ANOVA à 2 facteurs : principe
Dans l’article d’introduction à l’ANOVA à 2 facteurs, nous avons vu que le principe de cette approche consiste, dans un premier temps, à décomposer la dispersion totale des données, en quatre origines :
- la part imputable au premier facteur,
- la part imputable au second facteur,
- la part imputable à l‘interaction des 2 facteurs,
- la part non expliquée, ou résiduelle.
Puis, dans un second temps, à évaluer, à l’aide d’un test statistique, si les parts factoriels, et celle relative à l’interaction, sont significativement supérieures à la part résiduelle.
Dans cette article, nous allons aborder les éléments calculatoires de l’ANOVA à 2 facteurs. Pas de panique pour ceux qui ont la phobie des formules mathématiques ! Elles sont seulement là, pour ceux qui aiment avoir tout sous les yeux. Si vous ne les comprenez pas, ce n’est pas grave. Ce qui est important c’est seulement de comprendre le principe de l’approche.
Table des matières
Data
A titre d’illustration nous allons utiliser un jeu de données que j’ai simulé en m’inspirant du jeu de données warprbreaks (du package dataset, chargé par défaut). Nous allons imaginer que ces données sont issues d’un plan d’experience visant à observer l’usure de la laine (dans une unité de votre choix) au sein de metiers à tisser, en fonction de la tension du fil et du type de laine.
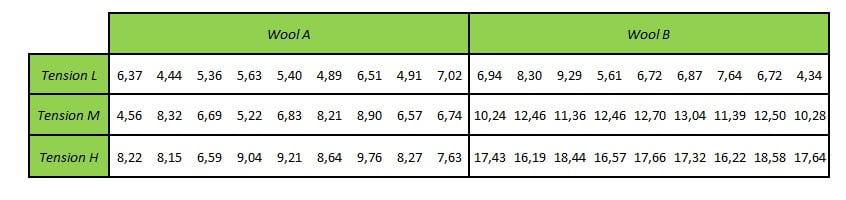

Remarque : j’ai préféré simuler des données plutôt que d’utiliser les données originales, car dans ces dernières, la variable réponse est un Usure. Il s’agit d’une donnée de comptage, qui en toute rigueur, s’analyse avec un modèle linéaire généralisé et pas une ANOVA.
Calcul des différentes parts de dispersion
Notations
- Avant de commencer, il est nécessaire de poser certaines bases :
- La première variable catégorielle étudiée (elle est souvent appelée facteur A) possède “a” modalités. Ici, cette variable est le tension, et a = 3.
- L’indice des modalités de cette première variable catégorielle est “i”. Ici, l’indice i va de 1 à a
- La seconde variable catégorielle étudiée (elle est souvent appelée facteur B) possède “b” modalités. Ici, cette variable est le type de laine (wool), et b = 2.
- L’indice des modalités de cette seconde variable catégorielle est “j”. Ici l’indice j va de 1 à b.
- Le nombre d’observations au sein de chaque cellule du plan factoriel est noté n_ij. Ici, le plan factoriel est équilibré et n_ij est toujours égale à 9.
- Le nombre total d’observations, est noté N :
\[
N=\sum_{i=1}^{a} \sum_{j=1}^{b}\left(n_{i j}\right)
\]
- Les observations dans chaque cellule du plan factoriel (cad au niveau de chaque croisement de modalité), sont notées y_ijk. k est l’indice de la répétition au sein de chaque croisement.Ici comme le plan est équilibré, k va toujours de 1 à 9.
- La moyenne globale des réponses (appelée aussi Grand Mean) est notée y_barre_point_point :

