
Jusque très récemment, je ne savais pas qu’il existait une approche permettant de réaliser une ANOVA non paramétrique à deux facteurs. C’est un lecteur du blog (Philippe V.) qui me l’a fait découvrir. Cette alternative, c’est le test de Scheirer-Ray-Hare ; je n’en avais jamais entendu parler.
J’ai fait quelques recherches pour en savoir plus, et je n’ai pas trouvé grand-chose. Je suis quand même tombée sur une page wikipédia. Elle est plutôt succincte, mais il y a quelques informations intéressantes :
le test est basé sur les rangs (classique pour une approche non paramétrique) ; par contre la statistique du test n’est pas décrite
la puissance de ce test (capacité à mettre en évidence un effet significatif lorsque cet effet existe réellement) serait bien inférieure à celle l’ANOVA paramétrique à deux facteurs. Cela serait la raison, pour laquelle le test Scheirer-Ray-Hare n’est pas populaire (en plus du fait qu’il a été décrit après les approches paramétriques et non paramétriques de l’analyse de variance (à un facteur j’imagine – c’est-à-dire le test de Kruskal Wallis).
Philippe m’avait également fait suivre cette page du site rcompanion dédiée à l’utilisation du test de Scheirer-Ray-Hare avec R, ce qui m’a permis de le mettre en oeuvre facilement.
Dans cet article, je vous propose donc d’explorer un peu ce test, en comparant les résultats obtenus avec ceux de l’ANOVA paramétrique à deux facteurs et ceux obtenus en employant une approche par permutation, le tout sur deux jeux de données que je connais bien :
warpbreaks : contenu dans le package dataset, et qui concerne les ruptures de fils sur un métier à tisser en fonction de deux types de laine et de trois niveaux de tension.
ToothGrowth : contenu dans le package dataset, et qui concerne la longueur des cellules de croissance des dents chez des cobayes qui reçoivent de la vitamine C selon trois doses et deux méthodes d’administration (jus d’orange ou comprimé) différentes.
Comme je connais ces deux jeux de données, je sais que :
Les interactions entre les deux facteurs étudiés sont significatives (lorsqu’on emploie l’anova paramétrique). L’évaluation de l’interaction est importante, car les analyses subséquentes peuvent être différentes si l’effet est statistiquement significatif, ou non.
Et que les conditions d’applications de l’anova paramétrique sont satisfaites pour ToothGrowth, mais pas pour warpbreaks (l’hypothèse d’homogénéité est rejetée) ; le test de Scheirer-Ray-Hare aura donc tout son sens.
# renommer
TG <- ToothGrowth
TG$dose <- as.factor(TG$dose)
library(tidyverse)
TG %>%
group_by(supp, dose) %>%
count()
## # A tibble: 6 x 3
## # Groups: supp, dose [6]
## supp dose n
## <fct> <fct> <int>
## 1 OJ 0.5 10
## 2 OJ 1 10
## 3 OJ 2 10
## 4 VC 0.5 10
## 5 VC 1 10
## 6 VC 2 10 Le jeu de données est équilibré avec 10 données par conditions (1 dose, 1 mode d’administration). Nous pouvons facilement visualiser les données comme ceci :
library(RcmdrMisc)
plotMeans(TG$len,TG$dose,TG$supp) 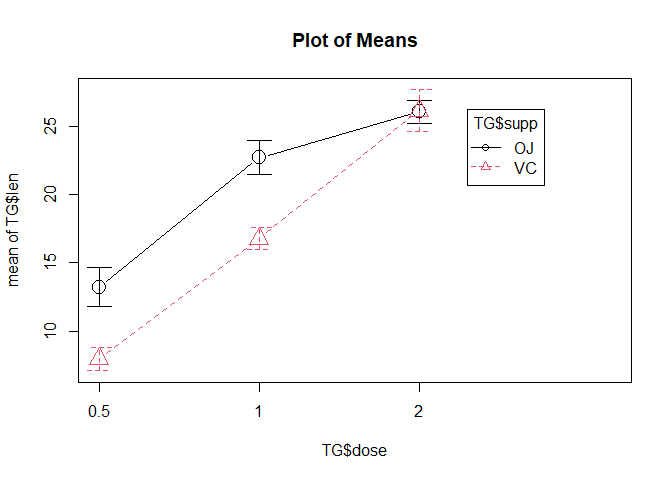
Le graphique nous montre que l’évolution de la réponse en fonction de la dose n’est pas identique pour les deux modes d’administration, ce qui laisse supposer une interaction. L’évolution se faisant dans la même direction, on parlera plutôt d’interaction quantitative.
