Dans cet article, je vais essayer de répondre à une question que l’on me pose souvent : comment représenter graphiquement une série temporelle avec le package ggplot2 ?
C’est vrai que cela n’est pas évident, car il y a trois difficultés à dépasser pour représenter une série temporelle :
Pour illustrer la représentation graphiques d’une série temporelle avec le package ggplot2, nous allons employer le jeu de données AtchisonUV_20150801_to_20151119.csv. Il s’agit de données de pollution entre le 01/08/2015 et le 19/11/2015 dans la ville Atchison aux Etats-Unis (Californie). Ce jeu de données est disponible à cette adresse : https://www.kaggle.com/nicapotato/ pollution-in-atchison-village-richmond-ca.
En voici un extrait :
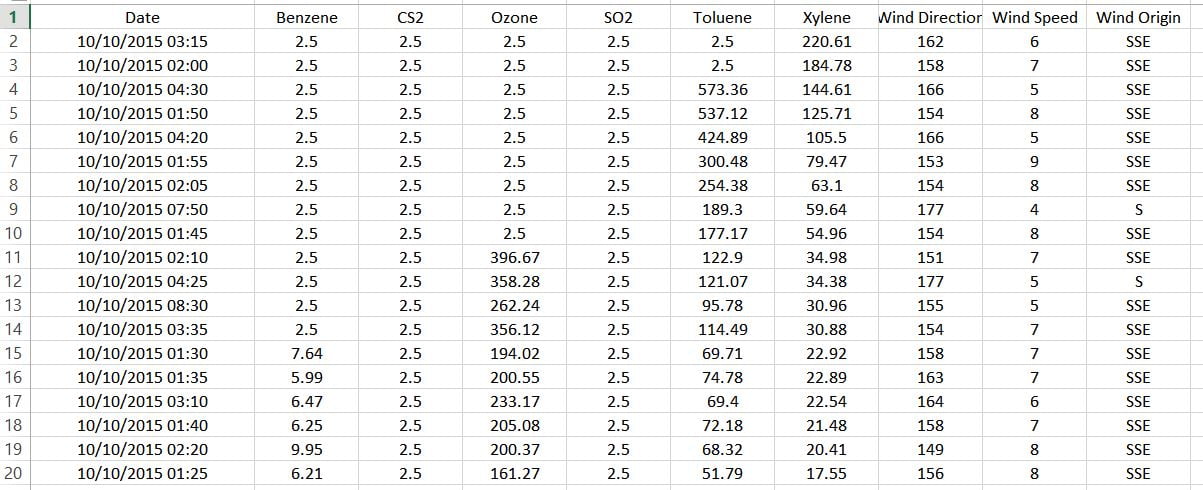
Lorsque vous importez un fichier csv dans R, avec une fonction read.csv() ou read.csv2(), par exemple, vous pouvez préciser que vous ne souhaitez pas que les chaînes de caractères soient converties en facteur, à l’aide de l’argument stringsAsFactors = FALSE….
J’ai placé le fichier AtchisonUV.csv, dans le dossier data du dossier de travail associé à un projet R
Pour plus de détail sur cette organisation de travail, vous pouvez consulter l’article suivant :
Pour importer les données dans R j’utilise alors la commande suivante :
Atch <-read.csv(here::here("data","AtchisonUV.csv"), stringsAsFactors = FALSE) Remarque : j’utilise la fonction read.csv() car le séparateur de colonne est une virgule, et le séparateur de décimale est un point.
Vous trouverez plus d’information sur l’importation de fichier csv en consultant l’article suivant :
str(Atch)
'data.frame': 31642 obs. of 10 variables:
$ Date : chr "10/10/15 3:15" "10/10/15 2:00" "10/10/15 4:30" "10/10/15 1:50" ...
$ Benzene : num 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 ...
$ CS2 : num 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 ...
$ Ozone : num 2.5 2.5 2.5 2.5 2.5 ...
$ SO2 : num 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 2.5 ...
$ Toluene : num 2.5 2.5 573.4 537.1 424.9 ...
$ Xylene : num 221 185 145 126 106 ...
$ Wind.Direction: int 162 158 166 154 166 153 154 177 154 151 ...
$ Wind.Speed : int 6 7 5 8 5 9 8 4 8 7 ...
