| ID_Sujet | Tension_T0 | Tension_T3 | Tension_T6 |
|---|---|---|---|
| SUBJ_001 | 120 | 115 | 112 |
| SUBJ_002 | 130 | 128 | 125 |
| SUBJ_003 | 110 | 108 | 105 |
| SUBJ_004 | 140 | 135 | 132 |
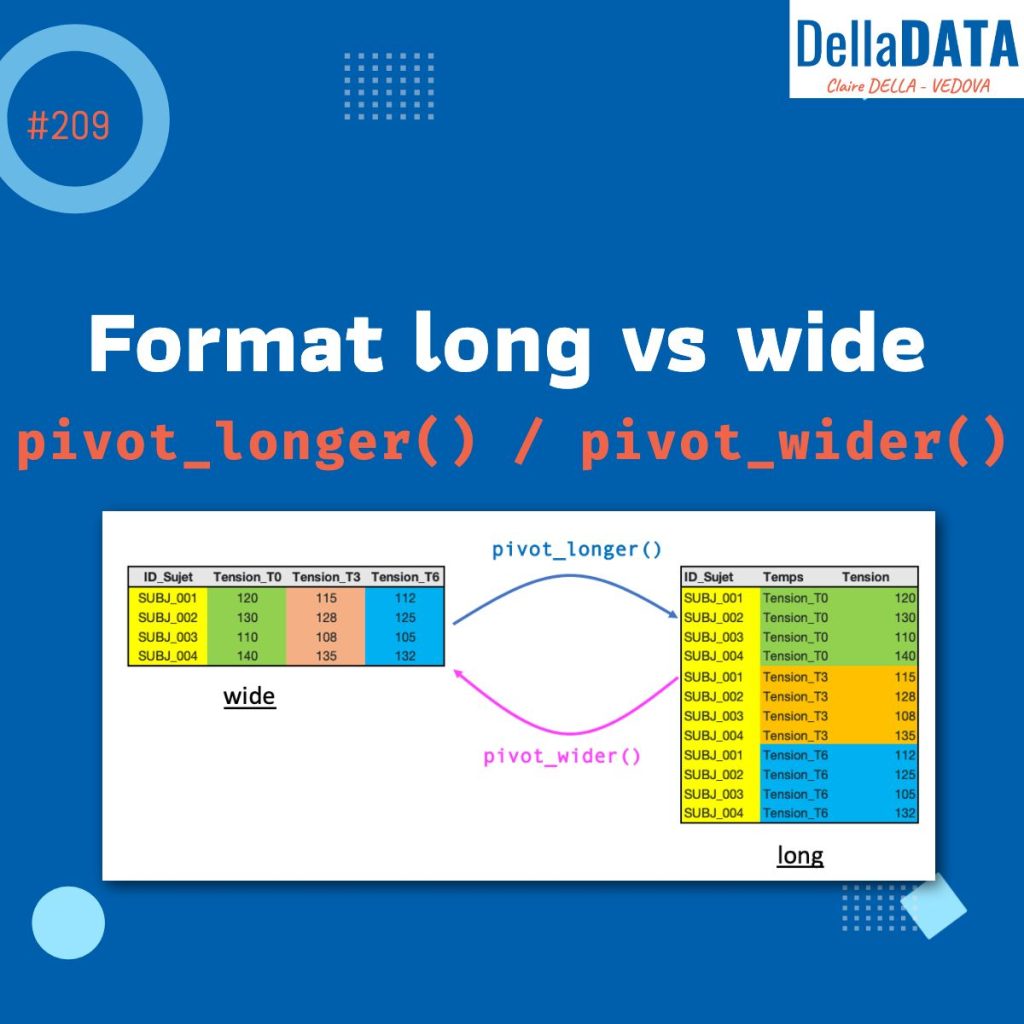
Quand on travaille avec des données sous R, il arrive très souvent de se retrouver bloqué… non pas à cause des analyses, mais à cause de la structure du jeu de données.
Dans beaucoup de cas, le problème ne vient pas de votre code… mais du format de vos données.
Dans cet article, nous allons voir comment passer facilement du format wide au format long (et inversement), et surtout pourquoi cette transformation est souvent la clé pour simplifier vos analyses sous R.
Le format “wide” est le plus courant pour stocker des données. Chaque ligne correspond à une observation, et chaque variable est stockée dans une colonne distincte.
Voici un exemple avec des mesures répétées :
| ID_Sujet | Tension_T0 | Tension_T3 | Tension_T6 |
|---|---|---|---|
| SUBJ_001 | 120 | 115 | 112 |
| SUBJ_002 | 130 | 128 | 125 |
| SUBJ_003 | 110 | 108 | 105 |
| SUBJ_004 | 140 | 135 | 132 |
Ici, chaque sujet est représenté sur une seule ligne, avec plusieurs colonnes correspondant aux différents temps de mesure.