Les points correspondent aux indices de la première et de la seconde variable catégorielle.
- les moyennes de chaque croisement de modalités sont notées y_barre_ij :
\[ \overline{y}_{ij} = \frac{1}{n_{ij}} \sum_{k=1}^{n_{ij}} (y_{ijk}) \]
- Les moyennes marginales des modalités de la première variable sont notées y_barre_i_point:
\[ \overline{y}_{i\cdot} = \frac{1}{b} \sum_{j=1}^{b} \overline{y_{ij}} \]
Par exemple, la moyenne marginale associée à la tension L, correspond à la somme des moyennes des usures observées pour les laines de type A et B, divisée par 2.
- Les moyennes marginales des modalités de la seconde variable sont notées y_barre_point_j
\[ \overline{y}_{\cdot_j} = \frac{1}{a} \sum_{i=1}^{a} \overline{y_{ij}}\]
- Les effectifs marginaux des modalités de la première variable sont notées n_i_point :
\[ n_{i\cdot} = \sum_{j=1}^{b} n_{ij} \]
- Les effectifs marginaux des modalités de la seconde variable sont notées n_point_j :
\[ n_{\cdot_j} = \sum_{i=1}^{a} n_{ij} \]
Calcul de la dispersion totale des données
La première étape de l’ANOVA à 2 facteurs, consiste à mesurer la dispersion totale des données, en employant comme paramètre la somme des distances au carré, entre chaque observation et la moyenne globale (ou Grand Mean). On appelle ce paramètre la Somme des Carrés Totaux (SCT). En, anglais on l’apelle Total Sum of Squares, son abréviation est SST.
\[\text{SCT} = \sum_{i=1}^{a}\sum_{j=1}^{b}\sum_{k=1}^{n_{ij}]} (y_{ijk} – \overline{y}\cdot\cdot)^2 \]

Décomposition de la dispersion totale
La part de dispersion imputable au premier facteur
La part de dispersion imputable au premier facteur (ici la Tension du fil) est notée SCA, pour Somme des Carré du facteur A. En anglais, on la nomme souvent SSA pour “Sum of Squares”. Elle se mesure par la somme des distances au carré entre les moyennes marginales du facteur A et la moyenne générale (Grand Mean).
\[\text{SCA} = bn\sum(\overline{y}_{i\cdot} – \overline{y}\cdot\cdot)^2 \]
Pour simplifier la notation n est ici le nombre d’observations par condition (ou croisement des modalités)

La part de dispersion imputable au second facteur
La part de dispersion imputable au second facteur (ici la laine) est notée SCB, pour Somme des Carré du facteur B. En anglais, on la nomme souvent SSB pour “Sum of Squares”. Elle se mesure par la somme des distances au carré entre les moyennes marginales du facteur B et la moyenne générale (Grand Mean). Ici, la seconde variable est la laine (Wool).
\[\text{SCB} = an\sum(\overline{y}_{\cdot \;i} – \overline{y}\cdot\cdot)^2 \]
Pour simplifier la notation n est ici le nombre d’observations par condition (ou croisement des modalités)

Les segments bleus horizontaux représentent la moyenne marginale de la laine de type A, et les segments oranges horizontaux représentent la moyenne marginale de la laine de type B.
La part de dispersion imputable à l'interaction
Cette part de dispersion, notée SSAB, se calcule par différence, comme ceci :
\[\text{SCAB} = n\sum(\overline{y}_{ij} – \overline{y}\cdot\cdot)^2 \;-SCA\;-SCB \]
Le premier terme consiste à calculer la somme des écarts au carré entre la moyenne de la condition (ou croisement des modalités) de chaque observation, et la moyenne générale. On peut visualiser cette quantité comme ceci :

La part de dispersion imputée au bruit (résidus)
La part de dispersion résiduelle, imputée au bruit, est notée SCR, pour Somme des Carré Résiduels. En anglais, on la nomme souvent SSR pour “Sum of Squares of Residuals”. Elle se mesure par la somme des distances au carré entre chaque observation et la moyenne de la condition à la quelle elle appartient.
\[SCR = \sum_{i=1}^{a}\sum_{j=1}^{b} (y_{ijk}\; -\overline{y}_{ij} )^2\]