Vous trouverez plus d’informations sur les anova paramétriques à deux facteurs dans les articles :
TG.aov <- aov(len~dose*supp,
contrasts = list(dose=contr.sum,
supp=contr.sum),
data=TG)
Anova(TG.aov, type=3)
## Anova Table (Type III tests)
##
## Response: len
## Sum Sq Df F value Pr(>F)
## (Intercept) 21236.5 1 1610.393 < 2.2e-16 ***
## dose 2426.4 2 92.000 < 2.2e-16 ***
## supp 205.4 1 15.572 0.0002312 ***
## dose:supp 108.3 2 4.107 0.0218603 *
## Residuals 712.1 54
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Les tests de tous les effets sont significatifs, notamment celui de l’interaction (pval =0.022).
Nous pouvons évaluer les conditions d’application de l’ANOVA paramétrique (normalité et homogénéité des résidus) de manière visuelle et en employant les tests de Shapiro-Wilk (Normalité des résidus) et Bartlett (homogénéité des résidus) :
library(performance)
check_model(TG.aov) 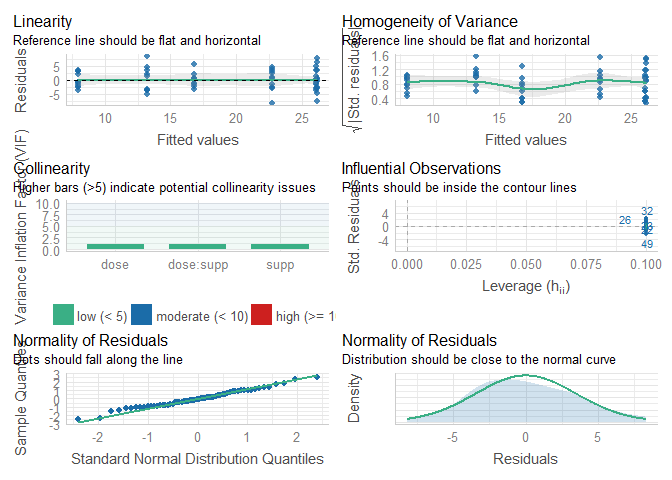
# test de shapiro wilk sur les résidus
check_normality(TG.aov)
## OK: residuals appear as normally distributed (p = 0.669).
# test de Bartlet :
check_homogeneity(TG.aov)
## OK: There is not clear evidence for different variances across groups (Bartlett Test, p = 0.226). Les deux hypothèses sont satisfaites.
Le test de Scheirer-Ray-Hare peut être mis en place avec la fonctioncheirerRayeHare() du package rcompanion.
### Scheirer–Ray–Hare test
library(rcompanion)
scheirerRayHare(len ~ dose * supp,
data = TG, type=2)
##
## DV: len
## Observations: 60
## D: 0.999222
## MS total: 305
## Df Sum Sq H p.value
## dose 2 12394.4 40.669 0.00000
## supp 1 1050.0 3.445 0.06343
## dose:supp 2 515.5 1.692 0.42923
## Residuals 54 4021.1 Contrairement à l’anova paramétrique à deux facteurs, ici, seul l’effet de la dose est significatif au seuil de 5%. Et on peut voir que la pvalue de l’interaction est très élevée (pvalue = 0.43).
library(lmPerm)
set.seed(1234)
TG.aovp <- aovp(len~dose*supp,
contrasts = list(dose=contr.sum,
supp=contr.sum),
data=TG)
## [1] "Settings: unique SS "
summary(TG.aovp)
## Component 1 :
## Df R Sum Sq R Mean Sq Iter Pr(Prob)
## dose1 2 2426.43 1213.22 5000 < 2e-16 ***
## supp1 1 205.35 205.35 5000 < 2e-16 ***
## dose1:supp1 2 108.32 54.16 3123 0.04195 *
## Residuals 54 712.11 13.19
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Ici, comme avec l’ANOVA paramétrique à deux facteurs, tous les effets sont significatifs au seuil de 5%, et notamment celui de l’interaction (pvalue =0.042).
