La semaine dernière, j’ai vu cet extrait d’une émission de télé dans laquelle Catherine Hill expliquait à des journalistes que pour évaluer la tendance de l’évolution du nombre de nouveaux cas de covid par jour, on ne pouvait pas représenter les oscillations quotidiennes pour faire ensuite simplement la différence entre un pic et un creux, mais qu’il fallait montrer les moyennes glissantes sur 7 jours (ou moyennes mobiles).
Comme les moyennes glissantes ne me sont pas très familières, l’intervention de Catherine Hill m’a vraiment donné envie de me repencher sur l’analyse des séries temporelles (auxquelles se rattachent les moyennes glissantes).
Je dois dire que c’est un sujet sur lequel j’ai toujours plutôt buté dans le passé. Sans doute, un peu parce que je n’avais pas trouvé une ressource qui m’accrochait, et un peu aussi parce que je n’ai jamais vraiment eu l’opportunité de travailler ce sujet en profondeur.
Depuis deux ou trois ans, j’entends parler très positivement du livre d’Hyndman et Athanasopoulos “Forecasting : principles and practice”. Il est gratuitement consultable à cette adresse : https://otexts.com/fpp2/. J’ai donc décidé de le commencer !
Dans ce premier article dédié aux séries temporelles, je vous propose un simple résumé de ce que j’ai appris et compris des premiers chapitres (je n’ai pas encore atteint les moyennes mobiles !), suivi d’une mise en pratique avec des données réelles issues de la base de données françaises relatives au COVID.
Si vous êtes très à l’aise avec les séries temporelles, et que vous relevez une erreur, s’il vous plaît, indiquez la moi en commentaire, et je la corrigerais !
Une série temporelle, ou série chronologique, est une suite de valeurs numériques représentant l’évolution d’une quantité spécifique au cours du temps. (Wikipedia) :
Soient t1, t2…tn les temps successifs des observations, et yt1, yt2….ytn les observations. yti est alors l’observation réalisée au temps ti. La série temporelle peut se noter :\[\left\{y_{t}\right\}_{t \in T}\]
Où T est l’ensemble des temps ordonnés :
\[T=\left\{t_{1}, t_{2}, \ldots, t_{n}\right\}\]
Voici un exemple de séries temporelles. Il s’agit de la série temporelle AirPassengers, présente dans le package dataset chargé par défaut dans R :

Si nous étudions la structure de ces données AirPassengers, nous pouvons voir qu’elles sont de type Times-Series. Elles contiennent 144 éléments entre 1949 et 1961; il s’agit donc d’une série à pas de temps mensuel.
str(AirPassengers)
## Time-Series [1:144] from 1949 to 1961: 112 118 132 129 121 135 148 148 136 119 ...
Les séries temporelles sont caractérisées par une auto-corrélation des observations. Cela signifie que la mesure au temps t n’est pas indépendante de celle à t-1 ; elle lui ressemble un peu. Par exemple le nombre de passagers aériens observés au mois d’aout, n’est pas totalement indépendant du nombre de passagers au mois de juillet.
On mesure cette ressemblance, ou ce lien, par un coefficient de corrélation.
En pratique, on calcule ce coefficient de corrélations pour tous les écarts de temps k (qu’on appelle aussi des lags) ; par exemple entre yt et yt-1 (lag1), puis entre yt et yt-2 (lag2) etc…
\[ r_{k}=\frac{\sum_{t=k+1}^{T}\left(y_{t}-\bar{y}\right)\left(y_{t-k}-\bar{y}\right)}{\sum_{t=1}^{T}\left(y_{t}-\bar{y}\right)^{2}}\]
On peut ensuite représenter graphiquement ces coefficients de corrélations sur un corrélogramme qui permet de visualiser la fonction d’auto-corrélation (ACF).

Les lignes bleues en pointillés indiquent si les corrélations sont significativement différentes de zéro.
