
Lorsqu’on travaille avec des variables qualitatives, c’est-à-dire des variables considérées comme des factor dans R, cela peut être vraiment utile de savoir regrouper certaines modalités.
Par exemple, plusieurs modalités d’une variable qualitative peuvent avoir des effectifs très faibles. Dans cette situation, cela peut avoir du sens (soit du point de vue métier, soit pour ne pas surcharger les sorties) de les regrouper ensemble pour décrire cette variable qualitative.
Une autre situation, peut être la nécessité, dans un graphique, de mettre en avant (d’éclairer) certaines données, par rapport à d’autres. Une technique classique est d’utiliser une couleur vive pour les données à mettre en avant (bleu par exemple), et une couleur neutre (grise, par exemple) pour les autres. Cela peut facilement se faire en créant une variable qui contiendra les regroupements des modalités souhaitées.
Dans cet article, je vous montre 5 fonctions qui sont souvent méconnues, et qui appartiennent au package forcats (qui lui-même appartient au super package tidyverse) et qui permettent de faire très facilement des regroupements de modalités.
Pour illustrer cet article, nous allons employer les données gss_cat qui sont présentes dans le package forcats. Il s’agit d’un échantillon des données d’une enquête sociale générale, menée par l’organisme de recherche indépendant NORC de l’Université de Chicago.
Pour les charger dans R, il suffit d’employer les commandes suivantes :
install.packages("forcats")
library(forcats)
data(gss_cat)
View(gss_cat) Ces données contiennent plusieurs variables catégorielles, qui sont bien considérées comme des facteurs (factor) dans R :
str(gss_cat)
## Classes 'tbl_df', 'tbl' and 'data.frame': 21483 obs. of 9 variables:
## $ year : int 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
## $ marital: Factor w/ 6 levels "No answer","Never married",..: 2 4 5 2 4 6 2 4 6 6 ...
## $ age : int 26 48 67 39 25 25 36 44 44 47 ...
## $ race : Factor w/ 4 levels "Other","Black",..: 3 3 3 3 3 3 3 3 3 3 ...
## $ rincome: Factor w/ 16 levels "No answer","Don't know",..: 8 8 16 16 16 5 4 9 4 4 ...
## $ partyid: Factor w/ 10 levels "No answer","Don't know",..: 6 5 7 6 9 10 5 8 9 4 ...
## $ relig : Factor w/ 16 levels "No answer","Don't know",..: 15 15 15 6 12 15 5 15 15 15 ...
## $ denom : Factor w/ 30 levels "No answer","Don't know",..: 25 23 3 30 30 25 30 15 4 25 ...
## $ tvhours: int 12 NA 2 4 1 NA 3 NA 0 3 Par exemple, si nous nous intéressons à la variable marital, nous pouvons afficher les modalités, ou niveaux, en employant la fonction levels(), ou encore la fonction fct_unique() du package forcats:
levels(gss_cat$marital)
## [1] "No answer" "Never married" "Separated" "Divorced"
## [5] "Widowed" "Married"
fct_unique(gss_cat$marital)
## [1] No answer Never married Separated Divorced Widowed
## [6] Married
## Levels: No answer Never married Separated Divorced Widowed Married Et nous pouvons avoir accès au nombre de données en utilisant la fonction fct_count():
fct_count(gss_cat$marital)