$ Wind.Origin : chr "SSE" "SSE" "SSE" "SSE" ... library(lubridate)
library(tidyverse)
Atch <- Atch %>%
mutate(Date=mdy_hm(Date)) En utilisant encore la fonction `str()`, nous pouvons voir que la variable `Date` a été convertie en POSIXct, c’est-à-dire dans une classe de date et d’heure.
str(Atch$Date)
POSIXct[1:31642], format: "2015-10-10 03:15:00" ... Je vais alors créer, en utilisant la fonction date du package lubridate, une nouvelle variable Date, nommé Date_new qui ne contiendra que la partie date (j’espère que vous suivez 😜:
Atch <- Atch %>%
mutate(Date_new=date(Date)) %>%
select(Date, Date_new, everything()) Nous pouvons voir que la classe de cette variable `Date_new` est `date`:
head(Atch)
Date Date_new Benzene CS2 Ozone SO2 Toluene Xylene
1 2015-10-10 03:15:00 2015-10-10 2.5 2.5 2.5 2.5 2.50 220.61
2 2015-10-10 02:00:00 2015-10-10 2.5 2.5 2.5 2.5 2.50 184.78
3 2015-10-10 04:30:00 2015-10-10 2.5 2.5 2.5 2.5 573.36 144.61
4 2015-10-10 01:50:00 2015-10-10 2.5 2.5 2.5 2.5 537.12 125.71
5 2015-10-10 04:20:00 2015-10-10 2.5 2.5 2.5 2.5 424.89 105.50
6 2015-10-10 01:55:00 2015-10-10 2.5 2.5 2.5 2.5 300.48 79.47
Wind.Direction Wind.Speed Wind.Origin
1 162 6 SSE
2 158 7 SSE
3 166 5 SSE
4 154 8 SSE
5 166 5 SSE
6 153 9 SSE Si nous représentons les données d’ozone par exemple, nous pouvons voir que, par défaut, le pas de temps utilisé est le mois, et que l’étiquette est constituée par les trois premières lettres.
ggplot(Atch, aes(x=Date_new, y=Ozone))+
geom_point(colour="blue")+
theme_classic() 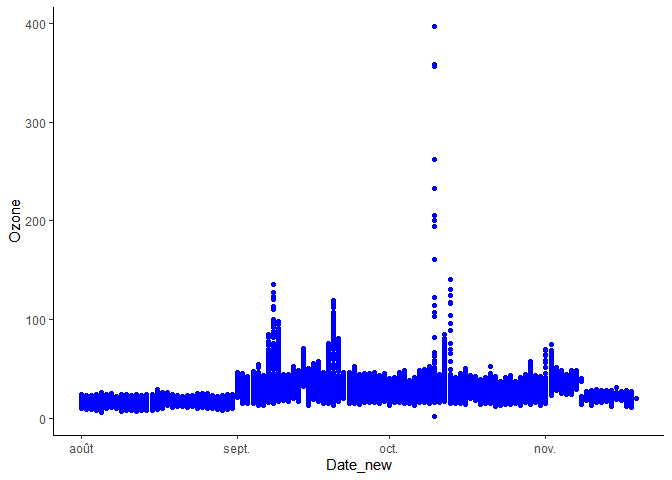
Pour passer à un pas de temps plus fin, par semaine, il est nécessaire de créer la séquence de date correspondante, comme ceci :
datebreaks <- seq(as.Date("2015-08-01"), as.Date("2015-11-19"), by="1 week")
datebreaks
## [1] "2015-08-01" "2015-08-08" "2015-08-15" "2015-08-22" "2015-08-29"
## [6] "2015-09-05" "2015-09-12" "2015-09-19" "2015-09-26" "2015-10-03"
## [11] "2015-10-10" "2015-10-17" "2015-10-24" "2015-10-31" "2015-11-07"
## [16] "2015-11-14" Nous pouvons alors préciser ce pas de temps, à l’aide de l’argument breaks de la fonction scale_x_date(), comme ceci :
ggplot(Atch, aes(x=Date_new, y=Ozone))+
geom_point(colour="blue")+
scale_x_date(breaks=datebreaks)+
theme_classic()+