View(warpbreaks)
WB <- warpbreaks
library(tidyverse)
WB %>%
group_by(wool, tension) %>%
count()
## # A tibble: 6 x 3
## # Groups: wool, tension [6]
## wool tension n
## <fct> <fct> <int>
## 1 A L 9
## 2 A M 9
## 3 A H 9
## 4 B L 9
## 5 B M 9
## 6 B H 9 Le jeu de données est équilibré avec 9 données par conditions (1 type de laine, 1 tension). Nous pouvons facilement visualier les doonnées comme ceci :
library(RcmdrMisc)
plotMeans(WB$breaks,WB$tension,WB$wool) 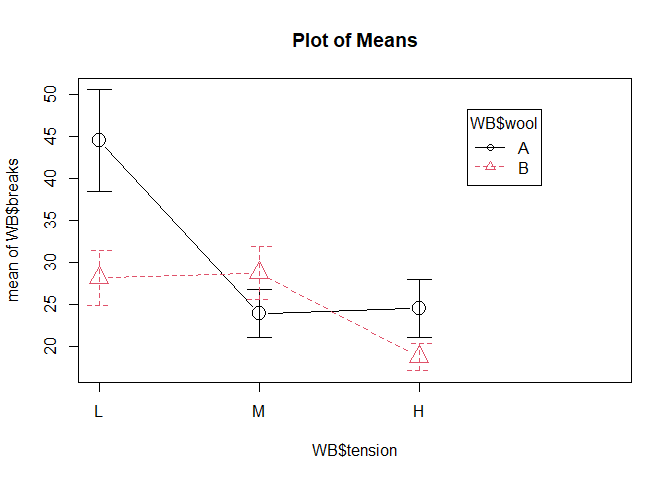
On peut voir que l’évolution du nombre de ruptures des fils, en fonction du niveau de tension, n’est pas identique pour les deux types de laines, puisque les profils se croisent. On peut donc suspecter la présence d’une interaction de type qualitative entre le type de laine et la tension.
WB.aov <- aov(breaks~wool*tension,
contrasts = list(wool=contr.sum,
tension=contr.sum),
data=WB)
Anova(WB.aov, type=3)
## Anova Table (Type III tests)
##
## Response: breaks
## Sum Sq Df F value Pr(>F)
## (Intercept) 42785 1 357.4672 < 2.2e-16 ***
## wool 451 1 3.7653 0.0582130 .
## tension 2034 2 8.4980 0.0006926 ***
## wool:tension 1003 2 4.1891 0.0210442 *
## Residuals 5745 48
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Ici, l’effet de l’interaction et de la tension sont significatifs au seuil de 5% et celui de la laine au seuil de 10% (pvalue = 0.058). Nous pouvons vérifier les hypothèses de normalité et d’homogénéité des résidus.
library(performance)
check_model(WB.aov) 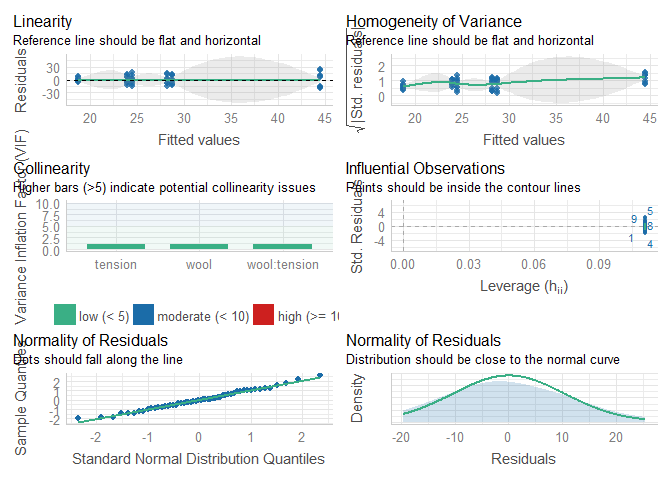
check_normality(WB.aov)
## OK: residuals appear as normally distributed (p = 0.816).
check_homogeneity(WB.aov)
## Warning: Variances differ between groups (Bartlett Test, p = 0.024). L’hypothèse de normalité est acceptée, mais pas l’hypothèse d’homogénéité. Cela n’est pas étonnant, car la variable réponse est de type comptage. Ces données suivent théoriquement une distribution de Poisson qui spécifie que la variance est proportionnelle à la moyenne. Ainsi, plus le nombre de ruptures est important, plus la variabilité est importante. C’est ce qu’on voit sur le graph “Homogeneity of Variance »).
