagnie, il s’agit d’une variable catégorielle à 4 modalités.
str(Ornstein)
## 'data.frame': 248 obs. of 4 variables:
## $ assets : int 147670 133000 113230 85418 75477 40742 40140 26866 24500 23700
## $ sector : Factor w/ 10 levels "AGR","BNK","CON",..: 2 2 2 2 2 4 9 2 9 8 ...
## $ nation : Factor w/ 4 levels "CAN","OTH","UK",..: 1 1 1 1 1 1 1 1 1 4 ...
## $ interlocks: int 87 107 94 48 66 69 46 16 77 6 ... Tutoriel régression de Poisson de type régression linéaire simple
Dans cette analyse, nous allons étudier la relation entre la variable réponse « interlocks » et la variable explicative « assets ».
Cette modélisation correspond à l’équation suivante :
\[ log(\mu_y) = \beta_0 + \beta_1*log10(assets)_{i} \]
Visualisation de la relation
La première étape consiste à visualiser cette relation par un scatterplot :
ggplot(Ornstein, aes(x=assets, y=interlocks))+
geom_point() 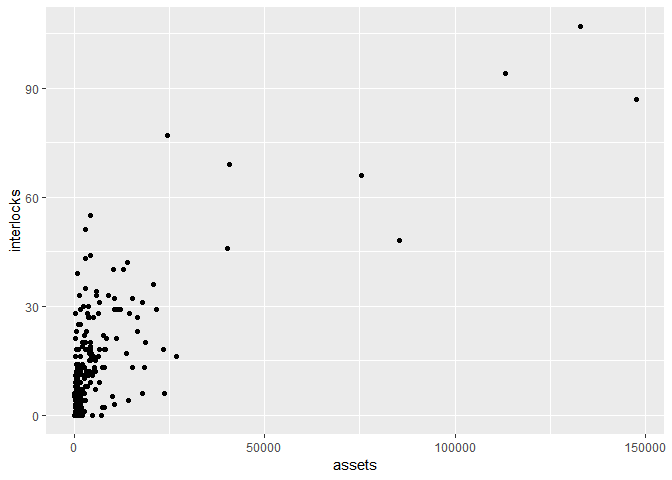
La variable assets est extrêmement étendue, nous allons alors utiliser une transformation log10.
ggplot(Ornstein, aes(x=log10(assets), y=interlocks))+
geom_point() 
La transformation log10 permet également de linéariser la relation, elle est donc nécessaire.
Ajustement du modèle de régression linéaire de Poisson
L’ajustement est réalisé à l’aide de la fonction glm() et de l’argument family= »poisson ».
mod.pois1 <- glm(interlocks~log10(assets),family="poisson", data=Ornstein) Evaluation des hypothèses de la régression de Poisson
Indépendance des réponses
Nous allons considérer que cette hypothèse est satisfaite.
Distribution des réponses selon une loi de Poisson
Une méthode simple pour évaluer cette hypothèse, consiste à comparer la distribution des comptages réellement observés, avec leur distribution théorique, selon la loi de Poisson de paramètre Lambda (estimé par la moyenne des comptages).
Pour cela, on commence par estimer la moyenne des comptages :
mean(Ornstein$interlocks)
## [1] 13.58065 La moyenne des comptages est égale à 13.58.
Puis on simule des comptages selon une distribution de Poisson de paramètres Lambda = 13.58.
set.seed(1234) # permet de simuler toujours les mêmes comptages.