Calcul des variances factorielles, d'interaction et résiduelle
Après avoir calculé les sommes des carrés factoriels d’interaction, et résiduels, il est nécessaire de calculer les variances de ces quatre sources de variations. La variance n’est rien d’autre que la Somme des Carrés divisée par son nombre de degrés de liberté (degrees of freedom en anglais).
En pratique, les nombres de degrés de libertés sont :
- a-1 pour le premier facteur (Tension),
- b-1 pour le second facteur (Wool),
- (a-1)(b-1) pour l’interaction,
- ab(n-1) pour la part résiduelle..
Les variances calculées ici sont aussi appelées Carrés Moyens, ou Mean Squares en anglais.
\[\text{Variance Factorielle A} = \frac{SCA}{a-1} \]
\[\text{Variance Factorielle B} = \frac{SCB}{b-1} \]
\[\text{Variance Factorielle AB} = \frac{SCAB}{(a-1)(b-1)} \]
\[\text{Variance Residuelle} = \frac{SCR}{ab(n-1)} \]
Tests statistiques
Des tests statistiques d’hypothèses, sont ensuite réalisés pour évaluer si chacune des trois parts de variances est significativement supérieure à la variance résiduelle. Si c’est le cas, on conclura à la significativité de l’effet considéré (celui du facteur A, celui du facteur B ou celui de l’interaction). Le principe étant de se dire que si les données sont plus dispersées que le niveau de base (représenté par la variance résiduelle) alors c’est que quelque chose est responsable de cette dispersion : le facteur étudié.
Ces tests statistiques sont des tests F de rapport de 2 variances.
Test relatif au facteur A:
\[ FA_{(a-1\;,\;a b(n-1)} =\frac{ \frac{SCA}{(a-1)}}{\frac{SCR}{ab(n-1)}} \]
Test relatif au facteur B:
\[ FB_{(b-1\;,\;a b(n-1)} =\frac{ \frac{SCB}{(b-1)}}{\frac{SCR}{ab(n-1)}} \]
Test relatif à l’interaction des facteurs A et B:
\[ FAB_{(a-1)(b-1)\;,\;a b(n-1)} =\frac{ \frac{SCAB}{(a-1)(b-1)}}{\frac{SCR}{ab(n-1)}}\]
Sous certaines hypothèses (normalité et homogénéité des résidus (écarts entre les observations et les moyennes des groupes), la statistique du test F suit un loi de Fisher à :
- (a-1) et ab(n-1) degrés de liberté pour les test relatif au facteur A
- (b-1) et ab(n-1) degrés de liberté pour les test relatif au facteur B
- (a-1)(b-1) et ab(n-1) degrés de liberté pour les test relatif à l’interaction des facteurs A et B.
Ensuite, de façon classique, le logiciel calcule la probabilité, sous l’hypothèse nulle H0, d’observer une telle valeur F, c’est la p-value. Ensuite, c’est à nous de comparer cette p-value au seuil de significativité choisi (il est généralement fixé à 5%, mais dans certains contextes, il peut parfois être fixé à 1% par exemple). Si la p-value est inférieure au seuil de significativité, on conclura à la significativité de l’effet propre. Sinon, on ne conclura pas à l’absence d’effet, mais à l‘absence de mise en évidence de l’effet. Il est possible, par exemple, que les échantillons soient de trop faibles tailles pour parvenir à mettre en évidence une différence significative.
Présentation des résultats
Les résultats de l’ANOVA à 2 facteurs sont généralement présentés dans une table d’analyse de variance, comme ceci :
| Source | Somme des carrés | ddl | Carrés Moyens | Fvalue | pvalue |
|---|---|---|---|---|---|
| Facteur A | SCA | a-1 | SCA / (a-1) | FA | pA |
| Facteur B | SCB | b-1 | SCB / (b-1) | FB | pB |
| Facteur AB | SCAB | (a-1)(b-1) | SCAB /(a-1)(b-1) | FAB | pAB |
| Résidus | SCR | N-k | SCR / (N-1) | p | |
| Total | SCT | N-1 |
Interprétation des résultats
Pour interpréter les tests, on commence par celui de l’interaction.
Lorsqu'une interaction qualitative est significative
Lorsque l’interaction est de type qualitative (c’est à dire que les profils d’évolution se croisent, et que le test est significatif, il n’est plus possible d’interpréter les tests relatifs aux facteurs A et B.

