La modélisation dose réponse consiste à modéliser, à l’aide d’une équation mathématique, l’évolution d’une réponse (la taille de racines de plantes par exemple) en fonction de l’augmentation de la dose d’un élément étudié (un herbicide par exemple).
Pour réaliser une modélisation dose réponse, il est nécessaire de disposer des résultats d’une expérimentation dose réponse, dans laquelle :
Il s’agit ensuite, de mettre en relation les réponses avec les doses, à l’aide d’un modèle mathématique.
Cette mise en relation c’est déjà ce que l’on fait lorsqu’on réalise une régression linéaire simple. La différence ici, c’est que les relations dose réponse que l’on observe sur des systèmes biologiques ne sont généralement pas linéaire, mais curvi-linéaire ou encore de forme sigmoïde (en S): c’est-à -dire avec une première phase de croissance faible, suivie d’une phase linéaire, puis se terminant par une phase de décélération progressive jusqu’à l’obtention d’un plateau.
Comme expliqué précédemment, la modélisation consiste à mettre en relation les réponses, avec les doses (ou concentrations), à travers une équation mathématique. Cette équation repose sur un modèle qui comporte des paramètres (la pente et l’ordonnée à l’origine si on veut faire une analogie à la régression linéaire simple).
Autrement dit, il s’agit d’exprimer la réponse en fonction de la dose et des paramètres d’un modèle:
\[{reponse} = f(dose, \text{ paramètres du modèle})\]
Ou de manière plus formelle :
\[ y = f(x, \beta) \]
Voici trois exemples de modèles très couramment employés :



Les modélisations dose réponse sont généralement employés dans deux buts précis.
Le premier de ces buts, peut être de caractériser la relation entre les réponses et les doses, par l’intermédiaire d’un paramètre du modèle employé, qui a une signification bien précise. Par exemple, le paramètre « e » du modèle log-logistique, présenté précédemment, correspond à l’ED50 (la dose pour laquelle on observe 50% d’effet). De même le paramètre b correspond à la pente au niveau de l’ED50 (ou EC50), c’est à dire la vitesse d’évolution de la réponse par unité de dose, autour de l’ED50.
Le second but, peut être la prédiction. Il peut s’agir de prédire une réponse en fonction d’une dose.

Ou à l’inverse, prédire une dose, pour une réponse donnée:

Comme expliqué précédemment, la forme de la relation entre les réponses et les doses, observée sur des systèmes biologiques est généralement curvi-linéaire ou sigmoide.
Mais ce qui est important de comprendre, c’est que l’équation de ces modèles est non linéaire dans ces paramètres. Autrement dit, il ne s’agit pas d’une simple addition de paramètres :
\[ y=Asym\times exp(-(\frac{m}{c})\times exp(-c\times x)\]
\[ y=\frac{Vm\times x}{ K+ x}\]
Et cette non-linéarité des paramètres va avoir un impact sur la façon de les estimer.
Comme pour la régression linéaire simple, les coefficients des paramètres (beta) du modèle sont estimés par la méthode des moindre carrés. Il s’agit de trouver la courbe qui passe au mieux des points expérimentaux, en minimisant la somme des écarts (ou résidus) au carré (SRC) entre les points et la courbe :
\[SCR(\beta)=\sum(y_i – f(x_i, \beta))^2 = \sum(y_i – \hat{y_i})\]

Dans le cas de modèles non-linéaires (dans leurs paramètres), l’estimation des paramètres du modèle est plus complexe car :
Les étapes sont un peu différentes si la réponse est de type numérique continu ou de type binaire. Nous allons ici nous cantonner au cas des données numériques continues.
Ces données peuvent être obtenues à partir d’une expérimentation dose réponse :

Il s’agit de vérifier la forme de la relation :

Le choix du modèle dépend de la forme de la relation (curvi-linéaire, sigmoïde), et des habitudes. Par exemple, deux modèles peuvent avoir des courbes très similaires, mais des paramètres avec des significations différentes; certains sont habituellement utilisés dans certaines disciplines (cancérologie par exemple), et d’autres classiquement employés dans d’autres disciplines (écologie par exemple).