### Scheirer–Ray–Hare test
library(rcompanion)
scheirerRayHare(breaks~wool*tension,
data = WB, type=2)
##
## DV: breaks
## Observations: 54
## D: 0.9980941
## MS total: 247.5
## Df Sum Sq H p.value
## wool 1 327.6 1.3261 0.249508
## tension 2 2670.2 10.8093 0.004496
## wool:tension 2 899.8 3.6427 0.161810
## Residuals 48 9194.9 Avec le test de Scheirer-Ray-Hare, seul l’effet de la tension est significatif au seuil de 5% ; l’effet l’interaction n’est pas mis en évidence, même au seuil de 10% (pvalue=0.16).
library(lmPerm)
set.seed(1234)
WB.aovp <- aovp(breaks~wool*tension,
contrasts = list(wool=contr.sum,
tension=contr.sum),
data=WB)
## [1] "Settings: unique SS "
summary(WB.aovp)
## Component 1 :
## Df R Sum Sq R Mean Sq Iter Pr(Prob)
## wool1 1 450.7 450.67 2452 0.03956 *
## tension1 2 2034.3 1017.13 5000 0.00020 ***
## wool1:tension1 2 1002.8 501.39 5000 0.01660 *
## Residuals 48 5745.1 119.69
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Les résultats sont très proches de ceux obtenus avec l’ANOVA paramétrique à deux facteurs : les effets de l’interaction et de la tension sont significatifs au seuil de 5%. Il en est de même pour la laine dont la pvalue est de 4%.
Remarque
Certains auteurs rapportent que les approches par permutations nécessitent l’homogénéité des résidus (je pense que c’est vrai, car sans cela, les étiquettes ne sont pas interchangeables puisque la probabilité que certaines valeurs appartiennent à certains groupes n’est pas équiprobable). Cette hypothèse n’est pas satisfaite ici ; les résultats manquent alors sans doute de robustesse. Néanmoins, à titre exploratoire, nous pouvons quand même constater que les résultats obtenus sont, là encore, très similaires à ceux de l’approche paramétrique, et en ce qui concerne l’interaction, contraires à ceux du test de Scheirer-Ray-Hare.
Les résultats obtenus avec les deux jeux de données semblent bien confirmer le manque de puissance du test de Scheirer-Ray-Hare, notamment pour détecter l’interaction entre les deux facteurs.
Cette lacune est majeure, car l’évaluation de la significativité de l’interaction est l’élément clé de l’ANOVA à deux facteurs ; la suite de l’analyse en dépend.
Au final, je ne pense pas me resservir beaucoup de ce test. En cas de défaut important de la normalité, il me semble préférable d’employer une approche par permutation. Et en cas de défaut d’homogénéité des variances, je pense que j’essaierai plutôt d’employer une transformation (log ou boxcox). Mais si celle-ci ne fonctionne pas, le test de Scheirer-Ray-Hare, pourrait quand même être utile (mais je pense que je vérifierais la robustesse des résultats en employant également une anova paramétrique et une approche par permutation ! )
Dites-moi en commentaire ce que vous pensez de ce test de Scheirer-Ray-Hare.
Vous souhaitez soutenir mon travail ? Vous pouvez le faire en réalisant un don libre sur la page Tipeee du blog.


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
14 réponses
Génial, je vais explorer ça !
Cela signifie que l’on peut explorer les effets d’interactions, ce qui est compliqué avec les analyses non-paramétriques.
En revanche, pourriez-vous indiquer comment on rédige les résultats du test dans un compte-rendu ou article scientifique.
Il faut indiquer la valeur du H et la p-value j’imagine ?
Bonjour Laurence,
oui on peut explorer les interactions, mais en gardant à l’esprit que le test manque de puissance. C’est pour ça que je testerai la robustesse des résultats avec l’anova paramétrique et le test de permutation.