Une série temporelle comporte trois composantes principales
Remarque : il existe aussi parfois une composante cyclique, c’est lorsqu’il y a des pics et des creux mais qui ne se répètent pas avec une fréquence fixe.
Pour mieux comprendre, voici une décomposition de la série temporelle du nombre de voyageurs aériens mensuels :
Visualisation des 3 composantes :

Les séries temporelles offrent deux intérêts principaux :
La description est généralement réalisée à l’aide d’un graphique
Pour ce qui est des prévisions, il existe de nombreuses approches. Il y a des méthodes toutes simples (et sans doute pas top en termes de performance – mais qui ont le mérite d’être bien compréhensibles, et c’est déjà un premier pas). Je pense aux prévisions par moyennes, et aux prévisions naïves ; nous allons les essayer plus loin dans cet article.
Je sais qu’il existe des approches un peu plus complexes mais plutôt abordables : je pense aux fameuses moyennes glissantes, mais aussi aux méthodes de lissage exponentielles (que j’ai déjà croisé).
Et puis il y a les modèles ARIMA, SARIMA que je n’ai jamais parfaitement compris.
Et puis il y a encore des méthodes dont je n’ai jamais entendu parler (mais qui sont présentées dans le livre), comme les modèles de régression dynamique et autres.
Les prévisions sont notées avec un chapeau, pour les distinguer des observations (sans chapeau) :
\[\hat{y}_{T+h \mid T}\]
Ce terme signifie la prévision de y (l’observation) à T + h (h est l’horizon, 12 mois par exemple), compte tenu des observations passées pour l’ensemble des temps T.
Dans cette approche, les prévisions de toutes les valeurs futures sont égales à la moyenne des données passées :
\[\hat{y}_{T+h \mid T}=\bar{y}=\left(y_{1}+\cdots+y_{T}\right) / T\]
Nous pouvons obtenir ces prévisions avec la fonction meanf(), du package forecast.
# moyenne de l'ensemble des données
meanf(AirPassengers,12)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## Jan 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Feb 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Mar 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Apr 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## May 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Jun 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Jul 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Aug 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Sep 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Oct 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Nov 1961 280.2986 125.3066 435.2906 42.34016 518.2571
## Dec 1961 280.2986 125.3066 435.2906 42.34016 518.2571 L’argument `12` correspond à l’horizon souhaité : 12 mois.
Ici, les prévisions de toutes les valeurs futures sont égales à la valeur de la dernière observation :
\[\hat{y}_{T+h \mid T}=y_{T}\]
La fonction à employer est naive():
naive(AirPassengers,12)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## Jan 1961 432 388.7984 475.2016 365.9288 498.0712
## Feb 1961 432 370.9037 493.0963 338.5612 525.4388
## Mar 1961 432 357.1726 506.8274 317.5613 546.4387
## Apr 1961 432 345.5967 518.4033 299.8576 564.1424
## May 1961 432 335.3982 528.6018 284.2603 579.7397
## Jun 1961 432 326.1781 537.8219 270.1593 593.8407
## Jul 1961 432 317.6992 546.3008 257.1921 606.8079
## Aug 1961 432 309.8073 554.1927 245.1225 618.8775
## Sep 1961 432 302.3951 561.6049 233.7864 630.2136
## Oct 1961 432 295.3845 568.6155 223.0646 640.9354
## Nov 1961 432 288.7164 575.2836 212.8667 651.1333
## Dec 1961 432 282.3452 581.6548 203.1227 660.8773 Avec cette approche, chaque prévision est égale à la dernière valeur observée de la même saison (par exemple, le même mois de l’année précédente).