Par exemple, le modèle log-logistique de base comporte 4 paramètres :
\[y=c+\frac{(d-c)}{[1+exp(b(log(x)-log(e)))]}\]
Avec :

Mais un modèle à 3 paramètres, avec une limite basse (c=0) peut également être envisagé (voir plus loin)
Un test statistique d’évaluation de la qualité d’ajustement du modèle aux données observées (Lack of fit) peut être employé.
Ce test statistique consiste à comparer, à l’aide d’un test F, l’ajustement du modèle employé, avec celui d’un modèle plus général, qui sert de référence, et qui est celui de l’ANOVA. Le modèle ANOVA spécifie seulement une moyenne pour chaque niveau de dose, mais sans relation entre ces moyennes.
L’hypothèse nulle du test « Lack of fit » spécifie que l’ajustement du modèle testé est aussi bon que celui du modèle de référence (ANOVA).
A l’inverse, l’hypothèse alternative spécifie que l’ajustement du modèle testé est moins bon que celui du modèle de référence.
Ainsi, si la pvalue est <0 .05 alors l’hypothèse nulle est rejetée, et le modèle est considéré comme non satisfaisant. A l’inverse si la p-value est >0.05, alors rien ne permet de rejeter l’hypothèse d’un modèle satisfaisant.

Pour que le test soit valide, il est nécessaire, au préalable de vérifier la normalité et l’homogénéité des résidus.
Il s’agit par exemple d’ajuster un modèle log-logistique plus simple, à 3 paramètres, spécifiant que la limite basse (paramètre c) est égale à 0.
Puis de comparer les ajustements avec un test F, comparable à celui du test « lack of fit »:

L’hypothèse nulle spécifie que l’ajustement du modèle restreint est aussi bon que celui du modèle complet. A l’inverse, l’hypothèse alternative spécifie que l’ajustement du modèle restreint est significativement moins bon que celui du modèle complet.
Ainsi, si la pvalue est <0.05, alors le modèle complet sera retenu, et si la pvalue est >0.05 alors rien ne permet d’affirmer que l’ajustement du modèle restreint est moins bon. Dans cette situation, en vertu du principe de Parcimonie, c’est le modèle restreint qui sera conservé.
Un fois le modèle définitif sélectionné, les paramètres et leur erreur standard peuvent être estimés
Enfin, les prédictions désirées peuvent être réalisées. Il peut, par exemple, s’agir d’estimer la dose correspondant à 10% d’effet. Ou à l’inverse d’estimer la réponse (ou la variation de réponse par rapport au contrôle) attendue pour une dose donnée.
Il existe plusieurs packages disposant de fonctions facilitant la modélisation des relations dose réponse.
Personnellement, j’ai toujours employé le package `drc`développé par Christian Ritz. Il dispose de nombreux modèles prédéfinis, et la fonction `drm` permettant la modélisation se charge automatiquement de fournir valeurs initiales des paramètres, à l’algorithme d’optimisation numérique
library(drc) La liste des différents modèles prédéfinis dans le package `drc` peut être consultée en employant la commande suivante :
help(package = "drc") Nous allons ici modéliser les données ryegrass qui sont inclues dans le package drc. Ces données sont issues d’une étude visant à étudier l’action conjointe des acides phénoliques sur l’inhibition de la croissance des racines de la plante Lolium perenne.
ryegrass
## rootl conc
## 1 7.5800000 0.00
## 2 8.0000000 0.00
## 3 8.3285714 0.00
## 4 7.2500000 0.00
## 5 7.3750000 0.00
## 6 7.9625000 0.00
## 7 8.3555556 0.94
## 8 6.9142857 0.94
## 9 7.7500000 0.94
## 10 6.8714286 1.88
## 11 6.4500000 1.88
## 12 5.9222222 1.88
## 13 1.9250000 3.75
## 14 2.8857143 3.75
## 15 4.2333333 3.75
## 16 1.1875000 7.50
## 17 0.8571429 7.50
## 18 1.0571429 7.50
## 19 0.6875000 15.00
## 20 0.5250000 15.00
## 21 0.8250000 15.00
## 22 0.2500000 30.00
## 23 0.2200000 30.00
## 24 0.4400000 30.00 La variable conc est la concentration d’acide férulique en mM, 6 niveaux sont testés.
La variable rootl est la longueur des racines de la plante, mesurée en cm.
