Faites de belles tables descriptives avec summarytools !
Lorsqu’on analyse des données, c’est très important de pouvoir réaliser des tables descriptives. J’ai d’ailleurs déjà écrit plusieurs articles au sujet des analyses descriptives :
- Analyses statistiques descriptives de données numériques – partie 1
- Analyses statistiques descriptives de données numériques – partie 2 ,
- Utilisez le package skimr en complément du package pastecs pour réaliser vos analyses statistiques descriptives
- 4 super fonctions pour la description de vos données.
J’étais déjà très satisfaite des différents packages et fonctions décrites dans ces articles, je les utilise dans mes routines d’analyse. Et puis la semaine dernière, je suis tombé sur ce tweet :
#Rstats tip of the week: Ever want to summarize all variables in a data frame instantly? Use summarytools! This is a game changer for me. Works on categorical and numeric.
— The Data Sci Guy (@DataSci_Guy) April 8, 2019
library(summarytools) view(dfSummary(iris))@RLangTip @WeAreRLadies pic.twitter.com/d46Un0bcNF
Cela avait l’air assez bluffant alors j’ai essayé de faire des tables descriptives avec summarytools. Et effectivement, c’est bluffant ! Comme d’autres packages le package `summarytools` et sa fonction `dfSummary()` permettent de faire une analyse descriptive des variables numériques et catégorielles MAIS SURTOUT, ils permettent, à partir d’un document R markdown, de présenter ces résultats, automatiquement, dans une table de résultat avec un rendu plutôt très chouette !
Je vous montre comment ça marche !
Installation et chargement du package
Vous pouvez installer le package depuis CRAN par l’outil d’installation de package de RStudio (fenêtre an bas à droite –> Packages –> Install –> summarytools), ou bien en utilisant la commande suivante :
install.packages("summarytools",dependencies = TRUE)
library(summarytools) Réglages des options du package
Dans la vignette d’introduction au package summary tools, il est conseillé de régler les options du package comme ceci :
st_options(plain.ascii = FALSE, # This is a must in Rmd documents
style = "rmarkdown", # idem
dfSummary.varnumbers = FALSE, # This keeps results narrow enough
dfSummary.valid.col = FALSE) Vous pouvez aussi ajouter `lang= »fr »` pour avoir la table des résultats en français plutôt qu’en anglais :