\[\hat{y}_{T+h \mid T}=y_{T+h-m(k+1)}\]
La formule est peu complexe, mais elle signifie simplement que la prévision du nombre de passagers pour juillet 1961 sera la valeur observée en juillet 1960. La fonction employée est snaive()
snaive(AirPassengers,12)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## Jan 1961 417 370.4595 463.5405 345.8224 488.1776
## Feb 1961 391 344.4595 437.5405 319.8224 462.1776
## Mar 1961 419 372.4595 465.5405 347.8224 490.1776
## Apr 1961 461 414.4595 507.5405 389.8224 532.1776
## May 1961 472 425.4595 518.5405 400.8224 543.1776
## Jun 1961 535 488.4595 581.5405 463.8224 606.1776
## Jul 1961 622 575.4595 668.5405 550.8224 693.1776
## Aug 1961 606 559.4595 652.5405 534.8224 677.1776
## Sep 1961 508 461.4595 554.5405 436.8224 579.1776
## Oct 1961 461 414.4595 507.5405 389.8224 532.1776
## Nov 1961 390 343.4595 436.5405 318.8224 461.1776
## Dec 1961 432 385.4595 478.5405 360.8224 503.1776 Il s’agit d’une variante de l’approche naïve qui permet aux prévisions de varier (en croissant au décroissant) au cours du temps. Cette quantité de changement des prévisions au cours du temps est appelée la dérive (drift en anglais), elle est estimée par l’évolution moyenne observée sur les données passées :
\[\hat{y}_{T+h \mid T}=y_{T}+\frac{h}{T-1} \sum_{t=2}^{T}\left(y_{t}-y_{t-1}\right)\]
rwf(AirPassengers,12, drift=TRUE)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## Jan 1961 434.2378 390.9799 477.4956 368.0806 500.3949
## Feb 1961 436.4755 375.0862 497.8649 342.5886 530.3625
## Mar 1961 438.7133 363.2664 514.1602 323.3272 554.0994
## Apr 1961 440.9510 353.5325 528.3696 307.2560 574.6461
## May 1961 443.1888 345.1178 541.2598 293.2022 593.1755
## Jun 1961 445.4266 337.6304 553.2228 280.5665 610.2866
## Jul 1961 447.6643 330.8384 564.4902 268.9946 626.3341
## Aug 1961 449.9021 324.5916 575.2126 258.2562 641.5480
## Sep 1961 452.1399 318.7857 585.4940 248.1922 656.0875
## Oct 1961 454.3776 313.3453 595.4100 238.6873 670.0680
## Nov 1961 456.6154 308.2136 605.0171 229.6545 683.5763
## Dec 1961 458.8531 303.3469 614.3594 221.0268 696.6795 autoplot(AirPassengers) +
autolayer(meanf(AirPassengers, h=12), series="Moyenne", PI=FALSE) +
autolayer(naive(AirPassengers, h=12), series="Naïve", PI=FALSE) +
autolayer(snaive(AirPassengers , h=12), series="Naïve saisonnière", PI=FALSE) +
autolayer(rwf(AirPassengers,12, drift=TRUE), series="Naïve dérive", PI=FALSE)+
ggtitle("Prevision du nombre de passagers mensuels pour l'année 1961") +
xlab("Year") +
ylab("Nombres de passagers") +
guides(colour=guide_legend(title="Prevision")) 
On peut voir qu’aucune de ces approches simples n’est satisfaisante. Ce n’est pas très étonnantes, ce sont des méthodes « simples ». Mais je pense que c’est une bonne base pour comprendre la problématique de la prévision des séries temporelles, et ensuite pouvoir comprendre les approches de prévisions plus complexes.
Pour évaluer si un modèle de prévision est bien adapté aux données, c’est-à-dire qu’il a su capturer l’ensemble de l’information passée de la série temporelle (c’est clairement pas le cas des méthodes simples employées précédemment), un diagnostic doit être réalisé sur les résidus (la différence entre les prévisions et la réalité):
\[e_{t}=y_{t}-\hat{y}_{t}\]
Les résidus doivent satisfaire 4 conditions :
Les 3 dernières conditions sont identiques à celle de l’utilisation des modèles linéaires.