theme(axis.text.x = element_text(angle=30, hjust=1)) 
Pour cela, nous allons :
Par exemple, pour n’afficher que le jour et le mois, nous devons utiliser `labels=date_format(« %d %b »)`:
library(scales)
ggplot(Atch, aes(x=Date_new, y=Ozone))+
geom_point(colour="blue")+
scale_x_date(breaks=datebreaks,labels=date_format("%d %b"))+
theme_classic()+
theme(axis.text.x = element_text(angle=30, hjust=1) 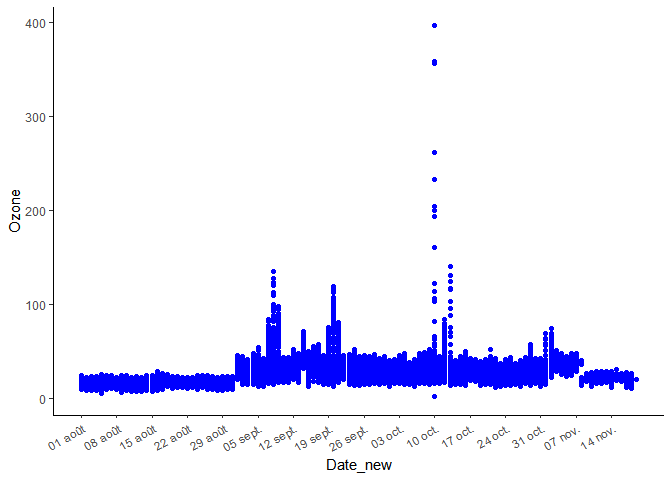
Ces format de dates ne sont pas très intuitifs, voici un tableau récapitulatif :
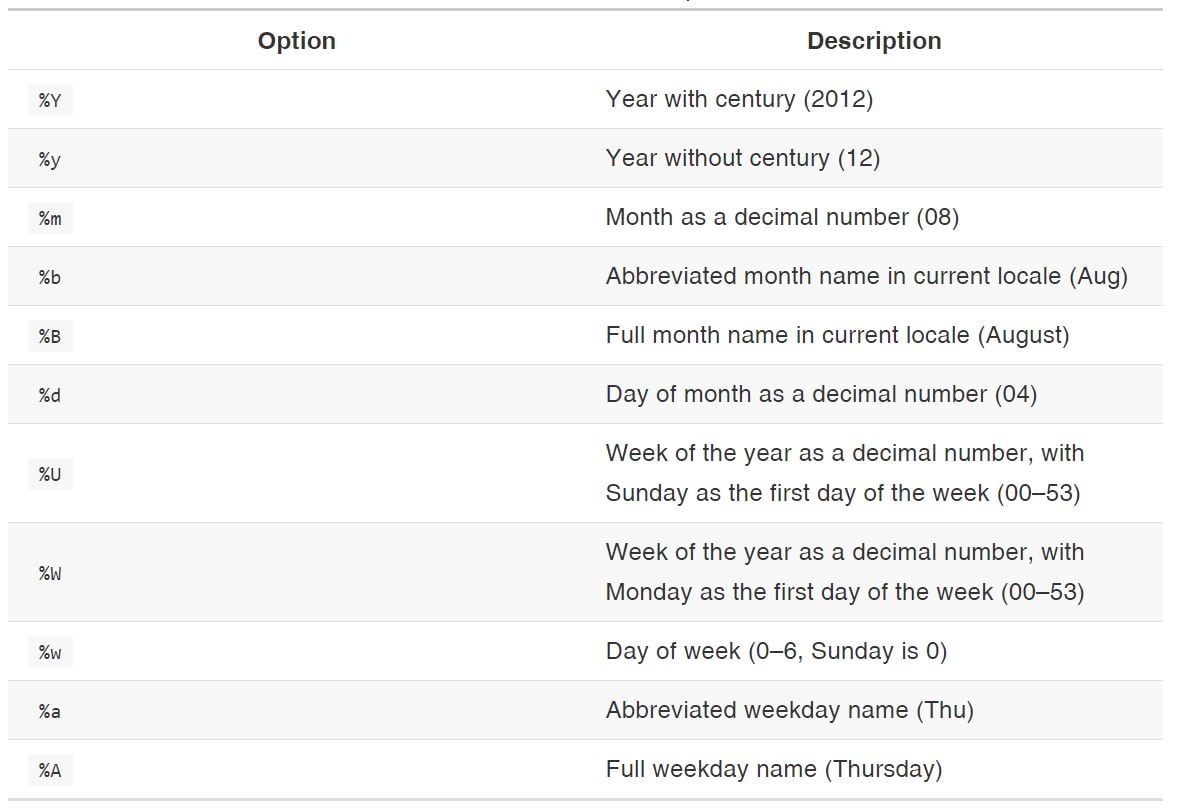
J’espère que cet article vous aidera à représenter vos séries temporelles.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏
Crédits photos :Image par Gerd Altmann de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
9 réponses
Merci, tes cours me sont d’un grand intérêt dans mes analyses. Merci encore pour les efforts malgré sûrement un boulot bien chargé.
Merci
Bonne continuation….
Merci. C’est très utile et bien expliqué.
Merci Claire, très enrichissant. Félicitations
Excellent article encore une fois Claire !
Vivement un prochain sur « Comment représenter des données longitudinales avec ggplot2 »
Merci beaucoup !
Bonjour,
J’ai refait les scripts et cet article m’est particulièrement utile. Il y a juste un élément que je ne comprend pas, c’est la troisième ligne ci dessous :
Atch %
mutate(Date_new=date(Date)) %>%
select(Date, Date_new, everything())
« mutate » crée bien une nouvelle colonne avec la fonction « date » mais que fait select et surtout « everything » ?
Merci beaucoup.
Bonjour Olivier,
la ligne select(Date, Date_new, everything()), permet de placer la variable Date en première position, la variable Date_new en seconde position, et toutes les autres variables ensuite.
La fonction everything() permet de designer toutes les autres variables !
Bonne continuation
Merci beaucoup pour ce beau travail. Vous nous aidez énormément dans nos analyses de données . Merci
Bonjour Claire
Merci pour cet article très édifiant.
Comment faire si nos données sont données par heure?
Je ne trouve pas ça dans le tableau récapitulatif donné plus haut.
Merci
Bonjour Christelle,
un peu de la même façon, en utilisant %h pour les heures, %m pour les minutes et %s pour les secondes.
Bonne continuation.