Je vous propose ici un court article pour illustrer, à travers un exemple simple, la différence entre fluctuations d’échantillonnage et biais.
Imaginons que l’on souhaite connaître la taille réelle moyenne des garçons de 8 ans, en France. Autrement dit, la taille moyenne de la population constituée par tous les garçons de 8 ans en France. Cette moyenne est inconnue en réalité. Mais pour cet exemple, nous allons imaginer qu’elle est égale à 129 cm.
Puisque cette moyenne est en réalité inconnue, et que l’on ne peut pas mesurer tous les garçons de 8 ans un par un, le principe consiste à estimer cette moyenne à partir d’un échantillon. Par exemple, 50 (par exemple) garçons de 8 ans vont être choisis au hasard sur tout le territoire (afin que l’échantillon soit représentatif de la population). Puis ils vont être mesuré individuellement. Et enfin, la moyenne de l’échantillon, c’est-à-dire des 50 mesures, va être calculée pour estimer la moyenne de la population des garçons de huit ans.
Simulons cela avec des données. Il est très vraisemblable que la taille des garçons suivent une loi normale, de moyenne 129 cm (puisque nous avons convenu que c’est la valeur de la vraie moyenne), et d’écart type (s) de 2.5 cm (là aussi convenons que c’est la vraie valeur).
Nous allons donc simuler 50 données de taille de garçon de 8 ans selon cette loi normale :
options(digits=5)
x1 <- rnorm(50,129,2.5)
x1
## [1] 127.43 129.46 126.91 132.99 129.82 126.95 130.22 130.85 130.44 128.24
## [11] 132.78 129.97 127.45 123.46 131.81 128.89 128.96 131.36 131.05 130.48
## [21] 131.30 130.96 129.19 124.03 130.55 128.86 128.61 125.32 127.80 130.04
## [31] 132.40 128.74 129.97 128.87 125.56 127.96 128.01 128.85 131.75 130.91
## [41] 128.59 128.37 130.74 130.39 127.28 127.23 129.91 130.92 128.72 131.20 Puis nous calculer la moyenne de cet échantillon :
mean(x1)
## [1] 129.25 Nous pouvons observer que la moyenne obtenue est proche de 129, mais sans être strictement égale à 129.
Imaginons, à présent, que pour une raison ou une autre, il faille à nouveau ré-échantillonner 50 garçons de 8 ans. Ces nouveaux 50 garçons seront un peu différents des 50 premiers garçons
x2 <- rnorm(50,129,2.5)
x2
## [1] 126.76 129.46 132.97 126.17 128.80 129.33 130.77 128.40 133.96 128.65
## [11] 130.04 131.45 128.02 126.40 133.46 123.22 131.20 129.09 131.53 130.08
## [21] 134.23 126.00 132.97 133.89 129.01 122.87 130.19 127.51 130.98 129.72
## [31] 130.85 129.80 131.69 128.29 127.06 127.51 124.69 126.74 127.60 128.38
## [41] 128.04 124.10 126.90 133.76 130.56 133.98 128.24 128.77 128.54 126.00 La moyenne des tailles sera donc aussi un peu différente :
mean(x2)
## [1] 129.17 La nouvelle moyenne estimée est également proche de 129, mais sans être strictement égale à 129, ni strictement identique à la première moyenne estimée.