Ensuite, les performances de plusieurs modèles de prévisions peuvent être évaluées et comparées à l’aide de différents paramètres tels que :
\[{MAE}=\text{mean}\left(\left|e_{t}\right|\right)\]
\[RMSE=\sqrt{mean(e^2_t)}\]
Pour l’instant, je ne me suis pas trop penchée sur les diagnostics et les paramètres de performance. Ça sera pour un prochain article…
J’ai voulu essayer de manipuler ces notions et ces fonctions sur une série temporelle qui n’existe pas par défaut dans R. Je voulais me confronter à d’éventuels problèmes de structures, et de conversion des données en type « time series ».
Comme l’inspiration de tout cela c’était des données COVID, je me suis décidée à les télécharger ( ce que j’avais rigoureusement évité de faire jusque là !)
Et j’ai choisi de travailler sur le nombre d’hospitalisations dans mon département, c’est-à-dire le 04 : les Alpes de Haute Provence.
Pour cela, j’ai chargé le package covid19france et fais quelques manipulations :
install.packages("covid19france")
library(covid19france)
# mise à jour des données
france <- refresh_covid19france()
france$data_type <- as.factor(france$data_type)
library(tidyverse)
ahp_hosp <- france %>%
filter(location_standardized=="DEP-04") %>%
filter(data_type=="hospitalized")
head(ahp_hosp)
A tibble: 6 x 7
date location location_type location_standard~ location_standardi~ data_type value
<date> <chr> <chr> <chr> <chr> <fct> <int>
2 2021-02-11 Alpes-de-Hau~ county DEP-04 department hospital~ 188
3 2021-02-10 Alpes-de-Hau~ county DEP-04 department hospital~ 188
4 2021-02-09 Alpes-de-Hau~ county DEP-04 department hospital~ 192
5 2021-02-08 Alpes-de-Hau~ county DEP-04 department hospital~ 190
6 2021-02-07 Alpes-de-Hau~ county DEP-04 department hospital~ 182 J’ai commencé par essayer de faire des visualisations, uniquement avec ggplot2 (sans fonctions spécifiques dédiées aux séries temporelles) :
ggplot(ahp_hosp, aes(x=date,y=value))+
geom_line()+
geom_point() 
J’ai amélioré les étiquettes de temps :

Pour plus de détails sur la modification des étiquettes, consultez l’article : Comment représenter une série temporelle avec ggplot2?
Ensuite, j’ai restreint les données à partir du 1er septembre, pour zoomer sur les données plus récentes.
ahp_hosp %>%
filter(date>"2020-09-01") %>%
ggplot(aes(x=date,y=value))+
geom_line()+
geom_point()+
scale_x_date(breaks=datebreaks)+
theme(axis.text.x = element_text(angle=30, hjust=1)) 
Puisque dans l’extrait vidéo, Catherine Hill disait que le nombre de cas rapportés dépend du jour de la semaine, j’ai voulu voir si c’est le cas sur ces données. Pour cela, j’ai créé une variable js pour `jour semaine` :
library(stringr)
library(lubridate)
ahp_hosp <- ahp_hosp %>%
mutate(
js=wday(date, label=TRUE, abb=TRUE),
js=as.character(js),
js=str_sub(js,1,3))
head(ahp_hosp)
# A tibble: 6 x 8
date location location_type location_standar~ location_standar~ data_type value js
<date> <chr> <chr> <chr> <chr> <fct> <int> <chr>
2 2021-02-11 Alpes-de-~ county DEP-04 department hospital~ 188 jeu
3 2021-02-10 Alpes-de-~ county DEP-04 department hospital~ 188 mer
4 2021-02-09 Alpes-de-~ county DEP-04 department hospital~ 192 mar
5 2021-02-08 Alpes-de-~ county DEP-04 department hospital~ 190 lun
6 2021-02-07 Alpes-de-~ county DEP-04 department hospital~ 182 dim
> ahp_hosp %>%
filter(date>"2020-09-01") %>%
ggplot(aes(x=date,y=value))+
geom_line()+
geom_point()+
scale_x_date(breaks=datebreaks,labels=date_format("%d %b %y"))
theme(axis.text.x = element_text(angle=30, hjust=1)) +
facet_wrap(~js) 
Ou encore, toutes les courbes ensemble :
ahp_hosp %>%
filter(date>"2020-09-01") %>%
ggplot(aes(x=date,y=value, group=js, colour=js))+
geom_line()+
geom_point()+
scale_x_date(breaks=datebreaks,labels=date_format("%d %b %y"))+
theme(axis.text.x = element_text(angle=30, hjust=1)) 
Le nombre de patients hospitalisés ne me semble pas dépendre d’un jour de la semaine.
