Lorsqu’on analyse des données, il est classique, lors d’une première étape, d’étudier la distribution de chacune des variables, ainsi que les liens qu’elles peuvent avoir entre elles. De nombreuses fonctions ont été développées pour répondre à ce besoin. Je vous propose, ici, d’explorer ensemble, les possibilités de la fonction `ggpairs()` du package `GGally`, qui est une extension du package `ggplot2`.
La fonction `ggpairs()` est la fonction principale du package `GGally`. Elle permet de représenter, à l’aide d’une matrice de plots, les distributions de chacune des variables, ainsi que leurs liens, deux à deux.
Commençons par un exemple simple, avec le jeu de données `iris` qui contient 4 variables numériques et une variable catégorielle à 3 niveaux :
library(GGally)
ggpairs(iris) 
Lorsque les variables étudiées sont de type numérique, `ggpairs()` utilise :
Lorsqu’une des variables est catégorielle (ici la variable `Species`) `ggpairs()` emploi des boxplots.
Je trouve que cette représentation est très efficace pour se faire une bonne idée des données !
Mais ce qui est vraiment intéressant, c’est que la fonction `ggpairs()` peut fournir une analyse des liens entre les variables, non plus globalement, mais en distinguant chaque modalité d’une variable catégorielle. Par exemple ici, une analyse des distributions et des liens entre les variables, pour chaque espèce d’iris !
Pour cela, il suffit d’indiquer la variable catégorielle dans l’argument `aes(color=….)` :
ggpairs(iris, aes(color=Species)) 
Et si vous voulez modifier les couleurs, vous pouvez employer les fonctions scale_fill_manual() et scale_colour_manual():
ggpairs(iris, aes(color=Species))+
scale_colour_manual(values = c("darkorange","purple","cyan4")) +
scale_fill_manual(values = c("darkorange","purple","cyan4")) 
Etudions, à présent, un second exemple, avec un jeu de données contenant plusieurs variables catégorielles :
library(funModeling)
data("heart_disease")
library(tidyverse)
HD2 <- heart_disease %>%
select(age, gender, chest_pain, max_heart_rate, has_heart_disease)
str(HD2)
## 'data.frame': 303 obs. of 5 variables:
## $ age : int 63 67 67 37 41 56 62 57 63 53 ...
## $ gender : Factor w/ 2 levels "female","male": 2 2 2 2 1 2 1 1 2 2 ...
## $ chest_pain : Factor w/ 4 levels "1","2","3","4": 1 4 4 3 2 2 4 4 4 4 ...
## $ max_heart_rate : int 150 108 129 187 172 178 160 163 147 155 ...
## $ has_heart_disease: Factor w/ 2 levels "no","yes": 1 2 2 1 1 1 2 1 2 2 ...
ggpairs(HD2) 
ggpairs(HD2, aes(color=gender)) 
Les distributions des variables numériques sont représentées à l’aide de barplots qui représentent les effectifs de chacune des modalités, en distinguant les groupes lorsque cela est précisé par l’argument `aes(color=gender)` ; par exemple la variable `chest pain`.
Des représentations de type « mosaic plot » sont réalisées pour représenter les distributions des croisements des modalités de deux variables catégorielles ; par exemple le croisement entre `gender` et `has_heart_rate`. Les superficies des rectangles sont proportionnelles aux effectifs .
La table de contingence suivante nous permet de constater que les femmes atteintes de pathologie cardiaques (has_heart_disease=yes) sont bien sous-représentées dans ces données (n=25).
table(HD2$gender, HD2$has_heart_disease)
##
## no yes
## female 72 25
## male 92 114 J’en ai profité pour explorer un petit peu les autres fonctions du package GGally. Voici celles qui m’ont particulièrement intéressée.
En parcourant les fonctions du package `GGally` j’ai découvert la fonction `ggbivariate()` qui permet plus facilement qu’avec `ggplot2`, de faire des visualisations bivariées à l’aide de barplots de type stack.
Et cerise sur le gâteau, la fonction affiche automatiquement les pourcentages !
ggbivariate(HD2, outcome = "gender", explanatory = "chest_pain") 
Vous pouvez aussi considérer plusieurs variables exploratoires, en même temps :
ggbivariate(HD2, outcome = "gender", explanatory = c("chest_pain", "has_heart_disease"))