theoretic_count <-rpois(248,13.58)
# on incorpore ces comptages théoriques dans un data frame
tc_df <-data.frame(theoretic_count)
# on plot simultanémaent les comptages observés et les comptages théoriques
library(ggplot2)
ggplot(Ornstein,aes(interlocks))+
geom_bar(fill="#1E90FF")+
geom_bar(data=tc_df, aes(theoretic_count,fill="#1E90FF", alpha=0.5))+
theme_classic()+
theme(legend.position="none") 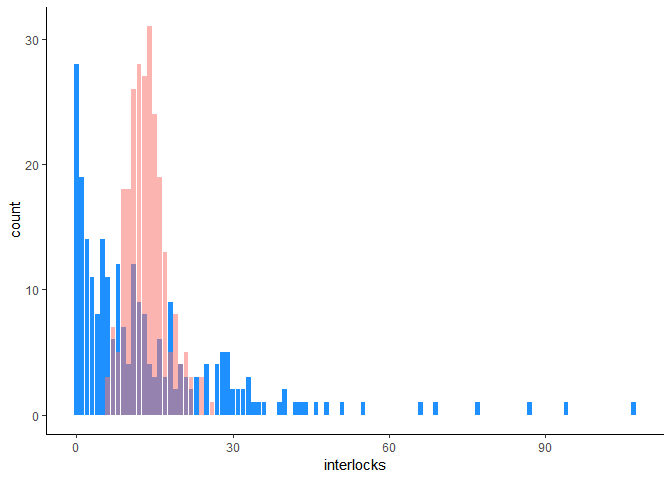
Les comptages observés (variable interlock) sont en bleu et les comptages théoriques en rouge.On peut voir que les deux distributions sont très différentes. La variable interlock ne suit donc pas une distribution de Poisson de paramètre lambda = 13.58. On peut également voir une sur-représentation des valeurs zéro dans les comptages observés ; il est donc très probable qu’une surdispersion soit mise en évidence.
Evaluation de la surdispersion
summary(mod.pois1)
##
## Call:
## glm(formula = interlocks ~ log10(assets), family = "poisson",
## data = Ornstein)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -6.387 -2.468 -0.505 1.127 7.858
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.04156 0.09037 -11.53 <2e-16 ***
## log10(assets) 1.05477 0.02386 44.22 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 3737.0 on 247 degrees of freedom
## Residual deviance: 1904.7 on 246 degrees of freedom
## AIC: 2806.7
##
## Number of Fisher Scoring iterations: 5 Le ratio residual deviance / ddl est égal à 1904.7 /246, soit 7.74. Ce ratio est très largement supérieur à 1 et permet de mettre en évidence la présence d’une surdispersion. Il est donc nécessaire d’utiliser une autre structure d’erreur dans le modèle de régression.
Utilisation d'autres structures d'erreurs
Structure d'erreur quasi poisson
Pour cela, il suffit de remplacer family= »poisson » par family= »quasipoisson » :
mod.quasipois1 <- glm(interlocks~log10(assets),family="quasipoisson", data=Ornstein) Comme expliqué précédemment, l’utilisation d’une structure d’erreur « quasi poisson » à pour conséquence d’augmenter l’erreur standard des paramètres.
summary(mod.quasipois1)
##
## Call:
## glm(formula = interlocks ~ log10(assets), family = "quasipoisson",
## data = Ornstein)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -6.387 -2.468 -0.505 1.127 7.858
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.04156 0.25617 -4.066 6.44e-05 ***
## log10(assets) 1.05477 0.06763 15.597 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasipoisson family taken to be 8.036124)
##
## Null deviance: 3737.0 on 247 degrees of freedom
## Residual deviance: 1904.7 on 246 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 5 Ici l’erreur standard associé à log10(assets) est égale à 0.07, alors qu’elle était estimée à 0.02 avec la structure d’erreur de Poisson (cf la sortie ci dessous):
summary(mod.pois1)
##
## Call:
## glm(formula = interlocks ~ log10(assets), family = "poisson",
## data = Ornstein)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -6.387 -2.468 -0.505 1.127 7.858
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.04156 0.09037 -11.53 <2e-16 ***
## log10(assets) 1.05477 0.02386 44.22 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 3737.0 on 247 degrees of freedom
## Residual deviance: 1904.7 on 246 degrees of freedom
## AIC: 2806.7
##
## Number of Fisher Scoring iterations: 5 Structure d'erreur négative binomiale
En cas de surdispersion, il est également possible d’utiliser une structure d’erreur quasi binomiale. Pour cela, on utilise la fonction glm.nb() du package MASS. Par défaut, la fonction de lien utilisée est également la fonction log :
library(MASS)
mod.nb1 <- glm.nb(interlocks~log10(assets), data=Ornstein) summary(mod.nb1) ## ## Call: ## glm.nb(formula = interlocks ~ log10(assets), data = Ornstein, ## init.theta = 1.300775815, link = log) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.7075 -0.9928 -0.1872 0.3845 2.5308 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.04733 0.31269 -3.349 0.00081 ***
## log10(assets) 1.05723 0.09392 11.257 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for Negative Binomial(1.3008) family taken to be 1)
##
## Null deviance: 437.30 on 247 degrees of freedom
## Residual deviance: 293.38 on 246 degrees of freedom
## AIC: 1694.8
##
## Number of Fisher Scoring iterations: 1
##
##
## Theta: 1.301
## Std. Err.: 0.142
##
## 2 x log-likelihood: -1688.811 Avec cette structure d’erreur, l’erreur standard associée à log10(assets) est estimée à 0.09. Cette correction entraîne une modification très importante de la z value, qui passe de 44.22 avec une structure d’erreur de Poisson à 11.257 ici. Dans d’autres situations, cela pourrait également avoir un impact très important sur la p-value, et donc sur les conclusions.