st_options(plain.ascii = FALSE, # This is a must in Rmd documents
style = "rmarkdown", # idem
dfSummary.varnumbers = FALSE, # This keeps results narrow enough
dfSummary.valid.col = FALSE,
lang ="fr") # idem Passer l'argument results="asis" dans le chunk set up
Le chunk setup est le premier chunk du document Rmarkdown :

Réalisation s'une table descriptive
La table descriptive est générée à l’aide de la fonction `dfSummary()`. Par exemple ici, avec l’exemple ultra classique du jeu de données « iris »:
dfSummary(iris) Le rendu obtenu est le suivant :
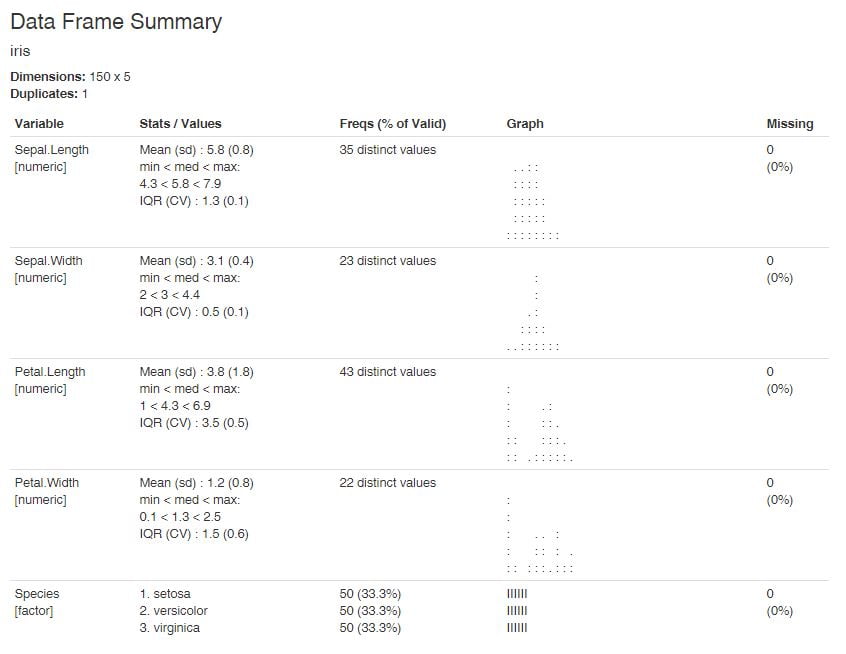
Pour obtenir un rendu optimal, notamment au niveau de la colonne graph, il est conseillé (toujours dans la vignette d’introduction au package) d’utiliser les arguments suivants :
dfSummary(iris, plain.ascii = FALSE, style = "grid",
graph.magnif = 0.75, valid.col = FALSE, tmp.img.dir = "/tmp") 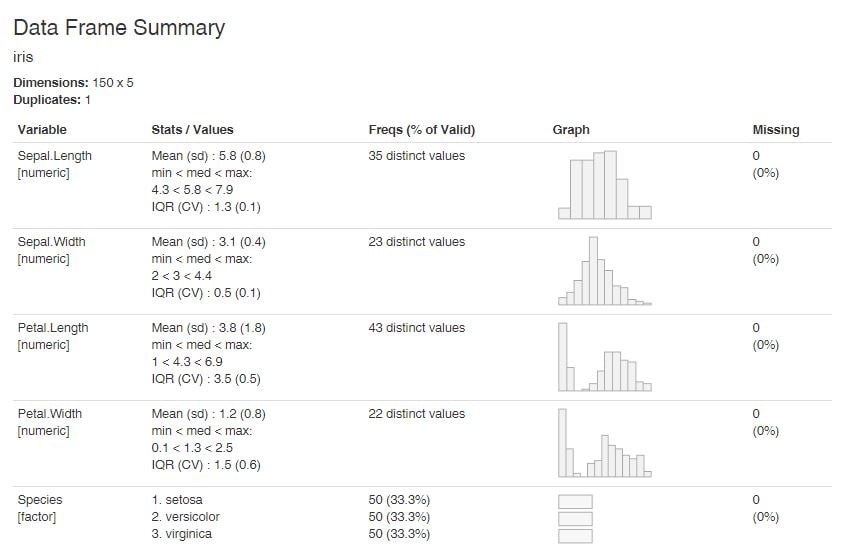
Génial, non ?
Ce rendu est obtenu dans les formats html et word. En revanche en pdf, la dernière commande induit un message d’erreur. De ce fait seul la commande `dfSummary(iris)` et premier rendu semble possible (c’est déjà pas mal !) Et si vous souhaitez supprimer la colonne graph, utilisez l’argument `graph.col=FALSE`, comme ceci :
dfSummary(iris, graph.col=FALSE) Réalisation d'une table de contingence
En parcourant la vignette, il y a une fonctionnalité que j’ai trouvé très utile, c’est le fait de créer une table de contingence avec un rendu parfaitement adapté. Jusque-là, je n’avais pas de solution aussi satisfaisante pour présenter les résultats proprement :
with(tobacco,
print(ctable(smoker,diseased, prop = "r"), method = "render")) 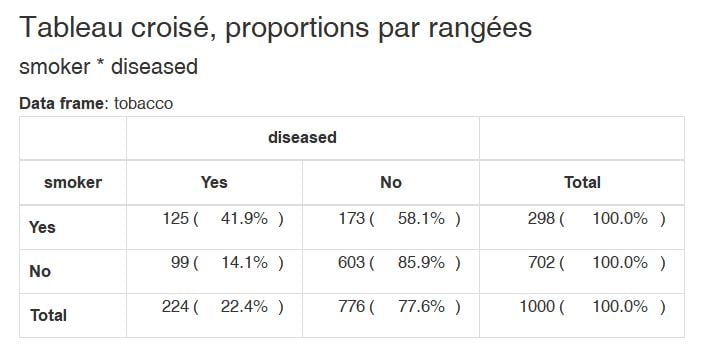
L’argument `prop = « r »` permet de calculer les pourcentages par ligne. Les autres options sont :
- `prop = « c »` pour un calcul par colonne,
- `prop = « t »` pour un calcul total,
- `prop = « n »` (none) pour ne pas avoir de calcul des pourcentages.
En plus, cerise sur le gâteau, on peut ajouter les résultats du test du Chi2, réalise sur cette table de contingence :
with(tobacco,
print(ctable(smoker,diseased, prop = "r", chisq=TRUE), method = "render")) 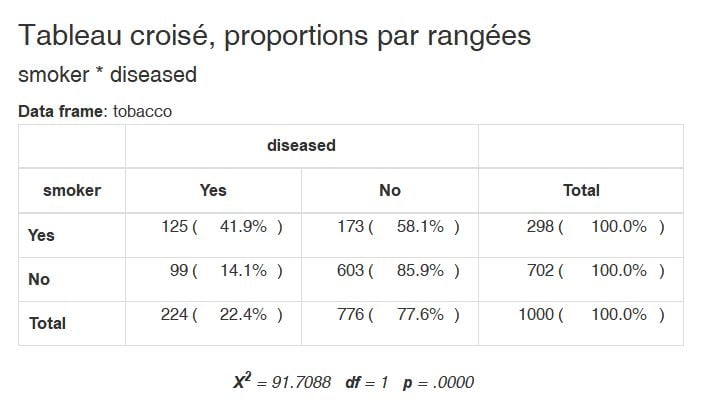
Pour aller plus loin
Le package est vraiment intéressant, il existe pas mal d’options, c’est pourquoi je vous conseille de jeter un coup d’œil sur les vignettes !
