Pour tirer pleinement profit de cet article d’introduction aux tests statistiques d’équivalence, il est nécessaire d’être familier avec le principe des tests statistiques, et notamment connaitre les notions d’hypothèses, de statistique du test, de risque alpha, de p-value, et de conclusion).
Si cela n’est pas le cas, vous pourrez trouver un rappel des principaux éléments dans mon article d’introduction à la puissance statistique.
Les tests statistiques classiques, ne permettent de conclure que sur la présence d’une différence. C’est le cas, par exemple, des tests employés pour comparer deux moyennes, comme le test de Student, ou le test de Wilcoxon. Ces tests ne permettent de conclure que sur la différence, car si leur hypothèse nulle est rejetée, on conclura à la présence d’une différence. Alors que si cette hypothèse nulle n’est pas rejetée, on ne conclura pas à l’absence de différence. On dira seulement que « rien ne permet de conclure à la différence« . L’absence de mise en évidence de la différence pouvant être due à une réelle absence d’effet, mais aussi peut être à un manque de puissance.
Ces tests, dits de supériorité, sont, par exemple, utilisés mettre en évidence une plus grande efficacité d’un traitement, par rapport à celle d’un placebo.
Or, dans certaines situations, nous aimerions conclure sur l’équivalence de deux traitements, non pas sur leur différence.
Cela pourrait être le cas si un nouveau traitement coûte deux fois moins cher à produire, que le traitement de référence. Avant de mettre ce nouveau médicament sur le marché, il est nécessaire d’évaluer si son efficacité est équivalente à celle du traitement de référence. Et dans cette situation, c’est un test d’équivalence qu’il faut utiliser !
Les tests de supériorité sont basés sur l’opposition de deux hypothèses :
Dans le cadre d’une comparaison de deux moyennes, avec une approche bilatérale, ces hypothèses, s’écrivent :
\[H_0 : \mu_A = \mu_B\]
\[H_0 : \mu_A \neq \mu_B\]
Le principe du test statistique est de calculer une quantité (la statistique du tests) avec les données observées, puis de regarder où se situe cette valeur sur la distribution théorique, qui est connue, de cette statistique. Cette distribution théorique est celle sous l’hypothèse nulle que les moyennes sont égales, elle est donc centrée sur 0.
Par exemple, la statistique du test de Student est :
\[T_{n_A+n_B-2} = \frac{m_{A} – m_{B}}{\sqrt{s^2 (\frac{1}{n_A}+\frac{1}{n_B})}}\]
Ou s² est la variance poolée :
\[s^2 = \frac{(n_{A}-1)s_{A}^2\;+(n_{B}-1)s_{B}^2}{(n_{A} + n_{B} -2)}\]
La distribution théorique de cette statistique est une distribution de Student centrée sur 0 à n_A + n_B-2 paramètres.
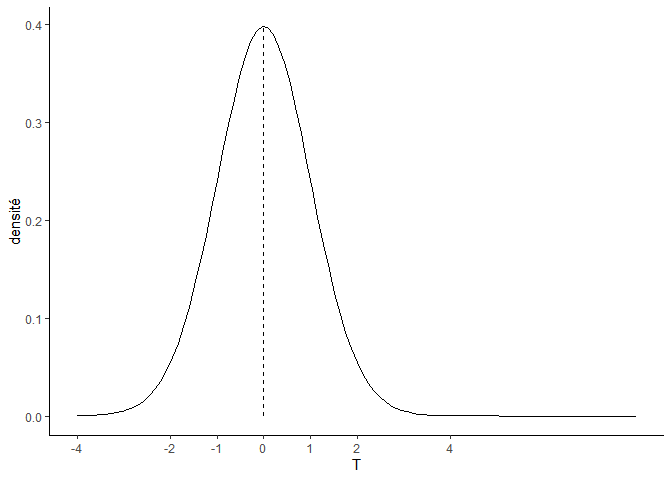
Le risque alpha (ou risque de première espèce), est le risque que l’on prend, de se tromper en concluant à tort au rejet de l’hypothèse nulle. Il est généralement fixé à 5%. Dans un test bilatéral ces 5% sont répartis de part et d’autre de la courbe de distribution:

Si la statistique calculée dépasse les valeurs critiques (les barres rouges verticales) définies en fonction du risque alpha, alors l‘hypothèse nulle est rejetée, et on conclut à la présence d’une différence :

En revanche, si la statistique calculée est comprise entre les deux valeurs critiques alors l‘hypothèse nulle n’est pas rejetée :