Recommençons alors 10 fois l’expérience :
m_hat_vec <- vector(length=10)
for ( i in 1 : 10)
{
x <-rnorm(50, 129,2.5)
m_hat_vec[i] <- mean(x)
}
m_hat_vec
## [1] 128.67 129.45 128.70 129.47 129.25 129.68 129.89 128.50 128.77 129.61 Et visualisons les moyennes estimées sur un graphique :
m_hat_df <- data.frame(m_hat_vec )
library(ggplot2)
ggplot(m_hat_df, aes(y=m_hat_vec,x=1 ))+
geom_point(size=3)+
coord_flip()+
scale_y_continuous(limits=c(127,131))+
scale_x_continuous(limits=c(0.975, 1.025), breaks=NULL)+
xlab("")+
geom_point(x=1, y=129, size=5, colour="red")+
theme_bw() 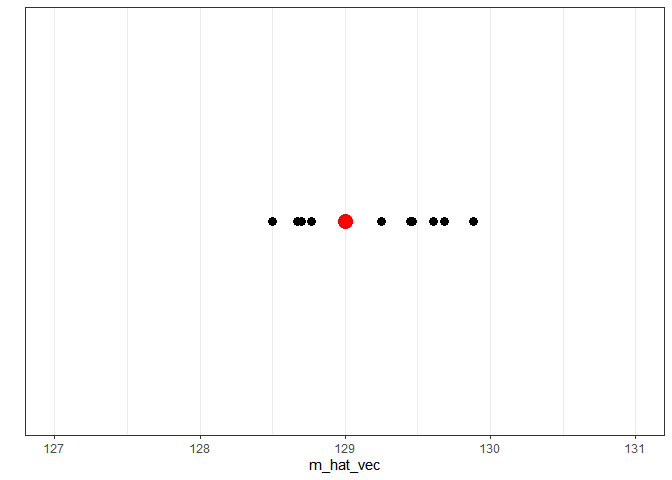
Nous pouvons voir que les 10 moyennes estimées sont toujours un peu différentes de la vraie moyenne, et que ces différences, que l’on peut considérer comme des erreurs, sont aléatoires (parfois un peu inférieures, parfois un peu supérieures). Autrement dit, les fluctuations d’échantillonnage entraînent des erreurs aléatoires dans l’estimation des paramètres (dans notre cas, une moyenne).
Et ces erreurs, sont nulles en moyenne, puisqu’elles sont aléatoirement un peu inférieure ou un peu supérieures. Autrement dit, en moyenne les estimations de la moyenne de la population sont égales à la vraie moyenne. Pour illustrer ce point, simulons 1000 moyennes:
options(digits=7)
m_hat_vec2 <- vector(length=1000)
for ( i in 1 : 1000)
{
x <-rnorm(50, 129,2.5)
m_hat_vec2[i] <- mean(x)
} Et calculons la moyenne de ces 1000 moyennes estimées :
mean(m_hat_vec2)
## [1] 128.9939 Vous conviendrez que c’est extrêmement proche de 129 !
my_m_hat <- mean(x1)
my_m_hat
## [1] 129.2511
my_s_hat <- sd(x1)
my_s_hat
## [1] 2.078485
n <- 50
binf <- my_m_hat -1.96*my_s_hat/sqrt(50)
binf
## [1] 128.675
bsup <- my_m_hat +1.96*my_s_hat/sqrt(50)
bsup
## [1] 129.8272 Soit ici [ 128.6, ; 129.83].
Une autre façon d’envisager l’intervalle de confiance à 95% est de dire que si on recommençait 100 fois l’expérience de l’échantillonnage, de l’estimation de la moyenne, et de l’estimation de son intervalle de confiance, alors 95 intervalles sur 100 contiendront la vraie valeur de la moyenne (fixée et inconnue) et 5 ne la contiendront pas.
Lorsqu’il n’existe pas de formule pour calculer l’intervalle de confiance d’un paramètre, cet intervalle peut être estimé par des techniques de ré-échantillonnage (bootstrap). Pour cela, on peut par exemple utiliser le package slipper comme ça :
devtools::install_github('jtleek/slipper')
library(slipper)
taille_df <- data_frame(taille=x1) taille_df %>%
slipper_ci(mean(taille),B=100, lower=0.025, upper=0.975)
## ci_low ci_high
## 1 128.6075 129.8037 On peut voir que les deux intervalles de confiance sont très proches.
Nous venons de le voir, les erreurs engendrées par les fluctuations d’échantillonnage ont un caractère aléatoire. Les erreurs causées par les biais, au contraire, sont des erreurs systématiques.
Pour l’illustrer, imaginons que la personne en charge de choisir aléatoirement 50 garçons de 8 ans sur l’ensemble du territoire français, réalise en réalité un tirage au sort sur quelques départements réputés pour la grande taille de leurs habitants.