Concernant la rédaction des résultats, je pense que l’on peut s’inspirer de ce que fait le package report. Vous trouverez un exemple dans cet article « Obtenir un reporting automatique des analyses statistiques«
Bonjour Claire et merci pour ces explications. Finalement dans cet exemple, vous préférez opter pour une ANOVA paramétrique malgré une absence d’homogénéité des variances. Dans ce cas là, n’est-il pas tout simplement préférable de partir sur un test de Kruskal-Wallis ?
Bien cordialement
Bonjour,
Le test de Kruskall-Wallis est une anova non paramétrique à un seul facteur. Ici on est sur une anova non paramétrique à 2 facteurs. Et comme le test manque de puissance, je pense que c’est pas mal de vérifier la robustesse des résultats avec une méthode paramétrique, même si les hypothèses ne sont pas satisfaites.
Bonne continuation
Merci Claire pour ce partage et les visualisations avec le package performance.
Rcompanion est une telle mine qu’il y a toujours à découvrir… tout comme DellaData.fr !
Merci beaucoup pour cette page comme toujours extrêmement didactique et source d’inspirations.
Vous avez pour clarifier l’aspect « nouveauté » dans la troisième édition du Sokal & Rohl (1991) en page 445-447 un exemple traité de ce test
avec les calculs à la main (box 13.12) pour bien en comprendre construction et logique.
L’ouvrage de Jerrold Zar (1984) présente également ce test en chapitre 13.4, p. 219 avec une approche de comparaisons multiples remaniée dans les éditions ultérieures.
En tout cas dans le domaine de la biologie expérimentale, voilà un test bien intéressant.
Merci beaucoup, Claire. C’est chouette ce test. R peut tout faire finalement. On ne cessera d’apprendre.
Claire, je vous tire mon chapeau. Vous aviez une méthodo simple pour faire passer la pilule.
J’ai beaucoup aimé ce tuto.
Bon vent!!
Vraiment merci beaucoup je me demandais depuis fort longtemps si cela était possible
Je pense avoir oublié de citer mes sources :
Sokal, R.R. & Rohlf, F.J., 1995. Biometry. The principles and practice of statistics in biological research. Third edition. New York, Freeman, W.H. and Co. : 887 p.
qui fait duite à l’édition de 198 en deux volumes (livre + tables)
et
Zar, J.H., 1984. Biostatistical analysis. Englewood Cliffs, New Jersey, Prentice Hall : 718 p.
avec sa nouvelle édition
Zar, J.H., 2014. Biostatistical analysis. Harlow, UK, Pearson Education Limited : 756 p.
Cordialement
Bonjour Pierre Guy,
merci pour ces compléments d’information.
J’ajoute aussi la publication originale :
Scheirer, C. J., Ray, W. S., & Hare, N. (1976). The analysis of ranked data derived from completely randomized factorial designs. Biometrics, 429-434.
Bonjour Claire,
Je rebondis sur votre article, il est vrai avec beaucoup de retard…
Ce que j’aime bien dans votre blog, c’est l’approche claire (sans jeu de mots) de la présentation d’un problème qui est pourtant loin d’être simple. Bravo à vous pour ces présentations synthétiques et abordables.
Votre comparaison entre les différentes analyses est vraiment intéressante mais une question me taraude cependant :
dans l’analyse par permutations, si on relance la commande, les résultats finaux changent. Il est vrai qu’ils ne changent pas toujours d’une manière fondamentale mais je me suis retrouvé dans des cas où justement, des résultats significatifs ne l’étaient plus après une 2e voire 3e tentative… Cela s’explique bien entendu par le réarrangement des données du fait de la permutation…
Mais du coup, quelle est la méthode à utiliser ? Doit-on se contenter des premiers calculs seulement ?
Merci d’avance de votre point de vue
Cordialement
Philippe
Bonjour Philippe,
je suis bien embêtée aussi lorsque je constate ce comportement.
Je pense qu’il faudrait faire une boucle pour lancer 100, 1000 ou 10 000 simulations et regarder combien de fois les résultats s’inversent….mais je n’ai rien de plus précis à vous recommander.
Bonjour ! Je suis très comptent de lire votre article sur l’Anova à deux facteurs, de sur quoi j’ai eu ce dilemme lors de la rédaction de mon mémoire et j’ai alors trouvé par hasard le test de Scheirer-Ray-Hare en fessant mes recherches.