Comme décrit dans le tutoriel il est nécessaire que l’ANOVA à 2 facteurs (comme tous les modèles linéaires d’ailleurs) satisfasse trois conditions, pour que ses résultats soient valides (c’est à dire pour qu’on puisse avoir confiance dans ces résultats). On parle alors d’hypothèses de validité. Celles-ci se vérifient sur les résidus de l’ANOVA.
Ces hypothèses de validité sont :
Pour plus de détails sur la vérification de ces hypothèses, je vous renvoie vers le tutoriel.
Si l’hypothèse d’indépendance des résidus n’est pas satisfaite, c’est généralement par ce que des observations sont réalisées plusieurs fois sur la même unité expérimentale. Par exemple, si un des facteurs est un traitement (A ou B) et le second facteur du temps (Jour1, jour2, jour 3) et que les observations sont réalisées pour chaque temps sur le même sujet. Dans ce cas, les données d’un même sujet sont corrélées, et il s’agit alors d’utiliser un modèle mixte pour prendre en compte que les données d’un même sujet se ressemblent plus que les données de deux sujets différents. Cette situation de non-indépendance des données nécessite de changer d’approche statistique.
En revanche, lorsque les résidus ne satisfont pas l’hypothèse de normalité et/ou l’hypothèse d’homogénéité cela est plus problématique, car il n’existe pas, du moins à ma connaissance, d’approche non paramétrique de l’ANOVA à 2 facteurs ( comme cela est le cas pour l’ANOVA à un facteur avec le test de Kruskal Wallis).
Il existe néanmoins une solution qui peut facilement être mise en place. Il s’agit d’appliquer une transformation sur la variable réponse. C’est ce que nous allons explorer dans cet article.
Lorsque, dans une ANOVA à 2 facteurs, l’hypothèse de normalité des résidus, et / ou l’hypothèse d’homogénéité des résidus ne sont pas satisfaites, une solution simple à envisager est celle de l’utilisation d’une transformation log, ou d’une transformation de type BoxCox (c’est une généralisation de la transformation log) de la variable réponse. L’application de ces transformations a pour conséquence d’améliorer conjointement la normalité et l’homogénéité des résidus. C’est pour cela qu’on peut avoir recours à la transformation de la variable réponse en cas de défaut de normalité des résidus et/ ou en cas de défaut d’homogénéité.
Prenons pour exemple les données mydata, simulées pour l’occasion. On pourrait imaginer qu’il s’agit de mesurer la fatigue musculaire des quadriceps en fonction de trois types d’exercices (course à pied / vélo / vélo elliptique) et en fonction de deux types d’hydratation (eau, boisson glucidique).
Vous pouvez copier-coller les lignes suivantes dans voter console R pour créer le jeu de données utilisé ici :
mydata <- structure(list(Fatigue = c(118.32, 110.02, 125.32, 110.42, 111.94,
138.65, 112.59, 118.7, 136.42, 113.7, 60.25, 68.22, 82.22, 80.53,
77.02, 72.21, 69.45, 64.92, 59.73, 69.4, 65.09, 77.01, 69.09,
68.76, 61.55, 72.08, 69.98, 60.41, 63.13, 69.95, 51.11, 47.21,
49.06, 44.45, 57.88, 54.12, 46.09, 42.28, 45.63, 41.27, 52.97,
52.58, 55.92, 57.84, 53.95, 60.37, 57.65, 50.17, 56.35, 60.01,
35.03, 35.98, 34.26, 33.12, 32.22, 34.43, 34.13, 38.16, 31.63,
35.97), Exercice = structure(c(3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L), .Label = c("Course", "Vélo elliptique", "Vélo simple"
), class = "factor"), Hydratation = structure(c(1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), .Label = c("eau", "boisson glucidique"
), class = "factor")), row.names = c(NA, -60L), class = "data.frame") Commençons par visualiser les données :
library(tidyverse)
ggplot(mydata,aes(y=Fatigue, x=Exercice, colour=Hydratation))+
geom_point(position=position_jitterdodge(dodge.width=0.7), size=2) +
geom_boxplot(alpha=0.5, position = position_dodge(width=0.8), fatten=NULL)+
theme_classic() 
On peut voir que :
Pour rappel, les contrastes sont modifiés pour obtenir des carrés de type 3 (vous trouverez plus d’infos dans ce tutoriel).
mod <- lm(Fatigue~ Exercice*Hydratation,
contrasts=list(Exercice=contr.sum, Hydratation=contr.sum),
data=mydata) plot(mod,2) 
Le QQplot nous montre qu’il existe un défaut de normalité assez prononcé puisque de nombreux points ne sont pas bien alignés selon la droite.