Interprétation des résultats
En reprenant les résultats obtenus avec la structure d’erreur « quasi poisson », les résultats sont obtenus à l’aide de la fonction summary() :
summary(mod.quasipois1)
##
## Call:
## glm(formula = interlocks ~ log10(assets), family = "quasipoisson",
## data = Ornstein)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -6.387 -2.468 -0.505 1.127 7.858
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.04156 0.25617 -4.066 6.44e-05 ***
## log10(assets) 1.05477 0.06763 15.597 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasipoisson family taken to be 8.036124)
##
## Null deviance: 3737.0 on 247 degrees of freedom
## Residual deviance: 1904.7 on 246 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 5 Comme rappelé précédemment, dans une régression de poisson, c’est le log de la moyenne des comptages qui est modélisé :
\[log(\mu_y) = \beta_0 + \beta_1*log10(assets)_{i} \]
Ici, Beta_0 = -1.04 et Beta_1 = 1.05.
L’interprétation de l’intercept (beta_0) ne présente généralement pas d’intérêt particulier. On s’intéresse alors uniquement au coefficient associé à la variable prédictive.
Le coefficients 1.05 associé à log10(asset) signifie qu’une augmentation d’une unité de log10 des actifs de la compagnie, est associée avec une augmentation de 1.05 du log du nombre moyen d’interlocks (c’est à dire du nombre moyen de postes d’administrateurs partagés).
Pour exprimer le coefficient de régression dans l’échelle originale, c’est à dire en nombre d’interlocks, plutôt qu’en log du nombre d’interlocks, il est nécessaire d’appliquer la transformation inverse du log, c’est à dire la transformation exponentielle.
\[ e^{1.05} = 2.86 \]
Ainsi, le nombre de postes d’administrateurs partagés augmente en moyenne de 2.86 lorsque le log10 des actifs augmente d’une unité.
Au final, en exprimant également les actifs dans leur échelle originale, on peut dire que le nombre de postes d’administrateurs partagés augmente en moyenne de 2,86 lorsque les actifs de la compagnie sont multipliés par 10 (puisqu’un unité en log10, correspond à un facteur 10).
Prédictions
La fonction predict.glm() permet d’estimer le nombre de postes d’administrateurs partagés prédit, en moyenne, par le modèle, pour un ou plusieurs niveaux d’actifs souhaités.
Pour cela, on crée un data frame nommé « mydf » (par exemple) contenant les niveaux d’actifs pour lesquels on souhaite obtenir une estimation, ici par exemple, 100,1000,5000,10000, 50000,et 100000. Il est très important d’utiliser le même nom de variable que dans le fichier de données utilisé lors de l’ajustement du modèle.
mydf=data.frame(assets=c(100,1000,5000,10000, 50000, 100000)) Ce dataframe est ensuite passé dans l’argument newdata de la fonction predict.glm(). L’argument type= »response » permet d’obtenir les prédictions dans l’échelle originale (c’est à dire en nombre de postes).