Conclusion
Je trouve ce package vraiment génial ! Et vous ? Est ce que l’article vous a convaincu de l’essayer ?
Est ce que vous avez déjà prévu de l’utiliser dans vos routines ? Dites le moi en commentaire !
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏
Image par Andrew Martin de Pixabay
Continuez votre lecture :
- Analyses exploratoires avec le package DataExplorer
- Comment réaliser une description efficace de vos données
- Faire une table one ultra facilement
- Créer une table 1 avec R
- Utilisez le package skimr en complément du package pastecs pour réaliser vos analyses statistiques descriptives
- Analyses statistiques descriptives de données numériques – partie 2
- Analyses statistiques descriptives de données numériques – partie 1

Merci Claire ! En effet ça donner envie d’essayer 🙂
Merci Claire pour ce partage, c’est vrai que la présentation est très sympa, mais je rencontre un problème d’installation en utilisant votre script :
> library(summarytools)
Error: package or namespace load failed for ‘summarytools’ in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]]):
aucun package nommé ‘magick’ n'est trouvé
In addition: Warning message:
le package ‘summarytools’ a été compilé avec la version R 3.4.4
Bonjour,
vous pouvez essayer d’installer la package via github
install.packages(« devtools »)
library(devtools)
install_github(« rapporter/pander ») # Necessary for optimal results!
install_github(« dcomtois/summarytools »)
Vous trouverez les infos d’installation ici : https://github.com/dcomtois/summarytool.
Bonne continuation
Merci beaucoup
Bonne continuation
Merci Claire pour cette merveilleuse découverte.
Merci Claire
Cet outil donne à la fois plusieurs informations riches.
Merci pour le partage et Bonne continuation
Merci infiniment Claire, chaque article vous renforcez ma motivation d’aller plus loin encore, vraiment merci !!!
Merci Claire,
Tu as raison, c’est génial.
Merci beaucoup.
Bonjour Claire,
Merci de voter blog.
Avez-vous essayé le package table1?
Bonjour Simon,
non je ne connais pas ce package, mais je vais l’essayer.
Merci pour le partage
Bonjour
Merci beaucoup de ce tutoriel.
Malheureusement, je ne parviens pas a obtenir les graphes.
J’ai ce message répété pour toutes mes variables « <img style= »border:none;background-color:transparent;p… »
Avez vous une idée ?
J’ai bien ajouté les reglages comme vous l’avez indiqué, mis a jour mes versions de R et R studio, je suis debutante avec R et sèche complètement
Merci si vous avez une idée
Bonjour Caroline,
je vous propose deux pistes :
1) Farfouiller dans l’onglet Issue de la paae github du package : https://github.com/dcomtois/summarytools/issues
2) Essayer de repasser dans la version antérieure de R (celle avant la 4.0.0).
Bonne continuation.
Bonjour Claire,
Je me permets de vous contactez, car depuis quelques jours maintenant j’essaye de résoudre un problème et je n’y arrive pas seul..
J’ai découvert le package summarytools, et la la fonction dfSummary que je trouve dingue pour réaliser des tables descriptives de qualité sur Rstudio.
Tout fonctionnait très bien jusqu’au jour ou en relançant via Rmarkdown la fonction dfsummary sur une base de donné que j’avais modifié, le programme m’a ressorti sur word une analyse descriptive ou tous les graphes étaient identiques. Je pensais au départ que cela résultait d’une erreur provenant de la modification de ma base de donné, mais en reprenant l’ancienne, ou j’avais pourtant une belle table descriptive, cette fois ci de nouveau mon analyse descriptives donnait des graphes identiques… J’ai beaucoup cherché, mais je n’ai trouvé aucune solution face à ce problème. Tout bêtement, j’ai alors réutilisé la fonction dfSummary sur un autre ordinateur, et la miracle tout fonctionnait comme avant. MAIS, depuis tout à l’heure ce nouvel ordinateur m’a fait exactement la meme chose, c’est à dire qu’a présent, lorsque je lance sous markdown, il me renvoie une table descriptive avec des graphiques associés qui sont tous identiques … Je ne sais pas si je suis très claire, mais pensiez vous que vous pourriez m’aider à trouver une solution ?
Bonjour,
je n’ai pas de solution à vous proposer. En revanche, je vous conseille de faire remonter le problème dans l’onglet issues de la page github du package : https://github.com/dcomtois/summarytools/issues
Bonne continuation.