Le test de Shapiro Wilk va dans le même sens puisque sa p-value est < 0.05 ; il rejette donc l’hypothèse de normalité.
shapiro.test(residuals(mod))
##
## Shapiro-Wilk normality test
##
## data: residuals(mod)
## W = 0.95253, p-value = 0.02051 plot(mod,3) 
Le plot des résidus standardisés en fonction des valeurs prédites (les moyennes des croisements des exercices et des types d’hydratation) nous montre qu’il existe un défaut d’homogénéité des résidus. En effet, on peut voir que la variabilité des résidus a tendance à augmenter lorsque la fatigue augmente (fitted values).
On peut également réaliser un test de Bartlett, en créant une variable condition qui est le croisement des modalités des facteurs “Exercice” et “Hydratation” :
mydata$condition <- interaction(mydata$Exercice, mydata$Hydratation, sep="_")
tail(mydata)
## Fatigue Exercice Hydratation condition
## 55 32.22 Course boisson glucidique Course_boisson glucidique
## 56 34.43 Course boisson glucidique Course_boisson glucidique
## 57 34.13 Course boisson glucidique Course_boisson glucidique
## 58 38.16 Course boisson glucidique Course_boisson glucidique
## 59 31.63 Course boisson glucidique Course_boisson glucidique
## 60 35.97 Course boisson glucidique Course_boisson glucidique Le test de Bartlett va dans le même sens puisque sa p-value est < 0.05 ; il rejette donc l’hypothèse d’égalité des variances des résidus.
bartlett.test(residuals(mod)~mydata$condition)
##
## Bartlett test of homogeneity of variances
##
## data: residuals(mod) by mydata$condition
## Bartlett's K-squared = 26.022, df = 5, p-value = 8.837e-05 Pour cela, il suffit seulement d’ajuster à nouveau le modèle ANOVA à 2 facteurs, en utilisant `log(Fatique)` comme variable réponse :
mod_log <- lm(log(Fatigue)~ Exercice*Hydratation,
contrasts=list(Exercice=contr.sum, Hydratation=contr.sum),
data=mydata) Remarque : la transformation `log` peut être utilisée si les valeurs de la variable réponse sont strictement positives. Si certaines valeurs sont nulles, on peut ajouter + 1 au log : `log(Fatique+1)`.
Quand on réalise à nouveau le QQplot, on peut voir que la normalité des résidus s’est améliorée :
plot(mod_log,2) 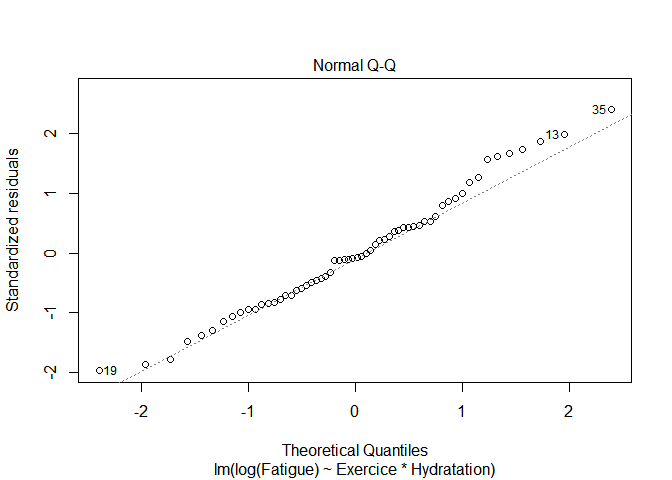
shapiro.test(residuals(mod_log))
##
## Shapiro-Wilk normality test
##
## data: residuals(mod_log)
## W = 0.98347, p-value = 0.5911
De même, le test de Shapiro Wilk ne rejette plus l’hypothèse de normalité des résidus puisque sa pvalue est > 0.05.