predict.glm(mod.quasipois1,newdata = mydf,type="response")
## 1 2 3 4 5 6
## 2.909514 8.354134 17.461694 23.987363 50.138048 68.875308 Par défaut, la fonction predict.glm() utilise l’argument type= »link », ce qui renvoi des prédictions dans l’échelle log :
predict.glm(mod.quasipois1,newdata = mydf)
## 1 2 3 4 5 6
## 1.067986 2.122757 2.860010 3.177527 3.914780 4.232298 Visualisation du modèle
Le principe est de créer un vecteur de valeurs de assets compris entre les valeurs min et max observées, puis de le passer dans un data frame.
xmin <- min(Ornstein$assets)
xmax <- max(Ornstein$assets)
predicted <- data.frame(assets=seq(xmin, xmax, length.out=1000)) Dans un second temps, la fonction predict.glm() est employée pour prédire le nombre moyen d’interlock pour chaque valeurs du vecteur créé précédemment. Ces prédictions sont ajoutées au data frame.
# Calculate predicted values of heightIn predicted$heightIn <- predict(model, predicted) predicted
predicted$interlocks <-predict.glm(mod.quasipois1,newdata= predicted, type="response")
head(predicted)
## assets interlocks
## 1 62.0000 2.337324
## 2 209.7558 4.084994
## 3 357.5115 5.215213
## 4 505.2673 6.110688
## 5 653.0230 6.872642
## 6 800.7788 7.545750 Enfin le plot est réalisé :
library(ggplot2)
ggplot(Ornstein, aes(x=log10(assets), y=interlocks)) + geom_point()+
geom_line(data=predicted, size=1) # permet d'ajouter le modèle 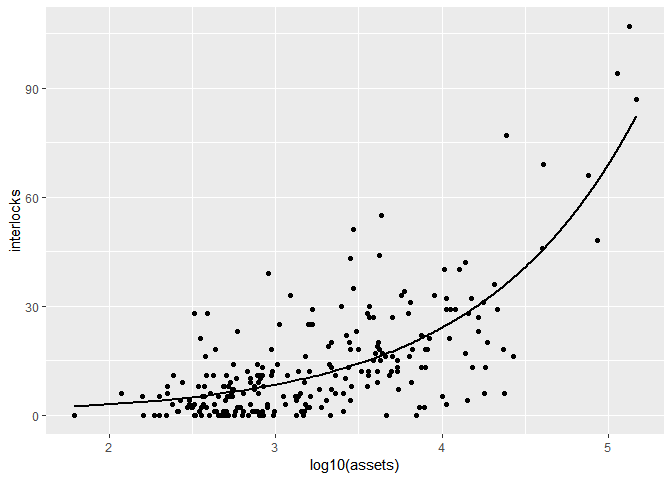
Tutoriel régression de Poisson de type ANOVA à un facteur
Visualisation
Une première visualisation permet d’appréhender les données :
ggplot(Ornstein, aes(x=nation, y=interlocks, fill=nation, colour=nation))+
geom_boxplot(alpha=0.5, outlier.alpha=0)+
geom_jitter() 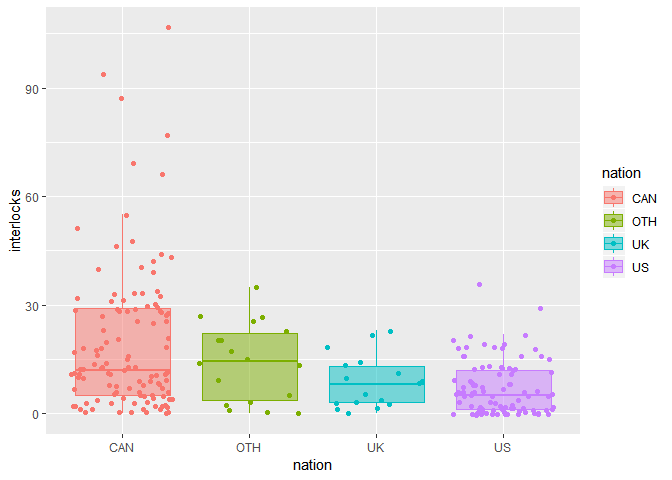
Calcul des moyenne et de leur intervalle de confiance
avg <- Ornstein %>%
group_by(nation) %>%
summarise(avg=mean(interlocks))
avg
## # A tibble: 4 x 2
## nation avg
##
## 1 CAN 19.6
## 2 OTH 14.2
## 3 UK 8.71
## 4 US 7.04 Les intervalles de confiance peuvent être obtenus en employant une approche bootstrap par l’intermédiaire de la fonction slipper() du package slipper.