Dans le format long, les données sont organisées différemment :
Chaque mesure devient une ligne.
| ID_Sujet | Temps | Tension |
|---|---|---|
| SUBJ_001 | Tension_T0 | 120 |
| SUBJ_001 | Tension_T3 | 115 |
| SUBJ_001 | Tension_T6 | 112 |
| SUBJ_002 | Tension_T0 | 130 |
| SUBJ_002 | Tension_T3 | 128 |
| SUBJ_002 | Tension_T6 | 125 |
| SUBJ_003 | Tension_T0 | 110 |
| SUBJ_003 | Tension_T3 | 108 |
| SUBJ_003 | Tension_T6 | 105 |
| SUBJ_004 | Tension_T0 | 140 |
| SUBJ_004 | Tension_T3 | 135 |
| SUBJ_004 | Tension_T6 | 132 |
On passe donc d’un tableau “large” à un tableau “long”, beaucoup plus adapté à l’analyse.
À ce stade, vous vous demandez peut-être comment passer concrètement d’un format à l’autre — c’est exactement ce que nous allons voir dans la suite de l’article.
Le choix du format dépend avant tout de ce que vous souhaitez faire avec vos données.
Le format wide est adapté lorsque :
Le format long est souvent à privilégier lorsque vous souhaitez :
Pour passer du format wide au format long en R, on utilise la fonction pivot_longer() du package {tidyr}. Elle permet de regrouper plusieurs colonnes en deux colonnes principales :
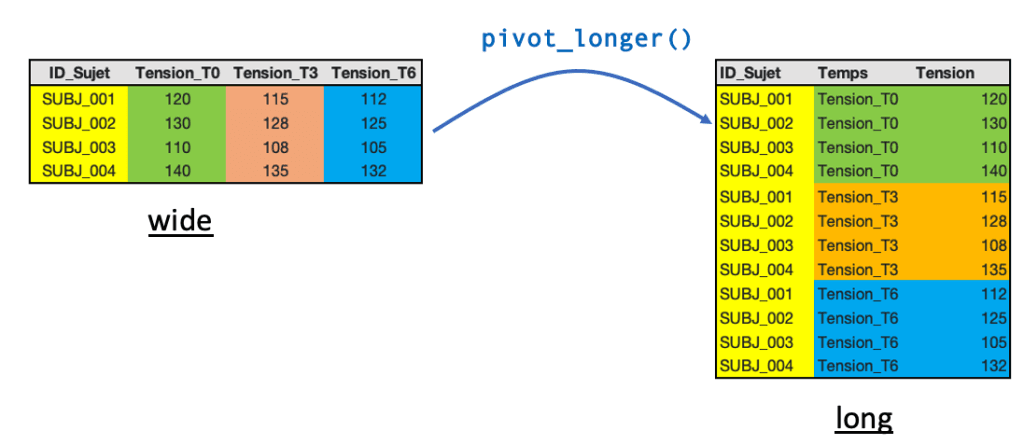
Prenons notre jeu de données de tension artérielle :
# creation des data au format wide
data_wide <- data.frame(
ID_Sujet = paste0("SUBJ_00",1:4),
Tension_T0 = c(120, 130, 110, 140),
Tension_T3 = c(115, 128, 108, 135),
Tension_T6 = c(112, 125, 105, 132)
)
# affichage des 6 premières lignes
head(data_wide)
ID_Sujet Tension_T0 Tension_T3 Tension_T6
1 SUBJ_001 120 115 112
2 SUBJ_002 130 128 125
3 SUBJ_003 110 108 105
4 SUBJ_004 140 135 132 On peut le transformer ainsi :
# Charger le package nécessaire
library(tidyr)
# Convertir le jeu de données du format wide au format long
data_long <- data_wide |>
pivot_longer(
cols = Tension_T0:Tension_T6,
names_to = "Temps",
values_to = "Tension"
)
Explications :
pivot_longer(): cette fonction du package {tidyr} permet de transformer plusieurs colonnes en un format plus long, avec une colonne contenant les noms des anciennes colonnes et une autre contenant les valeurs correspondantes.
cols = Tension_T0:Tension_T6 : cet argument indique quelles colonnes doivent être pivotées. Ici, on transforme toutes les colonnes allant de Tension_T0 à Tension_T6.
names_to = "Temps": cet argument crée une nouvelle colonne appelée Temps, qui contient les noms des colonnes d’origine, ici Tension_T0, Tension_T3 et Tension_T6.
values_to = "Tension": cet argument crée une nouvelle colonne appelée Tension, qui contient les valeurs associées à chacun des temps de mesure.