Le package drc dispose d’une fonction plot() qui est pratique à employer :
plot(ryegrass$conc,ryegrass$rootl,lwd=2,col=3) 
Comme les données sont un peu écrasées, nous pouvons employer une échelle log sur l’axe des concentrations, en employant l’argument log="x":
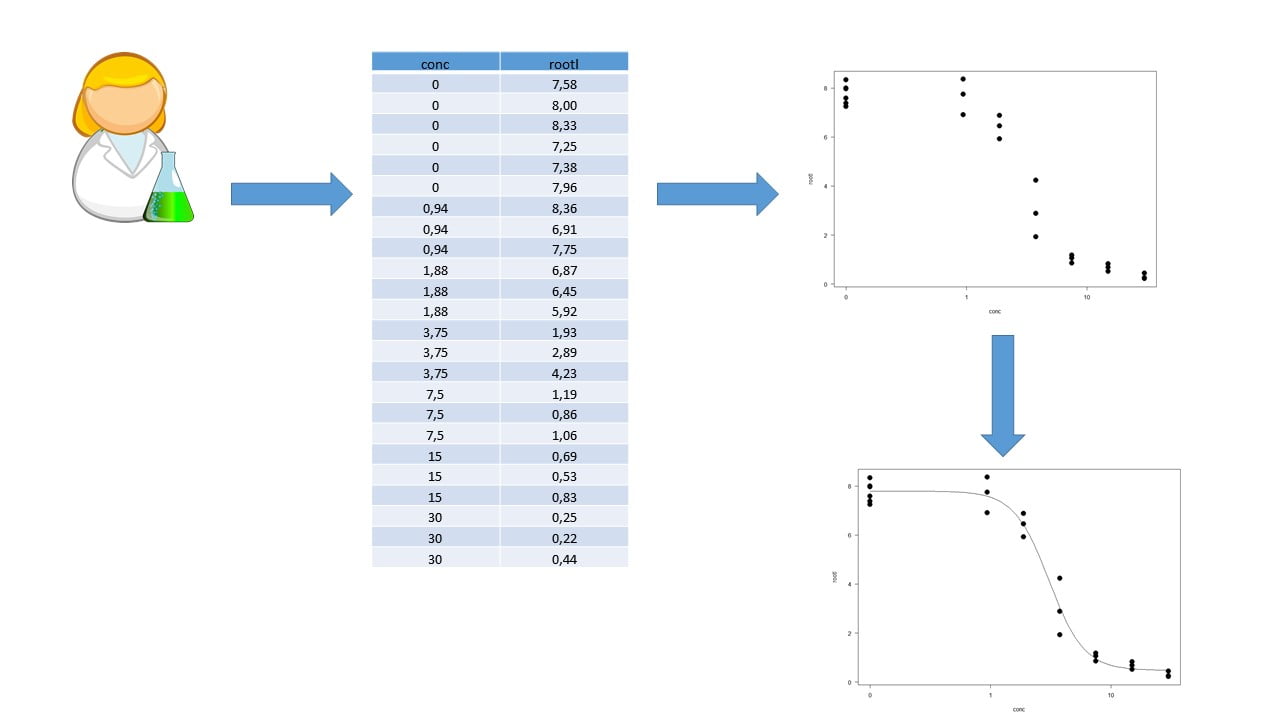
plot(ryegrass$conc,ryegrass$rootl,lwd=2,col=3, log="x") 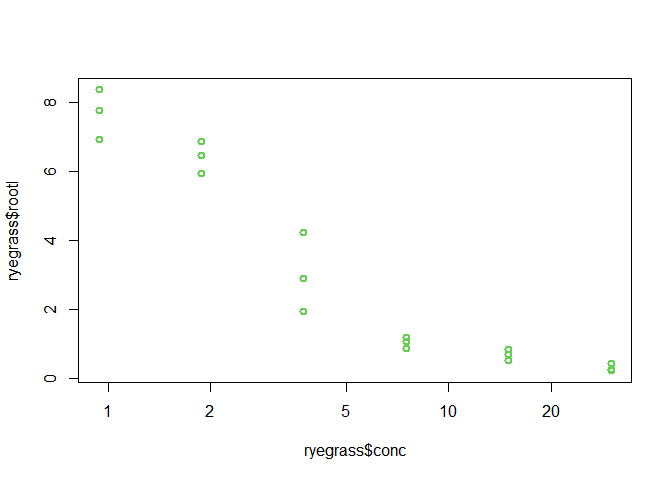
Nous pouvons voir que la relation entre la longueur des racines et la concentration est d’allure sigmoïde.