library(slipper)
set.seed(1234)
Ornstein %>%
filter(nation == "CAN")%>%
slipper(mean(interlocks),B=1000) %>%
filter(type=="bootstrap") %>%
summarize(ci_low = quantile(value,0.025),
ci_high = quantile(value,0.975))
## ci_low ci_high
## 1 15.98996 23.41944
set.seed(1234)
Ornstein %>%
filter(nation == "OTH")%>%
slipper(mean(interlocks),B=1000) %>%
filter(type=="bootstrap") %>%
summarize(ci_low = quantile(value,0.025),
ci_high = quantile(value,0.975))
## ci_low ci_high
## 1 9.333333 19.05556 C’est un peu fastidieux de le faire pour chaque nation, mais au final on obtient :
avg_ci <- data.frame(nation=c("CAN", "OTH", "UK", "US" ),
avg=c(19.6,14.2,8.71,7.04),
binf=c(15.99,9.33,5.65,5.59),
bsup=c(23.42,19.05,11.95,8.49))
avg_ci
## nation avg binf bsup
## 1 CAN 19.60 15.99 23.42
## 2 OTH 14.20 9.33 19.05
## 3 UK 8.71 5.65 11.95
## 4 US 7.04 5.59 8.49 Certains intervalles de confiance ne se chevauchent pas (US et CAN, US et OTH, et CAN et UK). Ceci laisse supposer qu’il existe des différences du nombre de postes moyens entre les nations.
Ajustement du modèle ANOVA de Poisson
Comme précédemment, on utilise simplement la fonction glm() avec l’argument family= »poisson » :
fit_p <- glm(interlocks~nation, data=Ornstein, family="poisson")
Evaluation des hypothèses de la régression de Poisson
Indépendance des réponses
Nous alllons considérer que cette hypothèse est satisfaite
Distribution des réponses selon une loi de Poisson
La représentation graphique réalisée précédemment, dans le chapitre dédié à la régression linéaire simple, nous a déjà permis de conclure que la variable interlocks n’est pas distribuée selon une loi de Poisson de paramètre Lambda = 13.58.
Evaluation de la surdispersion
summary(fit_p)
##
## Call:
## glm(formula = interlocks ~ nation, family = "poisson", data = Ornstein)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -6.2539 -3.2754 -0.8305 1.7922 13.7411
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.97326 0.02091 142.220 < 2e-16 ***
## nationOTH -0.31845 0.06590 -4.832 1.35e-06 ***
## nationUK -0.80926 0.08482 -9.541 < 2e-16 ***
## nationUS -1.02141 0.04378 -23.333 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 3737.0 on 247 degrees of freedom
## Residual deviance: 3064.5 on 244 degrees of freedom
## AIC: 3970.5
##
## Number of Fisher Scoring iterations: 5 Le ratio residual deviance / ddl est égal à 3064.5 /244, soit 12.56. Ce ratio est très largement supérieur à 1 et permet de mettre en évidence la présence d’une surdispersion.
De même, le test de surdispersion disponible dans le package AER, par l’intermédiaire de la fonction dispersiontest , rejette l’hypothèse de l’absence de surdispersion.