## # A tibble: 6 x 2
## f n
## <fct> <int>
## 1 No answer 17
## 2 Never married 5416
## 3 Separated 743
## 4 Divorced 3383
## 5 Widowed 1807
## 6 Married 10117 Par exemple, nous pourrions souhaiter regrouper les modalités Separated, Divorced dans une même modalité Single, en créant une variable marital2 :
library(tidyverse)
gss_cat <- gss_cat %>%
mutate(marital2 = fct_collapse(marital,
Single=c("Divorced","Separated")))
fct_count(gss_cat$marital2)
## # A tibble: 5 x 2
## f n
## <fct> <int>
## 1 No answer 17
## 2 Never married 5416
## 3 Single 4126
## 4 Widowed 1807
## 5 Married 10117 Et on peut ensuite calculer des statistiques (par exemple l’âge moyen), en groupant d’abord les données selon cette nouvelle variable marital2, comme ceci :
gss_cat %>%
group_by(marital2) %>%
summarise(avg_age=mean(age, na.rm=TRUE))
## # A tibble: 5 x 2
## marital2 avg_age
## * <fct> <dbl>
## 1 No answer 52.4
## 2 Never married 33.9
## 3 Single 50.0
## 4 Widowed 71.7
## 5 Married 48.7 Il est également possible de réaliser plusieurs regroupements, comme ceci :
gss_cat <- gss_cat %>%
mutate(marital2 = fct_collapse(marital,
Single=c("Divorced","Separated"),
Widowed_and_NA=c("Widowed","No answer")))
fct_count(gss_cat$marital2)
## # A tibble: 4 x 2
## f n
## <fct> <int>
## 1 Widowed_and_NA 1824
## 2 Never married 5416
## 3 Single 4126
## 4 Married 10117 Il est encore possible de regrouper ensemble toutes les autres modalités en employant l’argument other_level(), comme ceci, par exemple :
gss_cat <- gss_cat %>%
mutate(marital2 = fct_collapse(marital,
Single=c("Divorced","Separated"),
other_level="other situation"))
fct_count(gss_cat$marital2)
## # A tibble: 2 x 2
## f n
## <fct> <int>
## 1 Single 4126
## 2 other situation 17357 Ce qui permet ensuite de facilement de mettre en avant certaines données avec ggplot2 :
gss_cat %>%
group_by(marital, marital2) %>%
summarise(avg_tv=mean(tvhours, na.rm=TRUE)) %>%
ungroup() %>%
ggplot(aes(x=avg_tv, y=fct_reorder(marital, avg_tv), colour=marital2))+
geom_point(size=3)+
scale_colour_manual(values=c("blue", "grey40"))+
ylab("Marital Statut")+
xlab("Average time watching TV")+
theme_classic() 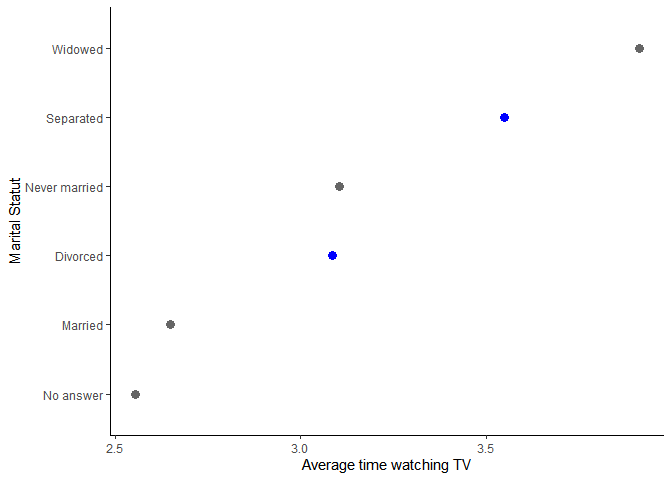
Des regroupements un peu similaires peuvent également être réalisés avec la fonction fct_other(), en employant les arguments keep= ou drop=:
gss_cat <- gss_cat %>%
mutate(marital3=fct_other(marital, keep=c("Divorced", "Separated")))
fct_count(gss_cat$marital3)
## # A tibble: 3 x 2
## f n
## <fct> <int>
## 1 Separated 743
## 2 Divorced 3383
## 3 Other 17357
gss_cat <- gss_cat %>%
mutate(marital4=fct_other(marital, drop=c("Divorced", "Separated")))
fct_count(gss_cat$marital4)
## # A tibble: 5 x 2
## f n
## <fct> <int>
## 1 No answer 17
## 2 Never married 5416
## 3 Widowed 1807
## 4 Married 10117
## 5 Other 4126 La fonction fct_lump_min() permet de regrouper tous les niveaux dont les effectifs sont inférieurs à un nombre min défini.