Mais dans cette situation, on ne conclura pas à l’absence de différence, et encore moins à l’égalité des moyennes !
Cela est dû au fait que l’on ne contrôle pas le risque de se tromper. L’absence de mise en évidence d’une différence pourrait être le résultat d’une absence réelle d’effet, ou bien d’une faible puissance statistique (par exemple, si les échantillons sont de faibles taille).
Ainsi, lorsque l’hypothèse nulle n’est pas rejetée, on ne peut jamais conclure à l’égalité des moyennes.
Une autre approche, dite des intervalles de confiance peut également être employée pour comparer deux moyennes. Il s’agit de calculer l’intervalle de confiance à 95% de la différence des moyennes :
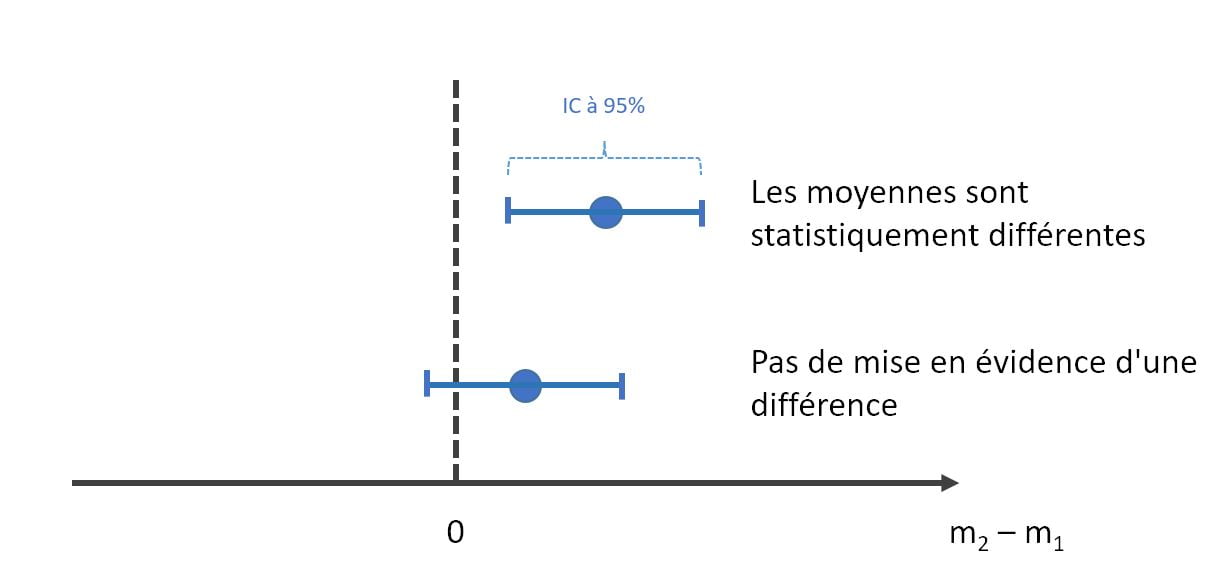
Vous trouverez plus d’informations sur les intervalles de confiance dans l’article Fluctuations d’échantillonnage et biais.
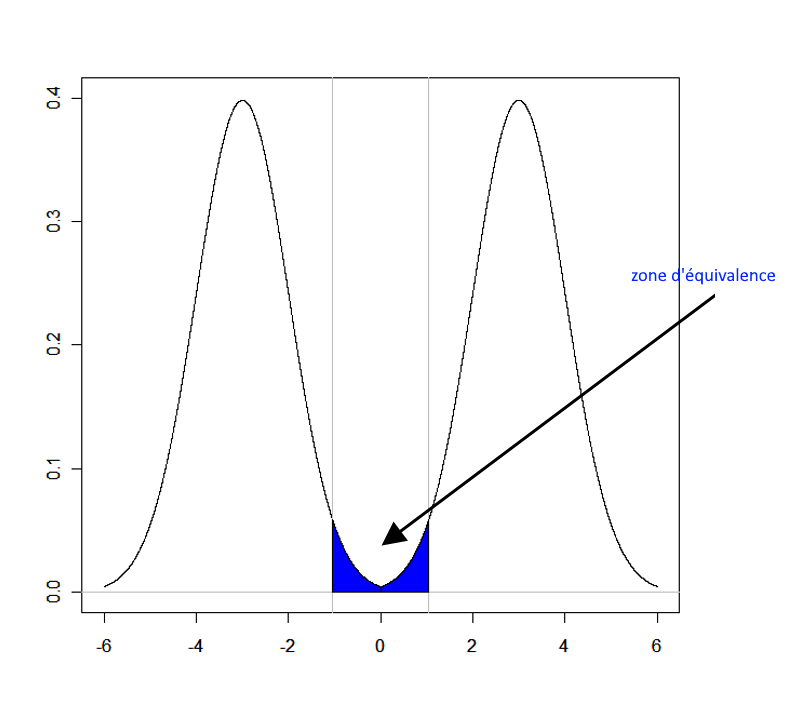
Pour évaluer l’équivalence, il est nécessaire, dans un premier temps, de fixer des bornes d’équivalence.
Ces bornes d’équivalence vont permettre de définir un intervalle d’équivalence, c’est-à-dire une étendue à l’intérieure de laquelle la différence entre deux moyennes sera considérée comme négligeable.
Les valeurs de ces bornes, généralement symétriques, sont un peu subjectives. Elles dépendent totalement du domaine d’application.
C’est pour cela que ce n’est pas à un biostatisticien-ne de les définir, mais bien à un spécialiste (voir un consensus de spécialistes), de l’effet observé (généralement des médecins).
Ces bornes sont fréquemment notées delta_L (L pour lower) et delta_u (U pour upper):