library(AER)
dispersiontest(fit_p)
Overdispersion test
data: fit_p
z = 5.3788, p-value = 3.748e-08
alternative hypothesis: true dispersion is greater than 1
sample estimates:
dispersion
13.6299 Au final, il est donc nécessaire d’utiliser une autre structure d’erreur dans le modèle de régression.
Comme précédemment, nous allons pouvoir utiliser les structures d’erreur de type « quasi Poisson » et « negative binomial«
Utilisation d'autres structures d'erreurs
Structure d'erreur quasi poisson
fit_qp <- glm(interlocks~nation, data=Ornstein, family="quasipoisson")
summary(fit_qp)
##
## Call:
## glm(formula = interlocks ~ nation, family = "quasipoisson", data = Ornstein) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -6.2539 -3.2754 -0.8305 1.7922 13.7411 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.97326 0.07781 38.210 < 2e-16 ***
## nationOTH -0.31845 0.24530 -1.298 0.195
## nationUK -0.80926 0.31569 -2.563 0.011 *
## nationUS -1.02141 0.16294 -6.269 1.64e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasipoisson family taken to be 13.85354)
##
## Null deviance: 3737.0 on 247 degrees of freedom
## Residual deviance: 3064.5 on 244 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 5 Structure d'erreur négative binomiale
fit_nb <- glm.nb(interlocks~nation, data=Ornstein) summary(fit_nb)
##
## Call:
## glm.nb(formula = interlocks ~ nation, data = Ornstein, init.theta = 0.9312145192, ## link = log) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.3993 -1.1620 -0.2916 0.4356 2.2374 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.97326 0.09806 30.321 < 2e-16 ***
## nationOTH -0.31845 0.27052 -1.177 0.23912
## nationUK -0.80926 0.28203 -2.869 0.00411 **
## nationUS -1.02141 0.14927 -6.843 7.76e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for Negative Binomial(0.9312) family taken to be 1)
##
## Null deviance: 336.25 on 247 degrees of freedom
## Residual deviance: 289.40 on 244 degrees of freedom
## AIC: 1767.1
##
## Number of Fisher Scoring iterations: 1
##
##
## Theta: 0.9312
## Std. Err.: 0.0915
##
## 2 x log-likelihood: -1757.148 Comme attendu, dans les deux cas, les erreurs standard des paramètres ont été largement augmentées.
Interprétation des résultats
Pour obtenir la table d’analyse de variance, on utilise la fonction Anova() du package « car » :
library(car)
Anova(fit_qp, test="F")
Analysis of Deviance Table (Type II tests)
Response: interlocks
Error estimate based on Pearson residuals
Sum Sq Df F value Pr(>F)
nation 672.5 3 16.181 1.264e-09 ***
Residuals 3380.2 244
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Il est nécessaire de spécifier test= »F » afin d’obtenir un test F et non pas un test du Chi2, réalisé par défaut. Le test F étant le test à utiliser en cas de surdispersion.
Ici, les résultats montrent que deux moyennes, au moins, sont différentes.
Comparaisons multiples
Afin d‘identifier qu’elles sont les différences, nous pouvons réaliser toutes les comparaisons deux à deux à l’aide du package multcomp et de sa fonction glht(). Pour plus de détails, consultez cet article.
library(multcomp)
mc_tukey <- glht(fit_qp, linfct=mcp(nation="Tukey")) summary(mc_tukey) ## ## Simultaneous Tests for General Linear Hypotheses ## ## Multiple Comparisons of Means: Tukey Contrasts ## ## ## Fit: glm(formula = interlocks ~ nation, family = "quasipoisson", data = Ornstein) ## ## Linear Hypotheses: ## Estimate Std. Error z value Pr(>|z|)
## OTH - CAN == 0 -0.3185 0.2453 -1.298 0.5436
## UK - CAN == 0 -0.8093 0.3157 -2.563 0.0459 *
## US - CAN == 0 -1.0214 0.1629 -6.269 <0.001 ***
## UK - OTH == 0 -0.4908 0.3843 -1.277 0.5575
## US - OTH == 0 -0.7030 0.2731 -2.574 0.0447 *
## US - UK == 0 -0.2122 0.3378 -0.628 0.9171
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method) Les comparaisons peuvent alors être visualisées :par(mar=c(3,7,3,3))
plot(mc_tukey) 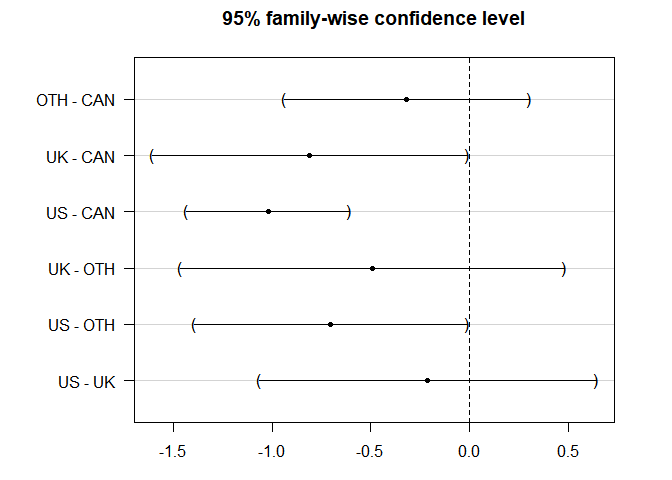
Le package multcomp, contient également une fonction cld() qui permet, dans le cadre du test de Tukey, d’indiquer par des lettres la significativité des comparaisons. Lorsque deux modalités partagent une même lettre, cela signifie que leurs différences ne sont pas significativement différentes. A l’inverse, lorsque deux modalités ne partagent pas de lettres en commun, alors cela signifie que leurs moyennes sont significativement différentes.