On obtient alors un jeu de données où chaque sujet apparaît sur plusieurs lignes, une ligne par temps de mesure
# affichage du résultat
data_long
# A tibble: 12 × 3
ID_Sujet Temps Tension
<chr> <chr> <dbl>
1 SUBJ_001 Tension_T0 120
2 SUBJ_001 Tension_T3 115
3 SUBJ_001 Tension_T6 112
4 SUBJ_002 Tension_T0 130
5 SUBJ_002 Tension_T3 128
6 SUBJ_002 Tension_T6 125
7 SUBJ_003 Tension_T0 110
8 SUBJ_003 Tension_T3 108
9 SUBJ_003 Tension_T6 105
10 SUBJ_004 Tension_T0 140
11 SUBJ_004 Tension_T3 135
12 SUBJ_004 Tension_T6 132 Remarque:
On peut encore améliorer la lisibilité du résultat en supprimant le préfixe “Tension_” dans la colonne Temps. Pour cela, on utilise l’argument names_prefix = "Tension_", comme ceci :
data_long2 <- data_wide |>
pivot_longer(
cols = Tension_T0:Tension_T6,
names_to = "Temps",
names_prefix = "Tension_",
values_to = "Tension"
)
# affichage du résultat
data_long2
# A tibble: 12 × 3
ID_Sujet Temps Tension
<chr> <chr> <dbl>
1 SUBJ_001 T0 120
2 SUBJ_001 T3 115
3 SUBJ_001 T6 112
4 SUBJ_002 T0 130
5 SUBJ_002 T3 128
6 SUBJ_002 T6 125
7 SUBJ_003 T0 110
8 SUBJ_003 T3 108
9 SUBJ_003 T6 105
10 SUBJ_004 T0 140
11 SUBJ_004 T3 135
12 SUBJ_004 T6 132 C’est le genre d’ajustement qui peut être très utile, notamment lorsqu’on souhaite réaliser un graphique par la suite.
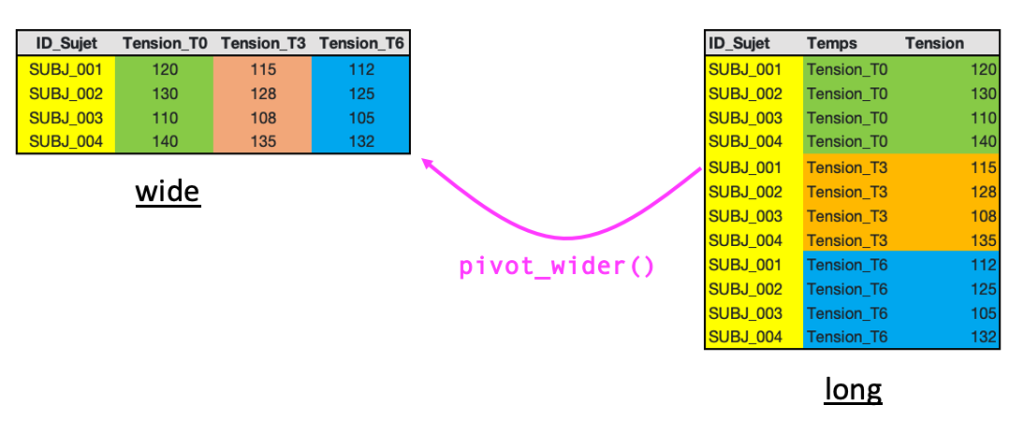
Une fois les données passées au format long, il est tout à fait possible de revenir au format wide grâce à la fonction pivot_wider() du package {tidyr}.
Cette fonction permet de répartir les valeurs d’une colonne en plusieurs colonnes, en fonction des modalités d’une autre variable.
Prenons le jeu de données précédemment transformé au format long :
# affichage des data_long
data_long
# A tibble: 12 × 3
ID_Sujet Temps Tension
<chr> <chr> <dbl>
1 SUBJ_001 Tension_T0 120
2 SUBJ_001 Tension_T3 115
3 SUBJ_001 Tension_T6 112
4 SUBJ_002 Tension_T0 130
5 SUBJ_002 Tension_T3 128
6 SUBJ_002 Tension_T6 125
7 SUBJ_003 Tension_T0 110
8 SUBJ_003 Tension_T3 108
9 SUBJ_003 Tension_T6 105
10 SUBJ_004 Tension_T0 140
11 SUBJ_004 Tension_T3 135
12 SUBJ_004 Tension_T6 132 # Convertir le jeu de données du format long au format wide
data_wide_new <- data_long |>
pivot_wider(
names_from = Temps,
values_from = Tension
) Explications :
pivot_wider(): cette fonction du package {tidyr} permet de transformer des données du format long vers un format wide, en répartissant les valeurs d’une colonne sur plusieurs colonnes.names_from = Temps: cet argument indique que les valeurs de la colonne Temps vont être utilisées pour créer les noms des nouvelles colonnes (par exemple Tension_T0, Tension_T3, Tension_T6).values_from = Tension : cet argument précise que les valeurs à répartir dans ces nouvelles colonnes proviennent de la colonne Tension.On obtient ainsi un jeu de données où chaque sujet est à nouveau représenté sur une seule ligne, avec une colonne par temps de mesure :
# Affichage du résultat
# A tibble: 4 × 4
ID_Sujet Tension_T0 Tension_T3 Tension_T6
<chr> <dbl> <dbl> <dbl>
1 SUBJ_001 120 115 112
2 SUBJ_002 130 128 125
3 SUBJ_003 110 108 105
4 SUBJ_004 140 135 132 On retrouve donc une structure équivalente à celle du jeu de données initial.
Et si on part du jeu de données sur lequel on a supprimé le préfixe “Tension_”, alors il faut reconstruire les noms de colonnes en ajoutant à nouveau ce préfixe, comme ceci , à l’aide de l’argument : names_prefix = "Tension_"
data_wide_new2 <- data_long2 |>
pivot_wider(
names_from = Temps,
values_from = Tension,
names_prefix = "Tension_"
)
# affichage du résultat
data_wide_new2
# A tibble: 4 × 4
ID_Sujet Tension_T0 Tension_T3 Tension_T6
<chr> <dbl> <dbl> <dbl>
1 SUBJ_001 120 115 112
2 SUBJ_002 130 128 125
3 SUBJ_003 110 108 105
4 SUBJ_004 140 135 132 Cela montre que le passage du format wide au format long (et inversement) est entièrement maîtrisable, à condition de bien comprendre comment les noms de variables sont transformés.