Le plot des résidus standardisés en fonction des valeurs prédites ne met plus en évidence d’augmentation systématique de la variabilité des résidus avec l’augmentation de la fatigue, et globalement les variabilités des résidus semblent similaires.
plot(mod_log,3) 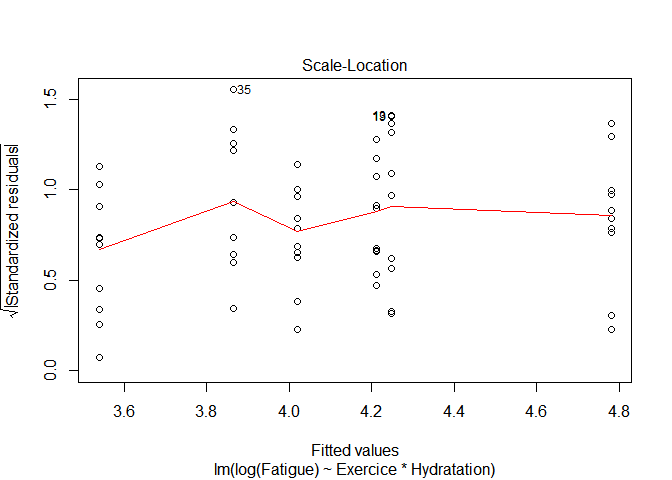
Et le test de Bartlett ne rejette plus l’hypothèse homogénéité des variances ; sa p-value est > 0.05.
bartlett.test(residuals(mod_log)~mydata$condition)
##
## Bartlett test of homogeneity of variances
##
## data: residuals(mod_log) by mydata$condition
## Bartlett's K-squared = 6.7056, df = 5, p-value = 0.2435 Remarque : le test de Levene peut également être utilisé pour évaluer la robustesse du résultat :
library(car)
leveneTest(residuals(mod_log)~mydata$condition)
## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 5 1.0705 0.387
## 54 La table ANOVA est accessible via la fonction Anova du package car.L’interaction Hydratation * Exercice apparaît significative.
Pour plus d’informations sur l’interprétation et les suites à donner à l’analyse, consulter le tutoriel sur l’ANOVA à 2 facteurs.
La transformation BoxCox est définie par :
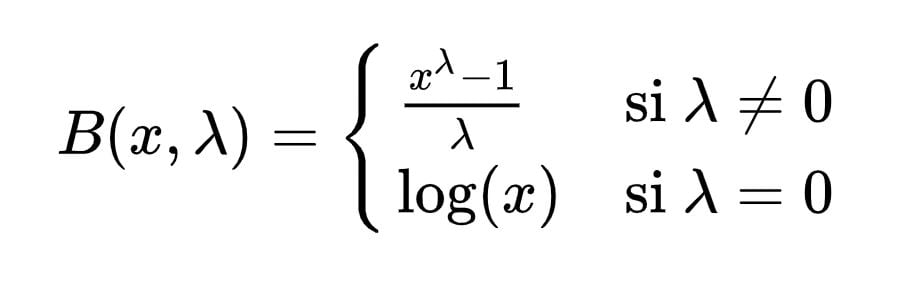
Quand lambda est différent de zéro, la transformation BoxCox est très proche d’une transformation puissance puisqu’elle retranche 1 et divise par lambda, qui est une constante.
Deux éléments importants sont à prendre en considération :
1. Cette transformation BoxCox s’applique elle aussi uniquement lorsque les données sont strictement positives, car en présence de valeurs négatives et positives, l’ordre des données, peut, ne pas être préservé. Dans ce as, on peut ajouter une valeur (appelé start) aux réponses pour les rendre toutes positives.
Il existe plusieurs fonctions dans R pour appliquer une transformation BoxCox. Ma préférence va à la fonction `powerTransform()` du package `car`, pour sa simplicité d’utilisation et les informations fournies en sortie. La fonction `powerTransform()`s’applique directement sur le modèle :
library(car)
summary(p1 <- powerTransform(mod))
Les sorties de la fonction sont constituées de trois éléments. Dans la première partie, on retrouve l’estimation du coefficient lambda (l’estimation est faite par maximum de vraisemblance).