Une relation dose réponse d’allure sigmoïde peut être modélisé à l’aide d’un modèle log-logistique à 4 paramètres.
\[y=c+\frac{(d-c)}{[1+exp(b(log(x)-log(e)))]}\]
Avec :
L’ajustement se réalise en employant la fonction drm. Le modèle log-logistique à 4 paramètres peut être sélectionné en employant la fonction LL.4() :
ryegrass.ll4 <- drm(rootl~conc, data=ryegrass, fct=LL.4()) Pour visualiser l’estimation des paramètres et celle de leur erreur standard, il suffit d’employer la fonction summary(), comme ceci :
summary(ryegrass.ll4)
Model fitted: Log-logistic (ED50 as parameter) (4 parms)
Parameter estimates:
Estimate Std. Error t-value p-value
b:(Intercept) 2.98222 0.46506 6.4125 2.960e-06 ***
c:(Intercept) 0.48141 0.21219 2.2688 0.03451 *
d:(Intercept) 7.79296 0.18857 41.3272 < 2.2e-16 ***
e:(Intercept) 3.05795 0.18573 16.4644 4.268e-13 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error:
0.5196256 (20 degrees of freedom) Nous pouvons aussi visualiser le modèle en ajoutant l’argument type="all à la fonction plot():
plot(ryegrass.ll4,type="all",col=3,lwd=2) 
Pour rappel, la normalité et l’homogénéité des résidus sont nécessaires à la validité du test d’évaluation de la qualité d’ajustement, et à celle du test F de réduction du modèle. Cette condition peut être évaluée graphiquement à l’aide d’un qqplot :
library(car)
qqPlot(residuals(ryegrass.ll4) 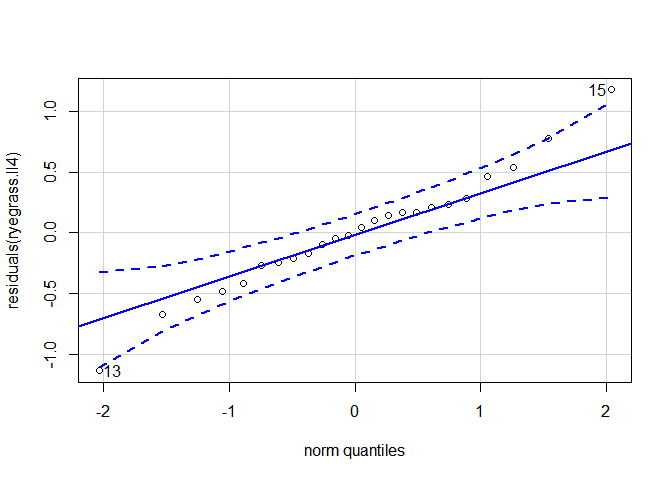
Les points sont globalement bien alignés le long de la droite. Ainsi, aucun défaut de normalité n’est mis en évidence. Le test de Shapiro-Wilk peut également être employé :
shapiro.test(residuals(ryegrass.ll4))
Shapiro-Wilk normality test
data: residuals(ryegrass.ll4)
W = 0.98232, p-value = 0.9345 L’hypothèse nulle spécifie la normalité des résidus, alors que l’hypothèse alternative spécifie la non-normalité. La p-value étant >0.05, rien ne permet de rejeter cette hypothèse de normalité.