Lorsque plusieurs variables sont mesurées à différents moments (par exemple la tension artérielle et la fréquence cardiaque), il existe deux façons principales de structurer les données en format long.
On peut :
Les deux approches sont valides, mais correspondent à des usages différents.
Exemple de départ:
# création de data au format wide avec plusieurs variables à pivoter
data_wide_multi <- data.frame(
ID_Sujet = 1:4,
Tension_T0 = c(120, 130, 110, 140),
Tension_T3 = c(115, 128, 108, 135),
Frequence_T0 = c(70, 75, 68, 80),
Frequence_T3 = c(68, 73, 65, 78)
)
# affichage des données créées
data_wide_multi
ID_Sujet Tension_T0 Tension_T3 Frequence_T0 Frequence_T3
1 1 120 115 70 68
2 2 130 128 75 73
3 3 110 108 68 65
4 4 140 135 80 78 Dans cette approche, on crée :
Tempsvaleurvariable qui contient les modalités Tension ou Frequencedata_long_multi1 <- data_wide_multi |>
pivot_longer(
cols = -ID_Sujet,
names_to = c("variable", "Temps"),
names_sep = "_",
values_to = "valeur"
)
# affichage du résultat
data_long_multi1
# A tibble: 16 × 4
ID_Sujet variable Temps valeur
<int> <chr> <chr> <dbl>
1 1 Tension T0 120
2 1 Tension T3 115
3 1 Frequence T0 70
4 1 Frequence T3 68
5 2 Tension T0 130
6 2 Tension T3 128
7 2 Frequence T0 75
8 2 Frequence T3 73
9 3 Tension T0 110
10 3 Tension T3 108
11 3 Frequence T0 68
12 3 Frequence T3 65
13 4 Tension T0 140
14 4 Tension T3 135
15 4 Frequence T0 80
16 4 Frequence T3 78
Explications
Les noms des colonnes contiennent en réalité deux informations :
L’objectif est donc de séparer ces deux informations pour les stocker dans des colonnes distinctes.
Par exemple, “Tension_T0” est découpé en “Tension” et “T0”.
names_to = c("variable", "Temps") précise dans quelles colonnes placer ces deux informations, autrement dit c’est le nom des nouvelles colonnes :variableTempsnames_sep = "_" permet de préciser à quel endroit couper le nom de la colonne.values_to = "valeur" indique que toutes les valeurs des colonnes d’origine sont regroupées dans une seule colonne appelée valeur`.
De cette façon, on obtient une structure très flexible adaptée aux graphiques ggplot2 (voir plus loin l’utilisation de facet_wrap())
Dans cette deuxième approche, on conserve une colonne par variable (Tension, Frequence) tout en créant une colonne Temps.
data_long_multi2 <- data_wide_multi |>
pivot_longer(
cols = -ID_Sujet,
names_to = c(".value", "Temps"),
names_sep = "_T"
)
# affichage du résultat
data_long_multi2
# A tibble: 8 × 4
ID_Sujet Temps Tension Frequence
<int> <chr> <dbl> <dbl>
1 1 0 120 70
2 1 3 115 68
3 2 0 130 75
4 2 3 128 73
5 3 0 110 68
6 3 3 108 65
7 4 0 140 80
8 4 3 135 78 Explications :
cols = -ID_Sujet signifie que l’on pivote toutes les colonnes sauf l’identifiant. names_sep = "_T" indique à quel endroit couper le nom des colonnes. Par exemple, “Tension_T0” est séparé en “Tension” et “0”.names_to = c(".value", "Temps") permet d’utiliser les deux parties du nom de colonne de la manière suivante :.value indique que la première partie du nom (Tension, Frequence) correspond aux noms des futures colonnes de valeursTemps crée une colonne contenant les moments de mesure (0, 3)On obtient alors une structure plus proche du format wide avec une colonne par variable (Tension, Frequence). Autrement dit, au lieu de créer une seule colonne de valeurs, on recrée plusieurs colonnes (Tension, Frequence), une par variable
data_wide_back1 <- data_long_multi1 |>
pivot_wider(
names_from = c(variable, Temps),
values_from = valeur,
names_sep = "_"
)
# affichage du résultat
data_wide_back1
# A tibble: 4 × 5
ID_Sujet Tension_T0 Tension_T3 Frequence_T0 Frequence_T3
<int> <dbl> <dbl> <dbl> <dbl>
1 1 120 115 70 68
2 2 130 128 75 73
3 3 110 108 68 65
4 4 140 135 80 78 L’argument names_from = c(variable, Temps) permet de combiner les deux colonnes pour recréer les noms de colonnes
data_wide_back2 <- data_long_multi2 |>
pivot_wider(
names_from = Temps,
values_from = c(Tension, Frequence),
names_sep = "_"
)
# affichage du résultat
data_wide_back2
# A tibble: 4 × 5
ID_Sujet Tension_0 Tension_3 Frequence_0 Frequence_3
<int> <dbl> <dbl> <dbl> <dbl>
1 1 120 115 70 68
2 2 130 128 75 73
3 3 110 108 68 65
4 4 140 135 80 78 Explications:
names_from = Temps permet que les temps deviennent des colonnes (T0, T3) values_from = c(Tension, Frequence) permet d’indiquer quelles colonnes contiennent les valeurs à répartir.Dans de nombreux jeux de données, certaines variables ne varient pas dans le temps.