Vous pouvez également modifier les couleurs affichées dans la fonction `scale_fill_brewer()` avec l’argument `type`:
ggbivariate(HD2, outcome = "gender", explanatory = c("chest_pain", "has_heart_disease"))+
scale_fill_brewer(type="seq")
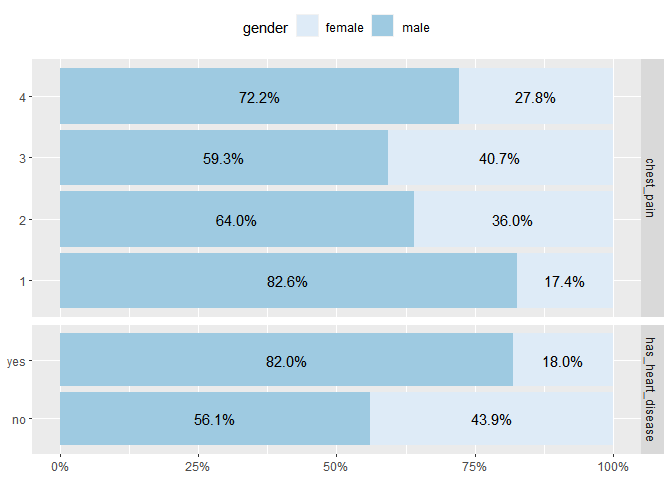
ggbivariate(HD2, outcome = "gender", explanatory = c("chest_pain", "has_heart_disease"))+
scale_fill_brewer(type="qual") 
Vous trouverez plus de possibilités dans ce document.
Ces fonctions sont assez similaires à la fonction `ggbivariate()`. Elles permettent de faire des représentations bivariées, mais en contrôlant la position : en colonne ou en ligne.
Ici en colonne:
ggally_colbar(HD2, mapping = aes(x = gender, y = chest_pain)) 
ggally_colbar(HD2, mapping = aes(y = gender, x = chest_pain)) 
Là, en ligne :
ggally_rowbar(HD2, mapping = aes(x = gender, y = chest_pain)) 
ggally_rowbar(HD2, mapping = aes(y = gender, x = chest_pain)) 
L’affichage des pourcentages est un vrai plus !
Cette fonction permet de représenter graphiquement les coefficients des différents paramètres d’un modèle linéaire, ainsi que leur intervalle de confiance.
Cela a surtout du sens dans une situation de régression logistique, car cela permet :
Pour plus de détails sur ces notions , vous pouvez consulter les deux articles suivants :
Voici un exemple :
reglog <- glm(has_heart_disease~ gender + max_heart_rate + chest_pain, family = binomial, data = HD2)
ggcoef(reglog, exponentiate = TRUE) 
L’argument `exponentiate=TRUE` permet de considérer l’exponentiel des coefficients, c’est-à-dire les odds ratio.
Des améliorations visuelles peuvent également être apportées :
ggcoef(reglog, exponentiate = TRUE, color = "blue", size = 5, shape = 18)

Pour vérifier, les odds ratio peuvent être obtenus comme cela :
exp(coef(reglog))
## (Intercept) gendermale max_heart_rate chest_pain2 chest_pain3
## 28.6322056 4.7584880 0.9646497 0.7271628 0.7733996
## chest_pain4
## 6.2948230 Et les intervalles de confiance, comme cela :
exp(confint(reglog))
## 2.5 % 97.5 %
## (Intercept) 2.6278514 330.0899379
## gendermale 2.5010280 9.4204515
## max_heart_rate 0.9500458 0.9786125
## chest_pain2 0.2119426 2.5477382
## chest_pain3 0.2614101 2.4257973
## chest_pain4 2.2678260 19.0046296 Si vous voulez en savoir plus sur les possibilités du package GGally, vous pouvez consulter sa documentation, ici .
Au final, que pensez vous de ce package GGally, et surtout de sa fonction ggpairs() ? Est ce que vous la découvrez, ou bien vous aviez déjà l’habitude de l’utiliser ?
Dites le moi en commentaires ! Et si vous employez d’autres fonctions pour explorer vos données, n’hésitez pas à les partager.
En attendant, si cet article vous a plu ou vous a été utile, n’oubliez pas de le partager ! Vous pouvez également soutenir le blog par un don libre sur la page Tipee.


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
7 réponses
Bonjour Claire,
J’ai l’habitude d’utiliser le package GGally, mais je ne savais pas toutes ces fonctions sur celle qui affiche les pourcentage (ggbivariate), elle est géniale.
Vraiment merci
Merci beaucoup Claire,
Vraiment très impressionnant.
Je voudrais juste savoir la différence entre les deux corrélations: 0,872 et -0,428 de Ptal length??
Et est-ce que corr = -0,394 de Max_heart_rate, c’est la corrélation de cette variable avec gender??
Quand vous parlez l’intersection partie supérieure et inférieure de deux variable ici, est ce que c’est la première colonne de première variable à la deuxième ligne de deuxième variable? Car toutes les variables se trouvent aux colonnes.
Cordialement.
Bonjour,
Corr=0.872 est le coefficient de corrélation entre Sepal.Length et Petal.Length.
Corr=-0.428 est le coefficient de corrélation entre Petal.Length et Sepal.Width.
Corr=-0.94 est le coefficient de corrélation entre Max heart rate et age.
L’intersection partie supérieure est la première ligne et 2ème colonne (du premier graph par exemple)
L’intersection partie inférieure est la deuxième ligne et 1er colonne (du premier graph par exemple)
Bonne continuation
Félicitations Claire pour ce super article. Il revèle la puissance de GGally en data visualisation.
merci beaucoup pour ce nouvel article, j’ai trop kiffé. j’ai beaucoup appris. force à toi !!!
Merci beaucoup Claire c’est très impressionnant
Bonjour et merci pour cette page.
Pour info un typo:
« Anlayse globale »
idem un peu plus bas.