Cette condition peut être évaluée visuellement à l’aide du graphique suivant :
plot(fitted(ryegrass.ll4),(residuals(ryegrass.ll4,type="standardised"))) 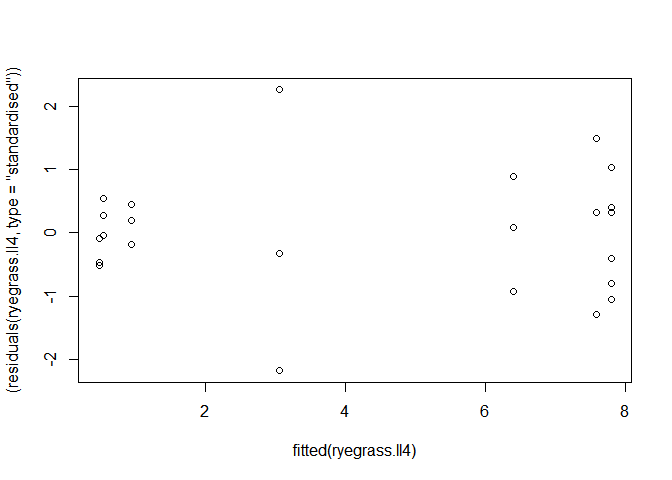
Le graphique met en évidence des dispersions de résidus plutôt différentes entre les niveaux de concentration. L’homogénéité semble plutôt rejetée.
Les tests de Levene et de Bartlett peuvent également être employés. L’hypothèse nulle de ces tests spécifie l’homogénéité des résidus, alors que l’hypothèse alternative spécifie la non-homogénéité.
library(car)
leveneTest(residuals(ryegrass.ll4),as.factor(ryegrass$conc))
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 6 1.9266 0.1344
17
bartlett.test(residuals(ryegrass.ll4),as.factor(ryegrass$conc))
Bartlett test of homogeneity of variances
data: residuals(ryegrass.ll4) and as.factor(ryegrass$conc)
Bartlett's K-squared = 13.216, df = 6, p-value = 0.03973 Les résultats de ces tests sont contradictoires. Au final, nous pouvons retenir la présence d’un défaut d’homogénéité des résidus.
Une transformation Box Cox (généralisation d’une transformation log) peut alors être employée pour essayer d’obtenir l’homogénéité des résidus. Le package `drc` dispose d’une fonction `boxcox()` pour réaliser cette transformation.
Lorsque nous affichons les résultats de la modélisation, nous pouvons voir qu’un paramètre lambda a été estimé ; sa valeur est de 0.5.
ryegrass.ll4BC<-boxcox(ryegrass.ll4) 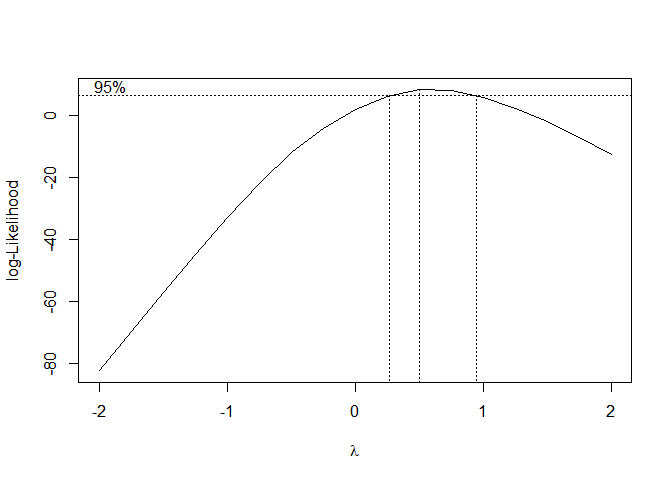
summary(ryegrass.ll4BC)
Model fitted: Log-logistic (ED50 as parameter) (4 parms)
Parameter estimates:
Estimate Std. Error t-value p-value
b:(Intercept) 2.61839 0.39151 6.6880 1.649e-06 ***
c:(Intercept) 0.39083 0.10429 3.7474 0.001269 **
d:(Intercept) 7.86633 0.29558 26.6136 < 2.2e-16 ***
e:(Intercept) 3.01662 0.21005 14.3612 5.354e-12 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error:
0.2962958 (20 degrees of freedom)
Non-normality/heterogeneity adjustment through optimal Box-Cox transformation
Estimated lambda: 0.5
Confidence interval for lambda: [0.269,0.949] qqPlot(residuals(ryegrass.ll4BC)) 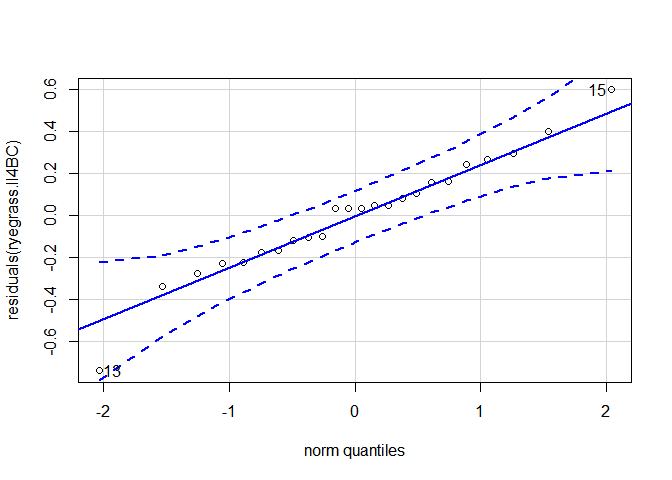
Aucun défaut de normalité n’est mis en évidence, comme précédemment.