Par exemple :
Ces informations restent identiques quelle que soit la mesure réalisée. Il est donc important de comprendre comment elles sont conservées lors du passage du format wide au format long, puis lors du retour au format wide.
Prenons l’exemple suivant :
# Création de data wide avec des co variables
data_wide_cov <- data.frame(
ID_Sujet = 1:4,
Sexe = c("F", "M", "F", "M"),
Age = c(65, 70, 58, 62),
Tension_T0 = c(120, 130, 110, 140),
Tension_T3 = c(115, 128, 108, 135)
)
# affichage des données
data_wide_cov
ID_Sujet Sexe Age Tension_T0 Tension_T3
1 1 F 65 120 115
2 2 M 70 130 128
3 3 F 58 110 108
4 4 M 62 140 135 Dans ce jeu de données :
chaque sujet est représenté sur une seule ligne :
data_long_cov <- data_wide_cov |>
pivot_longer(
cols = starts_with("Tension_"),
names_to = "Temps",
values_to = "Tension"
)
# affichage du résultat
data_long_cov
# A tibble: 8 × 5
ID_Sujet Sexe Age Temps Tension
<int> <chr> <dbl> <chr> <dbl>
1 1 F 65 Tension_T0 120
2 1 F 65 Tension_T3 115
3 2 M 70 Tension_T0 130
4 2 M 70 Tension_T3 128
5 3 F 58 Tension_T0 110
6 3 F 58 Tension_T3 108
7 4 M 62 Tension_T0 140
8 4 M 62 Tension_T3 135 Explications:
cols = starts_with("Tension_")indique que seules les colonnes commençant par “Tension_” doivent être pivotéesnames_to = "Temps"crée une colonne nommée Temps qui contient les anciens noms de colonnes (Tension_T0, Tension_T3)values_to = "Tension" crée une colonne Tension qui contient les valeurs correspondantes
Les autres colonnes, ici ID_Sujet, Sexe et Age, ne sont pas pivotées. Elles sont donc automatiquement conservées dans le résultat.
Remarque :
Dans l’argument cols, on peut soit sélectionner les colonnes à pivoter (par exemple celles qui commencent par “Tension_”), soit exclure les variables fixes comme l’identifiant, le sexe ou l’âge, comme ceci :
data_long_cov <- data_wide_cov |>
pivot_longer(
cols = -c(ID_Sujet, Sexe, Age),
names_to = "Temps",
values_to = "Tension"
)
data_long_cov
# A tibble: 8 × 5
ID_Sujet Sexe Age Temps Tension
<int> <chr> <dbl> <chr> <dbl>
1 1 F 65 Tension_T0 120
2 1 F 65 Tension_T3 115
3 2 M 70 Tension_T0 130
4 2 M 70 Tension_T3 128
5 3 F 58 Tension_T0 110
6 3 F 58 Tension_T3 108
7 4 M 62 Tension_T0 140
8 4 M 62 Tension_T3 135 En pratique, les deux méthodes sont équivalentes : on choisit généralement celle qui rend le code le plus clair en fonction du jeu de données.
pivot_wider() :data_wide_cov_new <- data_long_cov |>
pivot_wider(
names_from = Temps,
values_from = Tension
) En pratique, les variables qui ne varient pas dans le temps sont simplement répétées en format long, puis conservées lors du retour au format wide. Cela permet de garder un jeu de données complet et directement exploitable.
💡 Pour approfondir l’utilisation de pivot_longer() et pivot_wider(), vous pouvez consulter la vignette officielle du package {tidyr} en tapant la commande suivante dans la console :
vignette("pivot") Le format long est particulièrement adapté à l’utilisation des fonctions du package {dplyr}.
Dans l’exemple ci-dessous, j’utilise le format long pour créer facilement une table descriptive. En regroupant les données par la variable Temps (à. l’aide de la fonction group_by(), il est facile de calculer des statistiques descriptives telles que la moyenne, la médiane et l’écart-type de la tension artérielle pour chaque moment :
# affichage des 6 premières lignes du data long
head(data_long)
# A tibble: 6 × 3
ID_Sujet Temps Tension
<chr> <chr> <dbl>
1 SUBJ_001 Tension_T0 120
2 SUBJ_001 Tension_T3 115
3 SUBJ_001 Tension_T6 112
4 SUBJ_002 Tension_T0 130
5 SUBJ_002 Tension_T3 128
6 SUBJ_002 Tension_T6 125
library(dplyr)
# réalisation d'une table descriptive avec le package dplyr
data_long |>
group_by(Temps) |>
summarise(
Moyenne = mean(Tension),
Mediane = median(Tension),
EcartType = sd(Tension)
)
# A tibble: 3 × 4
Temps Moyenne Mediane EcartType
<chr> <dbl> <dbl> <dbl>
1 Tension_T0 125 125 12.9
2 Tension_T3 122. 122. 12.2
3 Tension_T6 118. 118. 12.2
Le format long est particulièrement adapté à la création de visualisations avec ggplot2, notamment pour les spaghetti plots, qui permettent de représenter les trajectoires individuelles au fil du temps.