Dans ce cas de figure, on peut :
- recoder les conditions ( ci, L_A, L_B, M_A, M_B, H_A et H_B par exemple), et simplement comparer les moyennes des différentes conditions avec une ANOVA à un facteur.
- fixer les modalités d’un des facteurs et comparer les moyennes relatives aux modalités de l’autre facteur. Par exemple, ne considérer que les données de la laine de type A et comparer les moyennes des tensions L, M et H avec une ANOVA à un facteur. Puis idem avec le type B.
Lorsqu'une interaction quantitative est significative

Il est généralement admis, que dans cette situation, les effets propres des facteurs peuvent être interprétés. Lorsque l’effet d’un facteur est significatif, des comparaisons multiples sont ensuite généralement réalisées pour comparer les moyennes des modalités de chaque facteur.
Lorsque l'interaction (qualitative ou quantitative) n'est pas significative

Dans cette situation les effets propres des facteurs A et B peuvent être interprétés, mais pas directement. En effet, au préalable, l’ANOVA à 2 facteurs doit être réalisée à nouveau, mais sans prendre en compte l’interaction, puisque celle-ci n’est pas significative. Ensuite, si l’effet d’un facteur est significatif, des comparaisons multiples sont réalisées pour comparer les moyennes des modalités de chaque facteur.
Le modèle ANOVA à 2 facteurs est un modèle linéaire
Bien que cela ne soit pas complètement intuitif aux premiers abords, l’ANOVA à 2 facteurs est un modèle régression linéaire qui fait l’hypothèse d’une moyenne par condition (ou croisement des modalités du facteur étudié). Il s’écrit :
$ y_{ijk}= \overline{y}_{ij} + \epsilon_{ijk}$
Les indices i,j et k ont été définis dans le paragraphe 4.1.
Le terme e\_ijk correspond aux résidus (les écarts entre les observations et les moyennes des groupes auxquels elles sont relatives).
De façon un peu plus complexe, le modèle de l’ANOVA à 2 facteurs peut également s’écrire, sous cette paramétrisation :
\[ y_{ijk}= {\overline{y}_{\cdot\cdot}} + {\alpha}_{i} + {\beta}_{j} + (\alpha\beta)_{ij}+ \epsilon_{ijk} \]
avec :
- y_barre_point_point, la moyenne globale des réponses (Grand Mean)
- α_i, l’effet différentiel du groupe i ; il s’agit de la différence entre la moyenne globale des réponses et la moyenne marginale (celle qui prend en compte l’ensemble des modalités du facteur B) des réponses de la modalité i du facteur A.
- β_j, l’effet différentiel du groupe j ; il s’agit de la différence entre la moyenne globale des réponses et la moyenne marginale (celle qui en compte l’ensemble des modalités du facteur A) des réponses de la modalité j du facteur B.
- (αβ)_ij est l’effet différentiel de l’interaction entre les modalités i du facteur A et j du facteur B:
\[(\alpha\beta)_{ij} =\overline{y}_{ij} – (\overline{y}_{\cdot\cdot}+\alpha_i\; +\beta_j ) \]
- ε_ijk correspond aux résidus (les écarts entre les observations et les moyennes des groupes auxquels elles sont relatives).
Retour sur les hypothèses des tests
Comme vu précédemment, trois tests statistiques sont réalisés :
- un pour évaluer l’effet du facteur A
- un pour évaluer l’effet du facteur B
- un pour évaluer l’effet de l’interaction.
Hypothèses pour l'évaluation de l'effet du facteur A :
Compte tenu de la paramétrisation décrite précédemment, les hypothèses nulle et alternative du test relatif au facteur A peuvent s’écrire :
\[ H_0 : \alpha_i = 0\; \text{pour tous les i=1,…, a} \]
\[ H_1 : \text{tous les}\;\alpha_i\;\text{ne sont pas égaux à 0} \]
Hypothèses pour l'évaluation de l'effet du facteur B :
[/latex]H_0 : \beta_i = 0\; \text{pour tous les i=1,…, b} [/latex
\[H_1 : \text{tous les}\;\beta_i\;\text{ne sont pas égaux à 0}\]
Hypothèses pour l'évaluation de l'interaction :
\[ H_0 : (\alpha\beta)_{ij} = 0\; \text{pour tous les i=1,…, a et j=i,…,b} \]
\[ H_1 : \text{tous les}\;(\alpha\beta)_{ij}\;\text{ne sont pas égaux à 0} \]
Les conditions de validité de l'ANOVA à 2 facteurs
Comme évoqués plus haut, les résultats du test F sont valides, si :
- les résidus sont indépendants,
- les résidus suivent une loi Normale de moyenne 0 et de variance = variance résiduelle.
- les résidus sont homogènes.
Cela se vérifie avec un diagnostique de régression et/ou l’utilisation de tests statistiques adéquats.
Si ces hypothèses ne sont pas vérifiées, il est toujours possible d’employer une ANOVA à 2 facteurs basée sur des tests de permutations, ou encore d’appliquer une transformation des réponses (log par exemple).
Conclusion
Je vous montrerai dans un prochain article comment réaliser, avec R, une ANOVA à 2 facteurs avec et sans interaction, c’est-à-dire quelles sont les commandes à utiliser, comment vérifier les hypothèses de validité, et comment faire les tests-post hoc (les comparaisons 2 à 2 pour déterminer quelles sont les moyennes significativement différentes).
En attendant, j’espère que ce second article sur l’ANOVA à 2 facteurs permettra au plus grand nombre de bien comprendre le principe de cette approche statistique.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee .

Crédits photos : JosephMonter
Poursuivez votre lecture
- Introduction à l’ANOVA à 2 facteurs
- ANOVA à 2 facteurs avec R : Tutoriel
- ANOVA à un facteur : partie 1
- ANOVA à un facteur : partie 2 – la pratique
- ANOVA à un facteur : quand les hypothèses ne sont pas satisfaites
- Tutoriel : comparaison de 2 moyennes avec le logiciel R
- Comparaison de moyennes : indiquez la significativité des différences sur le graph


Un très bon travail, chapeau!
Merci !
Merci beaucoup
Bonjour,
Merci pour vos articles très bien expliqués ! Si vous le permettez, j’aurai besoin de vos lumières au sujet d’un cas sur lequel je travaille : j’ai le jeu de données suivant : un facteur traitement à 4 modalités ; un facteur bloc à 12 modalites; et 6 répétitions pour chaque combinaison de facteur.
J’ai testé le modèle avec interaction et voici ce que j’obtiens :
Treatment SC = 0.85 df = 3 MS = 4.4 p = 0.0049
Bloc SC = 0 df = 0 MS = 0 p = NaN
Treatment*Bloc SC = 3 df = 33 MS = 1.44 p = 0.063
Je n’arrive pas à comprendre pourquoi l’effet Bloc est nul….est-ce possible ?
Merci d’avance pour vos lumières 🙂
Bonsoir,
Je me demande si le bloc est bien considéré comme une variable catégorielle. Compte tenu que le df est à 0, je pense qu’il est codé comme une variable numérique.
En espérant que cela vous aide !
Bonjour ,
J’aimerais vous demander comment savoir si l’interaction entre les deux facteurs est qualitative ou bien quantitative? J’aimerais bien le faire sour R.
Merci d’avance pour votre réponse.
Trés bonne continuation.
Bonjour,
La règle que j’emploie est que si les profils se croisent, alors c’est qualitatif, sinon quantitatif. Dans certaines situations, cela n’est pas évident de choisir….
J’espère que cela vous aide