L’évaluation de l’homogénéité, ne met plus en évidence de défaut :
plot(fitted(ryegrass.ll4BC),(residuals(ryegrass.ll4BC,type="standardised"))) 
bartlett.test(residuals(ryegrass.ll4BC),as.factor(ryegrass$conc))
Bartlett test of homogeneity of variances
data: residuals(ryegrass.ll4BC) and as.factor(ryegrass$conc)
Bartlett's K-squared = 9.1898, df = 6, p-value = 0.1632
leveneTest(residuals(ryegrass.ll4),as.factor(ryegrass$conc))
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 6 1.9266 0.1344
1 modelFit(ryegrass.ll4BC)
## Lack-of-fit test
##
## ModelDf RSS Df F value p value
## ANOVA 17 1.4292
## DRC model 20 1.7558 3 1.2949 0.3084 La p-value est >0.05, rien ne permet de rejeter l’hypothèse nulle. Ainsi le modèle log-logistique à 4 paramètres est considéré comme satisfaisant.
Il s’agit d’ajuster un modèle log-logistique à 3 paramètres, qui spécifie que la limite basse (paramètre c) est égale à 0. Ce modèle est nommé `LL.3()`.
Puisque nous avons employé une transformation Box Cox, nous devons spécifier la valeur du paramètre Lambda, en utilisant l’argument `bcVal=0.5` :
ryegrass.ll3BC<-drm(rootl~conc,data=ryegrass,bcVal=0.5,fct=LL.3())
plot(ryegrass.ll3BC,col=3,lwd=2,type="all") 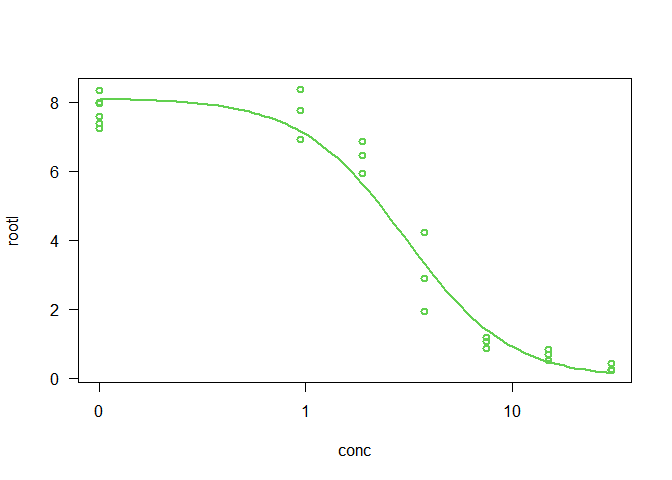
Nous pouvons comparer les ajustements du modèle complet et du modèle restreint, à l’aide de la fonction anova()
anova(ryegrass.ll4BC,ryegrass.ll3BC)
1st model
fct: LL.3()
2nd model
fct: LL.4()
ANOVA table
ModelDf RSS Df F value p value
2nd model 21 2.8883
1st model 20 1.7558 1 12.9002 0.0018 Ici, la p-value est inférieure à 0.05, l’ajustement du modèle à 3 paramètres est donc significativement moins bon que celui à 4 paramètres. C’est donc le modèle à 4 paramètres qui est conservé. Les résultats ont été affichés précédemment.