En format long, chaque mesure de tension artérielle pour chaque sujet à chaque moment est représentée par une ligne distincte, avec Temps indiquant le moment de la mesure et Tension la valeur mesurée. Cela permet à ggplot2 de traiter et de visualiser facilement ces informations, car il peut utiliser la colonne Temps pour l’axe x et la colonne Tension pour l’axe y, tout en groupant les données par sujet pour tracer les lignes correspondantes. Cela n’aurait pas été possible de manière aussi simple et flexible avec des données en format wide.
library(ggplot2)
ggplot(data_long, aes(x = Temps, y = Tension, group = ID_Sujet, color = as.factor(ID_Sujet))) +
geom_line() +
geom_point() +
labs(title = "Changements de Tension Artérielle au Fil du Temps",
x = "Temps",
y = "Tension Artérielle",
color = "ID Sujet") +
theme_minimal() 
Explications :
aes(x = Temps, y = Tension, group = ID_Sujet, color = as.factor(ID_Sujet)) : Définit les axes x et y, groupe les lignes par sujet, et colore les lignes en fonction des sujets.geom_line() : Ajoute des lignes pour représenter les trajectoires individuelles.geom_point() : Ajoute des points pour chaque mesure individuelle.labs et theme_minimal() : Personnalise les labels et applique un thème minimaliste pour améliorer la lisibilité.Le format long permet également d’utiliser facilement la fonction facet_wrap() pour représenter plusieurs variables sur différents sous-graphiques.
Cela est particulièrement utile pour explorer et comparer des distributions de variables multiples. Voici un exemple utilisant les data
data_long_multi1:
# affichage des 6 premières ligne du dataset employé
head(data_long_multi1)
# A tibble: 6 × 4
ID_Sujet variable Temps valeur
<int> <chr> <chr> <dbl>
1 1 Tension T0 120
2 1 Tension T3 115
3 1 Frequence T0 70
4 1 Frequence T3 68
5 2 Tension T0 130
6 2 Tension T3 128
ggplot(data_long_multi1, aes(x = Temps, y = valeur, group = ID_Sujet, color = as.factor(ID_Sujet))) +
geom_line() +
geom_point() +
labs(title = "Changements de Tension Artérielle au Fil du Temps",
x = "Temps",
y = "Tension Artérielle",
color = "ID Sujet") +
facet_wrap(~variable,scales = "free_y" )+
theme_minimal() 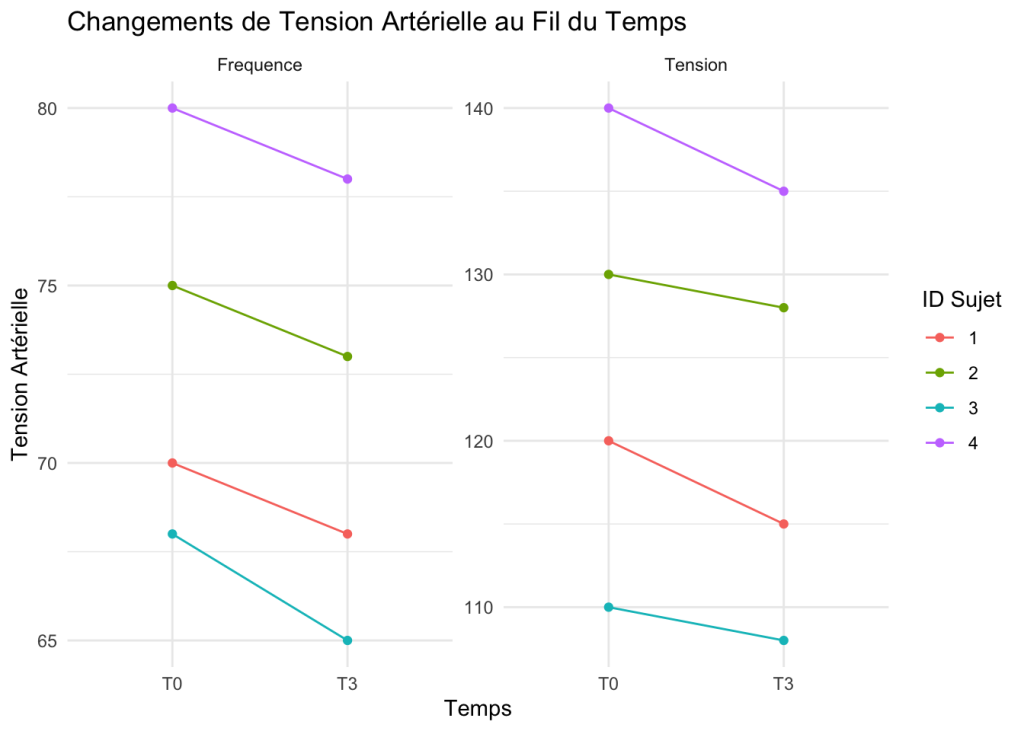
La fonction facet_wrap(~Variable, scales = "free_y") crée des sous-graphiques pour chaque variable Ffréquence et Tension). Les échelles de l’axe des y sont indépendantes pour chaque sous-graphe grâce à l’argument scales = "free_y"
Par exemple, le format long, est nécessaire pour pouvoir réaliser une ANOVA sur mesure répétées avec la fonction aov(). Voici un exemple avec nos données médicales :
# affichage des 6 premières lignes du data_long
head(data_long)
# A tibble: 6 × 3
ID_Sujet Temps Tension
<chr> <chr> <dbl>
1 SUBJ_001 Tension_T0 120
2 SUBJ_001 Tension_T3 115
3 SUBJ_001 Tension_T6 112
4 SUBJ_002 Tension_T0 130
5 SUBJ_002 Tension_T3 128
6 SUBJ_002 Tension_T6 125
# réalisation de l'anova sur mesures répétées
anova_result <- aov(Tension ~ Temps + Error(ID_Sujet/Temps), data = data_long)
summary(anova_result)
Error: ID_Sujet