Dans la seconde partie, un test statistique est réalisé pour évaluer si lambda peut être fixé à 0, c’est à dire pour évaluer si une simple transformation log est suffisante.
Dans la troisième partie un test statistique est réalisé pour évaluer si la transformation BoxCox (avec lambda =1 ou lambda différent de 1) est réellement nécessaire.
Ici, on peut voir que :
A présent, il est nécessaire d’ajouter la réponse transformée au jeu de données, pour ensuite ajuster à nouveau le modèle ANOVA à 2 facteurs avec cette nouvelle réponse :
mydata_bc <- transform(mydata, Fatigue_bc=bcPower(Fatigue,coef(p1)))
head(mydata_bc)
## Fatigue Exercice Hydratation condition Fatigue_bc
## 1 118.32 Vélo simple eau Vélo simple_eau 2.747563
## 2 110.02 Vélo simple eau Vélo simple_eau 2.726083
## 3 125.32 Vélo simple eau Vélo simple_eau 2.764256
## 4 110.42 Vélo simple eau Vélo simple_eau 2.727164
## 5 111.94 Vélo simple eau Vélo simple_eau 2.731229
## 6 138.65 Vélo simple eau Vélo simple_eau 2.793021
mod_bc <- lm(Fatigue_bc~ Exercice*Hydratation,
contrasts=list(Exercice=contr.sum, Hydratation=contr.sum),
data=mydata_bc) Lorsqu’on réalise le QQplot, on peut alors voir que la normalité des résidus a été améliorée :
plot(mod_bc,2) 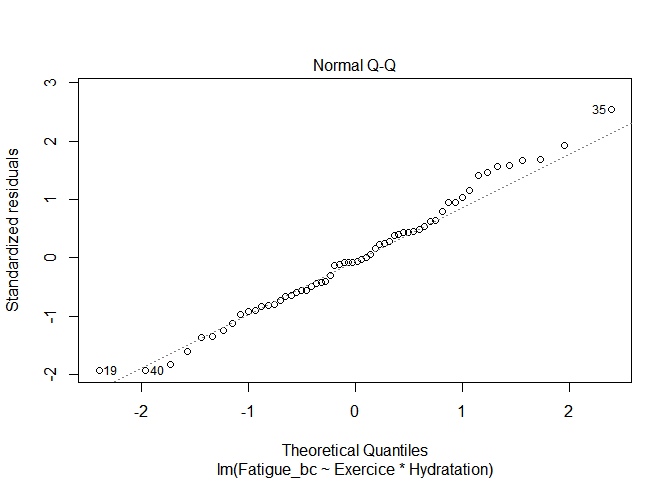
Ceci est confirmé par le test de Shapiro-Wilk :
shapiro.test(residuals(mod_bc))
##
## Shapiro-Wilk normality test
##
## data: residuals(mod_bc)
## W = 0.98638, p-value = 0.7416 plot(mod_bc,3) 
La variabilité des résidus semble plutôt homogène.
Ceci est confirmé par le test de Bartlett:
mydata_bc$condition <- interaction(mydata_bc$Exercice, mydata_bc$Hydratation, sep="_")
bartlett.test(residuals(mod_bc)~mydata_bc$condition)
##
## Bartlett test of homogeneity of variances
##
## data: residuals(mod_bc) by mydata_bc$condition
## Bartlett's K-squared = 6.1115, df = 5, p-value = 0.2955 Anova(mod_bc,type=3)
## Anova Table (Type III tests)
##
## Response: Fatigue_bc
## Sum Sq Df F value Pr(>F)
## (Intercept) 383.89 1 448427.887 < 2.2e-16 ***
## Exercice 0.65 2 380.712 < 2.2e-16 ***
## Hydratation 0.37 1 433.678 < 2.2e-16 ***
## Exercice:Hydratation 0.01 2 5.336 0.007679 **
## Residuals 0.05 54
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Ici encore l’interaction Hydratation * Exercice apparaît significative. Cela était déjà cas avant l’application des transformations , mais avec une statistique F sans doute largement surestimée ( de l’ordre de 6 et 5 avec les transformations contre 34 sans !) :
Anova(mod,type=3)
## Anova Table (Type III tests)
##
## Response: Fatigue
## Sum Sq Df F value Pr(>F)
## (Intercept) 261217 1 6529.414 < 2.2e-16 ***
## Exercice 26869 2 335.814 < 2.2e-16 ***
## Hydratation 13589 1 339.671 < 2.2e-16 ***
## Exercice:Hydratation 2746 2 34.317 2.411e-10 ***
## Residuals 2160 54
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 J’espère que cet article répondra aux attentes des nombreux messages de que j’ai reçu depuis la publication du tutoriel sur l’ANOVA à 2 facteurs. Il est à noter que ces transformations log et BoxCox ne sont pas réservées à l’ANOVA à deux facteurs, elles peuvent également être utilisées , par exemple, dans le cadre de la régression linéaire multiple, qui n’a pas non plus d’équivalent non paramétrique. Il faut aussi garder en tête que ces transformations ne sont pas toujours efficaces, parfois les améliorations de la normalité et / ou de l’homogénéité des résidus restent insuffisante.