Pour cela, nous employons la fonction ED(), comme ceci :
ED(ryegrass.ll4BC,c(10,25,50),interval="delta")
Estimated effective doses
Estimate Std. Error Lower Upper
e:1:10 1.30341 0.21405 0.85690 1.74992
e:1:25 1.98290 0.21698 1.53029 2.43550
e:1:50 3.01662 0.21005 2.57846 3.45478 Pour cela, nous employons la fonction predict(), en spécifiant les doses désirées (ici 1,5 et 10) à l’aide du terme data.frame(c(1,5,10))
predict(ryegrass.ll4BC,data.frame(c(1,5,10)),se.fit=T,interval="confidence")
Prediction SE Lower Upper
[1,] 7.4731410 0.24975785 0 0
[2,] 1.9629818 0.21928881 0 0
[3,] 0.7015609 0.09606095 0 0 
J’espère que cet article vous aura intéressé, et qu’après sa lecture, la modélisation des relations dose réponse vous sera plus familière !
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
21 réponses
Bonjour Claire merci pour les efforts consentis de tous les jours pour nous donner gratuitement ces connaissances en statistiques.
Dieu te bénisse
J’aimerais demander si tu peux nous aider avec un article sur les équations structurelles.
Merci
Bonjour Kora
Je ne connais pas du tout ce sujet des équations structurelles, alors si j’écrit un article, ça ne sera pas pour tout de suite !
Bonne continuation.
Super article ! J’avais justement lu la publication que vous mettez à la fin, et c’est vrai qu’aborder le sujet directement par ce biais, c’est un peu brut. Donc super description pour introduire cette notion. Merci 😉
Bonjour Enora,
merci pour votre commentaire.
Bonne continuation.
Il existe aussi le package ‘morse’ : https://CRAN.R-project.org/package=morse, interface web depuis la plateforme MOSAIC.
Bonjour Sandrine,
merci pour la piqûre de rappel et le partage !
Bonjour,
Bel article de synthèse (comme d’habitude!). merci.
L’estimation des parametres d’une fonction dans le package drm fait-elle appel à la méthode du « recuit simulé »?
Pourriez-vous un jour nous donner un aperçu de cette méthode ? (et la comparer à d’autres en termes d’efficacité d’estimation)?
Merci beaucoup pour votre blog.
Bonjour Frédée,
je ne sais pas du tout. Si vous voulez plus d’information sur ce sujet, je vous conseille de contacter Christian Ritz, le développeur du package.
Je ne pense pas écrire d’article sur ce sujet prochainement.
Bonne continuation.
Bonjour Claire, très intéressant et Merci.
Merci Chedly !
Bonne continuation.
Bonjour,
Merci pour toutes ces connaissances que vous nous apportez. Mais savez-vous comment faire une modélisation avec un système d’équations différentielles lorsque les paramètres sont inconnus ?
Ou disons une régression non linéaire avec des paramètres inconnus ? J’aimerais découvrir tout le processus de détermination des paramètres jusqu’à la prédiction.
Merci et bonne continuation
Bonjour,
je ne connais pas ces domaines, vous trouverez peut être des infos dans cet ouvrage : https://www.springer.com/gp/book/9780387096155
Bonne continuation
Bonjour Claire,
Merci pour cet article qui est très claire et très bien fait.
J’ai un problème avec l’homogénéité de mes résidus qui est rejetée même avec une transformation boxcox. As tu d’autres propositions ou des liens qui en parlent ?
Merci
Bonjour Pauline
Ce n’est pas facile dans cette situation….. Il faudrait explorer qu’est ce qui est responsable du rejet de l’hypothèse, est-ce vous avez des outliers ? Si oui vous pouvez refaire l’analyse sans pour vérifier que vous obtenez des résultats assez similaires. Sinon, essayer une autre transformation ….mais normalement la transfo boxocox est la meillleure solution, mais vous pouvez peut être essayer la racine carrée…
Bonne continuatino.
Bonjour Claire,
Merci beaucoup pour la qualité de vos articles et tous vos partages d’expériences et de connaissances. Je vous ai eu en cours également et j’vais beaucoup apprécié vos explications.