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 3 1392 464
Error: ID_Sujet:Temps
Df Sum Sq Mean Sq F value Pr(>F)
Temps 2 84.67 42.33 42.33 0.00029 ***
Residuals 6 6.00 1.00
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Ici, le format long est indispensable pour la ligne de commande aov(Tension ~ Temps + Error(ID_Sujet/Temps), data = data_long) car il permet de structurer les données de manière à ce que les dépendances entre les mesures répétées soient explicitement représentées. Cela permet de spécifier correctement le modèle statistique et de tenir compte des variations entre et au sein des sujets, ce qui est essentiel pour une ANOVA à mesures répétées.
Pour que pivot_longer()fonctionne correctement, il est essentiel que les noms de colonnes suivent une structure cohérente.
Prenons un exemple problématique :
# création d'un datatset avec des noms de variables non homogènes
data_bad <- data.frame(
ID_Sujet = 1:3,
T0 = c(120, 130, 110),
Temps3 = c(115, 128, 108),
Time_6 = c(112, 125, 105)
)
# affichage des données
data_bad
ID_Sujet T0 Temps3 Time_6
1 1 120 115 112
2 2 130 128 125
3 3 110 108 105 Ici les noms de variables ne sont pas homogènes : T0 ,Temps3 ,Time_6.
Si on essaie de pivoter :
# passage en format long
data_bad_long <- data_bad |>
pivot_longer(
cols = -ID_Sujet,
names_to = "Temps",
values_to = "Tension"
)
# affichage du résultat
data_bad_long
# A tibble: 9 × 3
ID_Sujet Temps Tension
<int> <chr> <dbl>
1 1 T0 120
2 1 Temps3 115
3 1 Time_6 112
4 2 T0 130
5 2 Temps3 128
6 2 Time_6 125
7 3 T0 110
8 3 Temps3 108
9 3 Time_6 105
Le code fonctionne… mais le résultat risque d’être ensuite difficile à exploiter (tri, ordre, graph, analyse) car la colonne Temps contient des valeurs hétérogènes (T0, Temps3, Time_6).
Si vos colonnes ne suivent pas un format clair comme ici (T0, Temps3, Time_6), alors l’argument names_sep ne fonctionnera pas, et le résultat ne sera pas du tout exploitable :
# passage en ormat long avec emploi de l'argument names_sep
data_bad_long2 <- data_bad |>
pivot_longer(
cols = -ID_Sujet,
names_to = c("variable", "Temps"),
names_sep = "_"
)
Warning: Expected 2 pieces. Missing pieces filled with `NA` in 2 rows [1, 2].
data_bad_long2
# A tibble: 9 × 4
ID_Sujet variable Temps value
<int> <chr> <chr> <dbl>
1 1 T0 <NA> 120
2 1 Temps3 <NA> 115
3 1 Time 6 112
4 2 T0 <NA> 130
5 2 Temps3 <NA> 128
6 2 Time 6 125
7 3 T0 <NA> 110
8 3 Temps3 <NA> 108
9 3 Time 6 105 On observe ici que R affiche un message d’avertissement (warning), car les variables T0 et Temps3 ne contiennent pas de caractère de séparation _ . R ne peut donc pas découper correctement les noms, ce qui entraîne l’apparition de valeurs manquantes (NA).
À retenir :
La qualité du pivot dépend directement de la qualité des noms de colonnes.
Avant d’utiliser pivot_longer(), prenez toujours quelques secondes pour vérifier (ou nettoyer) vos noms de variables.
Beaucoup de problèmes viennent simplement d’un mauvais choix de structure.
Avant de coder, posez-vous la question du format.
Imaginons que vous souhaitiez calculer la moyenne de la tension à chaque temps.