tuk.cld <- cld(mc_tukey)
tuk.cld
## CAN OTH UK US
## "c" "bc" "ab" "a" letters <- tuk.cld$mcletters$Letters
myletters_df <- data.frame(nation=levels(Ornstein$nation),letters=letters)
myletters_df
## nation letters
## CAN CAN c
## OTH OTH bc
## UK UK ab
## US US a
ggplot(Ornstein, aes(x=nation, y=interlocks, colour=nation, fill=nation))+
geom_boxplot(outlier.alpha = 0, alpha=0.25)+
geom_jitter(width=0.25)+
stat_summary(fun.y=mean, colour="black", geom="point", shape=18, size=3) +
theme_classic()+
theme(legend.position="none")+
theme(axis.text.x = element_text(angle=30, hjust=1, vjust=1))+
geom_text(data = myletters_df, aes(label = letters, y = 100 ), colour="black", size=5) 
NB : les losanges noirs représentent les moyennes Remarques :
On peut également obtenir les intervalles de confiance des niveaux moyens, comme ceci:
# ajustement du modèle anova sans intercept
fit_qp2 <- glm(interlocks~nation-1, data=Ornstein, family="quasipoisson") summary(fit_qp2) ## ## Call: ## glm(formula = interlocks ~ nation - 1, family = "quasipoisson", ## data = Ornstein) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -6.2539 -3.2754 -0.8305 1.7922 13.7411 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|)
## nationCAN 2.97326 0.07781 38.210 < 2e-16 ***
## nationOTH 2.65481 0.23263 11.412 < 2e-16 ***
## nationUK 2.16400 0.30595 7.073 1.59e-11 ***
## nationUS 1.95184 0.14315 13.635 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasipoisson family taken to be 13.85354)
##
## Null deviance: 15068.8 on 248 degrees of freedom
## Residual deviance: 3064.5 on 244 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 5 Le modèle ayant été ajusté sans intercept (grâce au -1), les coefficients fournis pas la fonction summary() correspondent au log des niveaux moyens de chaque nation. On peut également les obtenir par :
coef(fit_qp2)
## nationCAN nationOTH nationUK nationUS
## 2.973259 2.654806 2.163999 1.951845 Pour les obtenir dans l’échelle originale, c’est à dire en nombre de postes partagés, il est nécessaire d’utiliser la transformation exponentielle :
exp(coef(fit_qp2))
## nationCAN nationOTH nationUK nationUS
## 19.555556 14.222222 8.705882 7.041667 Les intervalles de confiance s’obtiennent alors comme ceci :
exp(confint(fit_qp2))
## 2.5 % 97.5 %
## nationCAN 16.722678 22.691409
## nationOTH 8.683080 21.726223
## nationUK 4.472111 15.016540
## nationUS 5.246187 9.206302 Ils sont légèrement différents de ceux obtenus par bootstrap, cela n’est pas étonnant, car l’approche par bootstrap est basée sur des tirages aléatoires.