Je voudrais utiliser la modélisation dose-réponse pour comparer 2 traitements donnés à des doses différentes (pour l’un il s’agit d’un dosage qui augmente en fonction du poids et pour l’autre c’est le contraire, un dosage dégressif en fonction du poids). Je voudrais m’assurer que le dosage dégressif n’est pas délétère sur la prise de poids et l’atteinte du seuil d’un autre indicateur (un périmètre brachial >124) comparé au dosage qui augmente. L’hypothèse dans mon étude est de montrer que qu’il n’est pas nécessaire d’augmenter les doses passées un certain seuil mais au contraire qu’il est pertinent de les diminuer sinon en résumé on gaspille le ttt donné qui n’est pas assimilé par l’organisme.
Désolé pour tous ces détails mais pensez-vous que la modélisation dose-réponse est adapté dans mon cas et que je peux comparée la réponse en fonction de deux dosages ?
Bien à vous,
Cécile
Bonjour Cécile,
je ne suis pas sûre de comprendre votre expérimentation. D’après mon expérience, l’intérêt de la modélisation dose réponse c’est surtout de pouvoir estimer un paramètre qui a un intérêt et qui correspond à un paramètre du modèle. Par exemple la pente au niveau de l’ED50, ou l’ED50, avec un modèle log-logistqiue (de forme sigmoide). En ensuite de pouvoir les comparer entre deux traitements, par exemple.
J’espère que ma réponse vous aide un peu.
Bonne continuation
Bonjour Claire,
Vos articles très didactiques sont toujours une excellente source d’inspiration.
Je suis confronté à un cas où l’approche dose-réponse me semble a priori inappropriée car les données que j’analyse présentent à mon sens un caractère censuré. J’observe une réponse binaire (intact ou cassé) en fonction d’une sollicitation (force d’impact) : j’ai donc censure à droite si le résultat est « intact » (la force nécessaire pour casser est supérieure à celle de l’essai), censure à gauche si le résultat est « casse » (le seuil de rupture est inférieur à la force dans l’essai concerné). Quelle approche pourriez-vous me suggérer pour estimer la courbe de risque de casse en fonction de la force, idéalement avec son intervalle de confiance ?
Bien à vous
Bonjour Oliver,
Je n’ai pas bien compris le cas des censures à gauche » le seuil de rupture est inférieur à la force dans l’essai concerné », vous ne faites pas croire la force ? La cassure est présente au départ ?
Pour la censure à droite, on peut penser que si elle augmente, tous les éléments vont casser. Dans ce cas, vous pouvez bien utiliser une modélisation dose réponse. Le modèle log-logistique a plusieurs variantes ( 4 paramètres, 3 paramètres et 2 paramètres).
4 paramètres : il modélisera au mieux Ymin et ymax
3 paramètres : soit ymax = 1 , soit y min =0 (il y a deux variantes du modèle à 3 paramètres)
2 paramètres : ymin est forcé à 0 et y max forcé à 1.
Si ça ne correspond pas à votre problème, peut-être qu’une courbe de survie de type Kaplan Meier pourrait convenir (sans certitude – à creuser)
J’espère que cela vous aide un peu
Bonne continuation.
Claire Della Vedova
Bonjour Claire,
Merci pour ton blog très intéressant et utile !
Une question :
Si on souhaite faire une analyse dose réponse sur des données de reproduction il me semble qu’il convient d’utiliser une distribution de Poisson (type = « Poisson » dans drm).
Mais la fonction modelFit dans le package drc ne semble pas compatible avec une telle distribution (voir https://rdrr.io/cran/drc/src/R/modelFit.R). La fonction mselect (pour comparer des modèles entre-eux (e.g. LL.3 et W1.3) sur certains critères (AIC/BIC, Lack-of-fit, etc.)) ne fonctionne pas non plus.
Aurais-tu un conseil sur ce qu’il faudrait faire dans ce cas pour estimer la qualité du modèle et pour comparer des modèles entre eux ?
Merci
Adrien
Manque les unités dans les titres des axes du graphiques du coup on sait pas de quoi ils parles
Bonjour Adrien,
Il vous suffit d’aller faire un petit tour sur la page d’aide du dataset et vous trouverez les unités !
Le but de cet article était seulement de montrer la démrache de modélisation en pas à pas.
Bonne continuation