Avec le format wide :
# affichage des 6 premières lignes du frmat wide
head(data_wide)
ID_Sujet Tension_T0 Tension_T3 Tension_T6
1 SUBJ_001 120 115 112
2 SUBJ_002 130 128 125
3 SUBJ_003 110 108 105
4 SUBJ_004 140 135 132
# calcul de la moyenne à chaque temps, à partir du format wide
data_wide |>
summarise(
across(
starts_with("Tension_"),
mean
)
)
# resultat
Tension_T0 Tension_T3 Tension_T6
1 125 121.5 118.5 Ce code fonctionne, mais il donne un résultat encore en format large.
Si l’on veut ensuite obtenir un tableau plus propre, avec une colonne pour le temps et une autre pour la moyenne, il faut ajouter une étape supplémentaire :
data_wide |>
summarise(
across(
starts_with("Tension_"),
mean
)
) |>
pivot_longer(
cols = everything(),
names_to = "Temps",
values_to = "Moyenne"
)
# A tibble: 3 × 2
Temps Moyenne
<chr> <dbl>
1 Tension_T0 125
2 Tension_T3 122.
3 Tension_T6 118.
data_long |>
group_by(Temps) |>
summarise(
Moyenne = mean(Tension)
)
# A tibble: 3 × 2
Temps Moyenne
<chr> <dbl>
1 Tension_T0 125
2 Tension_T3 122.
3 Tension_T6 118. Ici, le code est souvent plus naturel, surtout si vous souhaitez ensuite :
Si votre code devient compliqué, répétitif ou difficile à adapter, le problème ne vient pas toujours de R : il vient souvent du format de vos données.
👉 Avant de coder, posez-vous donc cette question : mes données sont-elles dans le bon format pour ce que je veux faire ?
Savoir passer du format wide au format long est une compétence essentielle en R… mais ce n’est qu’une étape.
La documentation officielle est une excellente ressource pour comprendre les fonctions, mais elle ne suffit pas toujours à structurer un flux de travail complet.
Dans la pratique, les difficultés ne viennent pas seulement des fonctions elles-mêmes, mais de l’enchaînement des étapes : importer les données, les nettoyer, les transformer, puis les analyser de manière cohérente et reproductible.
Dans mes formations professionnelles, je vous montre comment construire ce type de workflow de bout en bout, avec des cas concrets inspirés de données réelles.
Formations
Le format de vos données a un impact direct sur la simplicité de vos analyses.
Maîtriser pivot_longer() et pivot_wider() vous permet d’éviter de nombreux blocages et de travailler beaucoup plus efficacement sous R.
N’hésitez pas à laisser un commentaire ci-dessous pour partager vos expériences, poser des questions ou proposer des améliorations. Vos commentaires sont précieux et m’aident à améliorer continuellement mes articles et tutoriels pour mieux répondre à vos besoins.

CAMPUS DELLADATA
Je propose désormais une formation en ligne pour démarrer avec R et RStudio, pensée pour les profils scientifiques (recherche médicale, biologie, agro, environnement…). D’autres modules arrivent prochainement.

Je suis Claire Della-Vedova, consultante en biostatistique, méthodologie clinique et expertise R.
J’accompagne les fabricants de dispositifs médicaux et les équipes scientifiques des sciences du vivant dans leurs projets d’évaluation clinique, d’analyse statistique et d’analyse de données sous R.
🎓 Formations professionnelles R et biostatistiques
🤝 Prestations et accompagnement sur mesure
📅 Discuter d’un accompagnement ou d’une prestation sur mesure

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
14 réponses
Merci beaucoup
Ce blog vient à point nommé.
Merci pour le partage .
Très intéressant et je dirai même wahooooo
Cordialement
Merci beaucoup Claire ! 😊
C’est un récapitulatif très précis que je n’aurais pas aussi bien formulé alors que j’utilise souvent ces 2 super fonctions (pas faciles à expliquer aux autres 😬).
Alors que je fais l’essentiel de mes calculs et valorisations avec le format LONG, WIDE est utile pour préparer les calculs tels ACP (notamment pour une entrée dans l’outil factoMineR).
Bonjour Sonia,
L’ACP est un très bon exemple du format wide, je n’y avais pas pensé. Merci !
Magnifique. Ceci renforce mes compétences.
bonjour
Les fonctions pivots ne fonctionnent pas avec les données sous format texte.
j’ai eu un problème pour élargir un tableau d’adresses
je m’en suis sorti avec une boucle for et je me demandais s’il n’existait pas une jolie fonction qui fera le travail en 2 lignes plutôt qu’en 20…
bonne journée
laurent
Bonjour Laurent,
est-ce que vous pouvez, s’il vous plait, réaliser un petit exemple pour que je comprenne bien ?
J’essaierai de vous apporter une réponse.
Merci pour cet article !
Je ne connaissais pas cette fonctionnalité.
Grâce à votre article, fini le temps perdu à trouver des voies tortueuses pour produire certains graphiques.
Excellente initiative qui me convainc de remplacer les « spread » et autre « gather » pas aussi explicites et moins riches que ces « pivot… »
Bonjour Gilles,
oui effectivement les fonctions ont changé et se sont bien simplifiées.
Merci pour ce document édifiant.
C’est génial !
Merci pour ce document.
Merci Claire : présentation oh combien utile et très pédagogique.