Dans cette situation, l’échantillon des 50 garçons de 8 ans n’est pas représentatif de la population, il y a alors un biais de sélection. La conséquence de ce biais est une surestimation systématique la taille de la population des garçons de 8 ans.
En voici une simulation :
m_hat_vec3 <- vector(length=10)
for ( i in 1 : 10)
{
x2 <-rnorm(50, 132,2.5)
m_hat_vec3[i] <- mean(x2)
}
m_hat_vec3
## [1] 132.0925 131.4560 132.2760 132.0532 132.3859 131.2164 131.6312
## [8] 131.7636 131.8795 131.8276
m_hat_df <- data.frame( m_hat_vec3) library(ggplot2)
ggplot(m_hat_df, aes(y=m_hat_vec3,x=1))+
geom_point(size=3, show.legend = FALSE, colour="blue")+
coord_flip()+
scale_y_continuous(limits=c(127,137))+
scale_x_continuous(limits=c(0.975, 1.025), breaks=NULL)+
geom_point(x=1, y=129, size=5, colour="red", show.legend = FALSE)+
scale_colour_manual(values=c("black", "blue"))+
theme_bw() 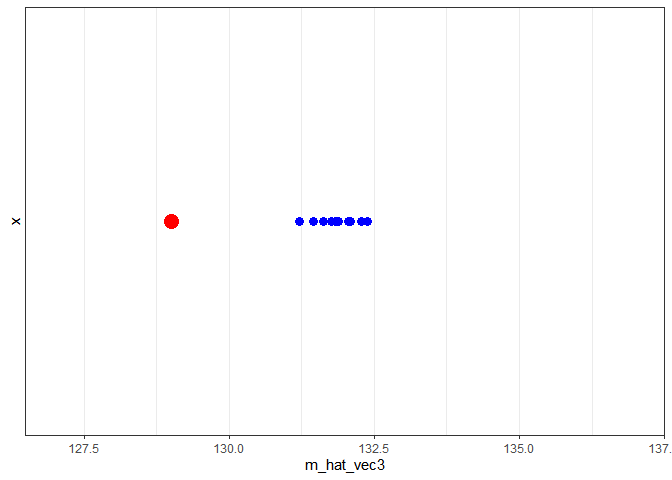
La notion de biais est particulièrement importante en épidémiologie étiologique, lorsqu’on cherche à mesurer la force d’un lien entre une exposition et une maladie, par l’intermédiaire du calcul d’odds ratio ou des risque relatifs. En effet, de nombreux types de biais peuvent entacher cette relation. Ils sont classiquement regroupés en trois grandes familles :
A l’intérieur des ces 3 grandes familles de bais, il en existe plusieurs sous catégories en fonction du type d’étude (cohorte, cas témoin ou transversale).
Si ce sujet vous intéresse, je vous recommande vivement de lire le livre du Docteur Alexis Clapin, “Enquêtes médicales et évaluation des médicaments : De l’erreur involontaire à l’art de la fraude”.

Ce livre est très pédagogique, très agréable à lire et et les exemples employés pour décrire les différents biais des études épidémiologiques sont très parlants.
J’espère que ce court article permettra aux débutant de mieux distinguer ces deux notions de fluctuations d’échantillonnage, associés à des erreurs aléatoires, et de biais, associés à des erreurs systématique.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photos : Image par 3D Animation Production Company de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
6 réponses
merci bon article
Bonjour,
A propos de la formulation de l’intervalle de confiance à 95%. Je dirais plutôt que 95 intervalles sur 100 contiendront la vraie valeur de la moyenne (fixé et inconnue) et 5 ne la contiendront pas.
Cordialement.
LD
Bonjour,
Vous avez raison, j’ai corrigé.
Merci
Bonjour,
Article très intéressant. Merci pour le temps que vous consacré toujours à nous fournir des articles de très haute qualité.
Cordialement!
merci bcp pour vos articles très intéressants
Merci beaucoup.