Ensuite, pour utiliser les fonctions du package forcast, à la fois pour représenter les données et faire des prévisions, il a fallu que je les convertisse en format time series. Cela se fait avec la fonction ts().
Lorsqu’on télécharge les données, elles sont triées de la plus récente à la plus ancienne. Or, lorsqu’elles sont en format time series elles doivent être ordonnées dans l’autre sens : de la plus ancienne à la plus récente. Je les ai donc réordonné avant de les passer en time series.
# changer l'ordre du dataset par ordre chronologique (en haut les anciennes en bas les récentes)
ahp_hosp_ts <- ahp_hosp %>%
arrange(date) %>%
filter(date>"2020-09-01") %>%
select(value) %>%
ts(frequency=7)
str(ahp_hosp_ts)
View(ahp_hosp_ts) Le package forecast dispose de fonctions de visualisation, telles que autplot() , seasonplot(), et ggsubseriesplot():
library(forecast)
autoplot(ahp_hosp_ts)+
ylab("Effectif") +
ggtitle("Nombre de sujets hospitalisés \ndepuis le 1er septembre 2020") 
A présent l’axe des x correspond à un numéro de semaine à partir de la date du « 2020-09-01 ».
La fonction ggseasonplot() permet d’explorer un potentiel effet saison. Ici, il s’agit des jours à l’intérieur des semaines. Dans le jeu de données AirPassengers ça serait les mois à l’intérieur des années).
ggseasonplot(ahp_hosp_ts, season.labels="week") +
ylab("Effectif") +
ggtitle("Seasonal plot: nombre de sujets hospitalisés") 
Ici, il n’y a pas de saisonnalité, car on ne voit pas un pic ou un creux spécifique à un jour de la semaine.
On peut aussi faire un season plot circulaire, grâce à l’argument `polar=TRUE` :
ggseasonplot(ahp_hosp_ts, polar=TRUE) +
ylab("effectif") +
ggtitle("Seasonal plot: nombre de sujets hospitalisés") 
C’est assez joli pour visualiser l’évolution du nombre de patients hospitalisés depuis le premier septembre, mais en termes de saisonnalité comme il n’y en a pas, c’est difficile de se rendre compte de l’intérêt. Du coup, j’ai essayé avec les données `AirPassengers`, et effectivement, on visualise bien le creux de passagers les moins d’hiver et le pic les mois d’été :

On peut également représenter la série temporelle par jour avec les graphs cote à cote, en employant la fonction ggsubseriesplot:
ggsubseriesplot(ahp_hosp_ts) +
ylab("effectif") +
ggtitle("Seasonal subseries plot: nombre de sujets hospitalisés") 
Ce graph est équivalent à celui que j’ai fait précédemment avec ggplot2 , en distinguant les jours de la semaine (voir plus haut).