D’autres approches peuvent être employées si seule l’hypothèse d’homogénéité des résidus est rejetée, comme l’utilisation des estimateurs sandwich ou encore en modélisant la variance. J’essaierai de présenter ces deux approches dans un prochain article.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédits photo : Composita

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
11 réponses
Merci beaucoup pour votre article, il tombe à point ! Et merci encore pour ce blog très utile à tous les niveaux !
Très impressionnant
Merci beaucoup
Merci Claire pour cet article qui vient booster nos connaissance. Well done
Merci Claire pour cet article qui vient nous éclaircir de plus.
Bonjour, que faire lorsque ces approches sont insuffisantes ?
Bonjour Mathilde,
j’imagine que malgré les solutions l’hypothèse de normalité des résidus et/ou celles d’homogénéité ne sont pas satisfaites.
Si c’est la normalité, et que la forme des résidus ne ressemble pas à une banane, on peut croiser les doigts en disant que le modèle linéaire est robuste par rapport à la non normalité. Si c’est l’hypothèse d’homogénéité, on peut modéliser la variance, ou utiliser un estimateur sandwich. Vous trouverez des infos sur la modélisation de la variance dans le livre de zuur : https://www.amazon.fr/Mixed-Effects-Models-Extensions-Ecology/dp/0387874577/ref=sr_1_1?__mk_fr_FR=ÅMÅŽÕÑ&dchild=1&keywords=alain zuur mixed models&qid=1592772346&sr=8-1
Et pour les estimateurs sandwich, il me semble qu’il ya un exemple dans cet ouvrage : https://www.amazon.fr/R-Companion-Applied-Regression/dp/141297514X/ref=sr_1_4?__mk_fr_FR=ÅMÅŽÕÑ&dchild=1&keywords=companion for regression analysis&qid=1592772402&sr=8-4
Bonne continuation.
Bonjour Claire,
Merci pour cet article qui me permet de mieux comprendre la(les) démarche(s).
J’ai réalisé la transformation log puis la transformation BoxCox à la réponse. L’intéraction est toujours significative avec une statistique F de l’ordre de 8. Cependant avant la transformation elle était de 6. Que cela signifie-t-il ?
Ayant une intéraction significative, j’ai suivi votre démarche (2.3.4) en réalisant une anova à 1 facteur avec comparaison 2 à 2. Cependant dois-je utilisé les données transformées (« Fatigue_bc », mydata_bc$condition dans votre exemple) ou les données initiales (« Fatigue », mydata$condition dans votre exemple) ?
Bonjour Clélia,
l’augmentation de F vient sans doute de la diminution de l’erreur standard, a priori cela n’a pas trop d’importante. Pour les comparaisons multiples, il faut utiliser les variables avec la transformation boxcox.
Bonne continuation.
Merci infiniment pour cette série d’articles sur l’anova. C’était incomparablement plus clair et complet que tout ce que j’ai pu voir avant, et ça m’a permis d’enfin comprendre cette méthode et de pouvoir l’appliquer sur mes données.
Bonjour Samuel,
merci pour votre commentaire. Je suis ravie que les articles vous aient permis de comprendre la méthode et de l’appliquer. C’est très chouette !
Bonne continuation
Merci beaucoup pour toutes ces notions, cela m’a beaucoup aidé 🙏🏼 Les explications sont tellement claires.