J’espère que cet article aura répondu à un grand nombre de questions que vous vous posiez au sujet des GLM pour données de comptage, qu’elles soient d’ordre théorique ou pratique. Si certaines interrogations subsistent, indiquez-les-moi en commentaire, et j’essaierai de vous apporter une réponse.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 
Crédit photo : Clker

Article bien rédigé, très accessible et instructif. Merci bien Claire
Très clair. Merci.
Bonjour Claire. Félicitations et merci pour cet article très bien élaboré qui, à coup sûr, améliorera la compréhension de beaucoup sur les G LM.
merci
Enfin !!!!!! Un document synthétique et simple d’accès !
Merci beaucoup !
Allo ! Merci beaucoup pour cet article ! Enfin je comprends la logique de ce que je fais !
J’aurais néanmoins besoin d’une petite aide: je me suis rendu à la fin de ton article où on peut utiliser les lettres de des comparaisons multiples pour les ajouter sur un graphique réalisé avec ggplot2.
J’ai générée mes lettres sans problèmes mais pour le graphique, j’ai ce message d’erreur :
> myletters_df str(monochamus)
‘data.frame’: 240 obs. of 3 variables:
$ test_de_choix: Factor w/ 6 levels « leg-mod », »leg-mort »,..: 1 1 1 1 1 1 1 1 1 1 …
$ buche : Factor w/ 4 levels « leg », »mod », »mort »,..: 1 2 1 2 1 2 1 2 1 2 …
$ larves : int 0 0 0 0 0 0 18 0 0 0 …
> head(monochamus)
test_de_choix buche larves
1 leg-mod leg 0
2 leg-mod mod 0
3 leg-mod leg 0
4 leg-mod mod 0
5 leg-mod leg 0
6 leg-mod mod 0
Peux-tu m’aider ?
Bonjour
Je vous remercie infiniment pour votre effort de partage. Cet article m’a été d’une aide inestimable sauf que la surdispertion dans mon cas est surtout due à un excès des valeurs zero et j’aimerai réaliser une régression zero-inflated. Si vous avez un article pratique le détaillant je vous serai très reconnaissant car j’admire votre façon très didactique de présenter les choses.
Cordialement et grand merci
Comme toujours, un article bien écrit un grand merci Claire
Très méthodique, explication simplifiée et clair
Merci Claire
Merci Mme
j’aimerais savoir pourquoi vous n’avez pas utilisé toutes les variables explicatives ensemble pour voir les effets?
merci de m’apporter des reponses
Bonjour,
parce que je voulais seulement traiter un exemple simple, alors une seule variable explicative me paraissait suffisant ! Mais vous pouvez en inclure plusieurs.
Bonne continuation.
Bonjour, je suis épidémiologiste et j’ai trouvé ça super utile et très clair. Merci beaucoup
Bonjour,
merci pour cet article détaillé. J’ai cependant une petite difficulté de lecture : les équations dans le texte apparaissent sous une forme étrange : par ex : « $$Pr({Y=y}) = frac{e^{-lambda}; lambda^y}{y;!} $$ ».
bravo et encore merci
bertrand
Je pense que cela est corrigé, car je ne le vois pas.
Bonjour Claire,
merci pour cet article très bien détaillé. Je n’ai pas bien compris quels sont les tests post-hoc adaptés à une GLM poisson. Ici vous présentez le test de Tukey mais j’avais cru comprendre (peut etre à tort) que ce test ne s’appliquait que pour des données de distribution normale ?
Merci d’avance pour cette précision
Vous avez raison si on parle strictement de test de Tukey. Mais si on parle de procédure de Tukey alors le principe est de faire les comparaisonq deux à deux (on peut aussi appeler cela pairwise).
Bonne continuation.
Bonjour Claire,
merci! super clair!
Une question : comment fait-on un glm avec une distribution Poisson mais des données dépendantes ?
merci!
Bonjour
on fait un GLMM (Generalized linear mixed model), ça se fait avec une fonction glmer du package lme4.
Vous trouvez un peu d’aide là : https://bbolker.github.io/mixedmodels-misc/glmmFAQ
C’est pas facile, mais ça se fait !
Bonne continuation