# approche moyenne
meanf(ahp_hosp_ts,7)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## 24.28571 91.39264 8.721233 174.064 -35.4745 218.2598
## 24.42857 91.39264 8.721233 174.064 -35.4745 218.2598
## 24.57143 91.39264 8.721233 174.064 -35.4745 218.2598
## 24.71429 91.39264 8.721233 174.064 -35.4745 218.2598
## 24.85714 91.39264 8.721233 174.064 -35.4745 218.2598
## 25.00000 91.39264 8.721233 174.064 -35.4745 218.2598
## 25.14286 91.39264 8.721233 174.064 -35.4745 218.2598 # approche naive
naive(ahp_hosp_ts,7)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## 24.28571 188 182.3015 193.6985 179.2850 196.7150
## 24.42857 188 179.9412 196.0588 175.6751 200.3249
## 24.57143 188 178.1300 197.8700 172.9051 203.0949
## 24.71429 188 176.6031 199.3969 170.5699 205.4301
## 24.85714 188 175.2579 200.7421 168.5126 207.4874
## 25.00000 188 174.0417 201.9583 166.6526 209.3474
## 25.14286 188 172.9233 203.0767 164.9422 211.0578 # approche naive saisonnière
snaive(ahp_hosp_ts,7)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## 24.28571 173 151.7216 194.2784 140.4575 205.5425
## 24.42857 182 160.7216 203.2784 149.4575 214.5425
## 24.57143 182 160.7216 203.2784 149.4575 214.5425
## 24.71429 190 168.7216 211.2784 157.4575 222.5425
## 24.85714 192 170.7216 213.2784 159.4575 224.5425
## 25.00000 188 166.7216 209.2784 155.4575 220.5425
## 25.14286 188 166.7216 209.2784 155.4575 220.5425 # approche naive saisonnière avec dérive
rwf(ahp_hosp_ts,7, drift=TRUE)
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## 24.28571 189.1049 183.5681 194.6418 180.6371 197.5728
## 24.42857 190.2099 182.3555 198.0643 178.1976 202.2221
## 24.57143 191.3148 181.6657 200.9639 176.5578 206.0718
## 24.71429 192.4198 181.2440 203.5955 175.3280 209.5115
## 24.85714 193.5247 180.9921 206.0573 174.3577 212.6917
## 25.00000 194.6296 180.8595 208.3997 173.5701 215.6892
## 25.14286 195.7346 180.8167 210.6524 172.9196 218.5495 Visualisons des différentes prédictions :
autoplot(ahp_hosp_ts) +
autolayer(meanf(ahp_hosp_ts, h=7), series="Moyenne", PI=FALSE) +
autolayer(naive(ahp_hosp_ts, h=7), series="Naïve", PI=FALSE) +
autolayer(snaive(ahp_hosp_ts , h=7), series="Naïve saisonnière", PI=FALSE) +
autolayer(rwf(ahp_hosp_ts,7, drift=TRUE), series="Naïve dérive", PI=FALSE)+
ggtitle("Prevision du nombre patients hiospitalisés à l'horizon une semaine") +
xlab("semaine") +
ylab("Nombre de patients hospitalisés") +
guides(colour=guide_legend(title="Prevision")) 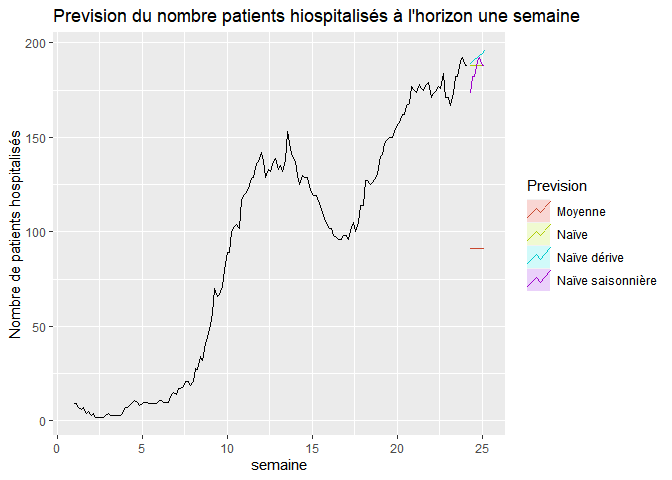
Il ne restera plus qu’à comparer les prévisions avec les observations de la semaine prochaine !