Pour donner un exemple, ces bornes peuvent être +/- 20% de m1 (si m1 représente la moyenne du traitement de référence). Donc si m1=10, les bornes peuvent être 8 et 12. Exprimées en termes de différences entre m2 et m1, les bornes peuvent être -2 et +2.
Pour évaluer l’équivalence de deux moyennes, ce qu’il nous faudrait, c’est un test basé sur
\[H_0 : \mu_1 \neq \mu_0 \;\text{(ou non-équivalence)}\]
\[H_1 : \mu_1 = \mu_0 \;\text{(ou équivalence)}\]
Comme cela, en rejetant H0, on pourrait conclure à l’équivalence.
Mais cette simple inversion des hypothèses n’est pas possible, car on ne peut pas connaître la valeur sur laquelle serait centrée la distribution théorique (il s’agirait de la vraie différence standardisée entre les deux traitement).
Face à ce problème, la solution consiste à utiliser deux tests classiques unilatéraux, combinés. C’est ce qu’on appelle la procédure TOST pour Two One-Sided Tests.
Le premier test va consister à tester si la différence observée est significativement supérieure à la borne inférieure au risque de 5% :
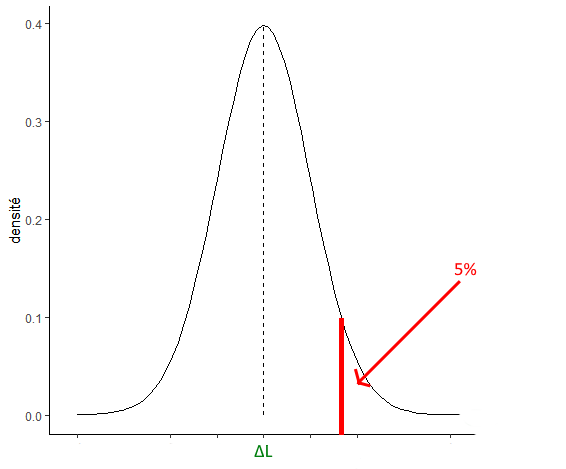
D’habitude, on test si une différence est significativement différente de 0. Ici pour tester si la différence est significativement différente de la borne inférieure (qui n’est pas égale à 0), on va simplement décentrer la statistique en soustrayant la borne inférieure. La statistique du test devient alors :
\[T_{n_A+n_B-2} = \frac{m_{A} – m_{B}-\Delta_L}{\sqrt{s^2 (\frac{1}{n_A}+\frac{1}{n_B})}}\]
Ainsi si la statistique observée est au-delà de la valeur seuil définie pour le risque de 5%, alors on conclura que la différence des moyennes est significativement supérieure à la borne inférieure d’équivalence (delta_L).
On va ensuite faire un second test pour évaluer si la différence est inférieure à la borne supérieure :

Ainsi si la statistique observée est au delà de la valeur seuil définie pour le risque de 5%, alors on conclura que la différence des moyennes est significativement inférieure à la borne supérieure d’équivalence (delta_U).
Au final, si la différence observée est à la fois supérieure à la borne inférieure et inférieure à la borne supérieure, alors c’est qu’elle est contenue dans l’intervalle d’équivalence. Et dans cette situation, on conclura à l’équivalence.
De façon similaire à l’évaluation d’une différence, une approche par intervalle de confiance peut être employée pour évaluer l’équivalence de deux moyennes.
Dans cette situation, on calculera les intervalles de confiance à 90% de la différence des deux moyennes. Et on confluera à l’équivalence seulement si cet intervalle de confiance ne chevauche aucune des bornes d’équivalence. Autrement dit, si l’intervalle de confiance est pleinement inclu dans l’intervalle d’équivalence.

Je vous conseille deux publications :
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
9 réponses
Encore un article super intéressant et inspirant. 1000 mercis
Salut Claire , super article vraiment bien merci à vous et surtout prenez soin de vous et de vos proches
Bonjour Claire! J’ai beaucoup aimé cet article où j’ai retenu surtout comment conclure lorsque l’hypothèse nulle n’est pas rejetée!
Super article ! Je ne connais pas les procédures que tu présentes et tu explicites bien ce problème statistique d’équivalence auquel on ne fait pas forcément attention
Bonjour Chère Claire,
Un grand merci pour cet article qui me fait découvrir l’aspect de l’équivalence que je ne connaissais pas.
Un grand merci pour ce nouvelle article, précis et très bien à synthétisé comme à chaque fois.
Bonjour,
Super article très fourni ! Petite question : est-ce que cela change quelque chose au niveau de la programmation des analyses stat ensuite ?
Merci
Bonjour, c’est super
Vous pouvez nous aider à l’application sur le logiciel R
Bonjour Lionel,
j’aimerais effectivement rédiger un tutoriel, avec la mise en application.
Je ne sais pas quand je pourrai le faire, alors d’ici là vous pouvez regarder du côté du package TOSTER : https://cran.r-project.org/web/packages/TOSTER/index.html
Sinon, il me semble que les tests d’équivalence sont réalisables sur Jamovi (peut être aussi jasp).
Bonne continuation