Par exemple, si nous nous intéressons à la variable relig (religion) :
fct_count(gss_cat$relig)
## # A tibble: 16 x 2
## f n
## <fct> <int>
## 1 No answer 93
## 2 Don't know 15
## 3 Inter-nondenominational 109
## 4 Native american 23
## 5 Christian 689
## 6 Orthodox-christian 95
## 7 Moslem/islam 104
## 8 Other eastern 32
## 9 Hinduism 71
## 10 Buddhism 147
## 11 Other 224
## 12 None 3523
## 13 Jewish 388
## 14 Catholic 5124
## 15 Protestant 10846
## 16 Not applicable 0 Si nous souhaitons regrouper ensemble les religions ayant moins de 200 données, nous pouvons employer les commandes suivantes :
gss_cat <- gss_cat %>%
mutate(relig2=fct_lump_min(relig, min=200))
fct_count(gss_cat$relig2)
## # A tibble: 6 x 2
## f n
## <fct> <int>
## 1 Christian 689
## 2 None 3523
## 3 Jewish 388
## 4 Catholic 5124
## 5 Protestant 10846
## 6 Other 913 Cette fonction permet de regrouper ensemble les modalités dont la proportion relative est inférieure à un seuil défini, donné en argument :
round(prop.table(table(gss_cat$relig)),2)
##
## No answer Don't know Inter-nondenominational
## 0.00 0.00 0.01
## Native american Christian Orthodox-christian
## 0.00 0.03 0.00
## Moslem/islam Other eastern Hinduism
## 0.00 0.00 0.00
## Buddhism Other None
## 0.01 0.01 0.16
## Jewish Catholic Protestant
## 0.02 0.24 0.50
## Not applicable
## 0.00 Par exemple, si nous souhaitons regrouper ensemble toutes les modalités dont la proportion relative est inférieure à 3% :
gss_cat <- gss_cat %>%
mutate(relig3=fct_lump_prop(relig,prop=0.03))
fct_count(gss_cat$relig3)
## # A tibble: 5 x 2
## f n
## <fct> <int>
## 1 Christian 689
## 2 None 3523
## 3 Catholic 5124
## 4 Protestant 10846
## 5 Other 1301 Cette fonction permet de garder de façon individuelle les n modalités les plus fréquentes, et de regrouper les autres. Nous allons ici garder les 3 modalités les plus fréquentes et regrouper toutes les autres :
gss_cat %>%
group_by(relig) %>%
count(sort=TRUE)
## # A tibble: 15 x 2
## # Groups: relig [15]
## relig n
## <fct> <int>
## 1 Protestant 10846
## 2 Catholic 5124
## 3 None 3523
## 4 Christian 689
## 5 Jewish 388
## 6 Other 224
## 7 Buddhism 147
## 8 Inter-nondenominational 109
## 9 Moslem/islam 104
## 10 Orthodox-christian 95
## 11 No answer 93
## 12 Hinduism 71
## 13 Other eastern 32
## 14 Native american 23
## 15 Don't know 15 gss_cat <- gss_cat %>%
mutate(relig4=fct_lump_n(relig,n=3))
fct_count(gss_cat$relig4)
## # A tibble: 4 x 2
## f n
## <fct> <int>
## 1 None 3523
## 2 Catholic 5124
## 3 Protestant 10846
## 4 Other 1990 J’espère vous avoir fait découvrir au moins une nouvelle fonction de regroupement de modalités !
Vous trouverez plus de fonctions dédiées à la gestion des facteurs, notamment pour les réordonner, sur la page d’aide (cheatsheet) du package forcats. Elle est téléchargeable sur le site de RStudio : https://rstudio.com/resources/cheatsheets/

Vous trouverez des exemples de modifications de l’ordre des modalités dans mon article : Comment modifier l’ordre d’affichage d’un plot ?
Si cet article vous a plu, ou vous a été utile, vous pouvez le partager, et soutenir le blog en réalisant un don libre sur la page Tipeee.


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
Une réponse