J’apprécie beaucoup l’ouvrage d’ Hyndman et Athanasopoulos “Forecasting : principles and practice”. C’est une ressource très pédagogique, et très agréable à lire, avec des exemples concrets, qui va à l’essentiel, sans nous bombarder de notions théoriques difficiles à appréhender.
Si le sujet des séries temporelles vous intéresse, quel que soit votre domaine d’application (santé, tourismes, marketing, etc…), je pense que c’est vraiment l’ouvrage avec lequel commencer pour acquérir de bonnes bases.
J’ai vraiment envie de poursuivre sa lecture.
N’hésitez pas à me dire ce que vous en pensez en commentaire.
D’ici là, cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don libre sur sa page Tipeee.

Et si vous voulez vous procurer une copie papier du livre livre d’Hyndman et Athanasopoulos “Forecasting : principles and practice », vous pouvez cliquer sur l’image ci-dessous :


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
6 réponses
Bonjour Claire,
je passais par là,
j’ai vu que tu ne comprenais pas les modeles ARIMA en série temporelle,
va voir le livre introduction aux séries Temporelle R. Bourbonnais et M. Terrazza
Niveau L1 et M1 econométrie
rien de tres difficille
Sinon regarde les Bouquins de Alain Montfort
http://www.crest.fr/pagesperso.php?user=3014
Merci POUR LES ROUTINES SOUS R
Bonjour Olivier,
merci pour ces recommandations, je viens d’acheter le livre de M.Terrazza !
datebreaks ?????
Merci pour ce blog.
J’ai juste une question qui n’a pas lien avec ce cours.. Je veux que vous me conseillez un document pour faire l’analyse textuelle avec R
Merci bien
Bonjour,
je vous conseille l’ouvrage « Tex mining with R, consultable en ligne : https://www.tidytextmining.com/
Sinon, en français, je connais le livre « analyse textuelle avec R », mais je ne l’ai pas lu :
https://www.amazon.fr/s?k=analyse+textuelle+avec+R&__mk_fr_FR=%C3%85M%C3%85%C5%BD%C3%95%C3%91&crid=WGB28P8BVJVT&sprefix=analyses+text%2Caps%2C168&ref=nb_sb_noss
J’espère que cela vous aide.
Bonne continuation.
Bonjour Claire,
Merci pour ce blog qui est vraiment enrichissant. Je rebondis sur la très courte question de alahiane : Est-ce que tu crois qu’il serait possible de mettre à jour cette page « Introduction aux séries temporelles » du blog avec l’illustration de ton code pour la partie « J’ai amélioré les étiquettes de temps : » ? (au niveau du cas pratique sur les hospitalisations Covid19 en 2020/2021)
Vu ton graphique après amélioration ici (une marque sur l’axe x par mois) et tes explications sur datebreaks sur la page « Comment représenter une série temporelle avec ggplot2 » : datebreaks <- seq(as.Date("2015-08-01"), as.Date("2015-11-19"), by="1 week"). J'imagine qu'ici tu as fait quelque chose du style : datebreaks <- seq(as.Date("…"), as.Date("…"), by="1 month") ?
Si cela peut marcher d'affiner l'échelle de temps à partir d'un fichier en horodate comme un que tu présentes sur le blog (AtchisonUV_20150801_to_20151119.csv) et pour tirer profit de la partie hh:mm:ss de l'horodate, que mettrais-tu dans l'argument by pour découper l'axe des x en heure ? quart d'heure ? minute ?
Merci à toi
P.S. : cela correspond à quoi quand tu mets '%%' en fin de commande s'il te plaît ?