Il y a quelque temps, j’ai écrit un article expliquant comment, après une ANOVA, indiquer les p-values ou les différences significatives sur un graph , en employant le package `ggpubr`.
Par exemple, pour une ANOVA non paramétrique (test de Kruskal Wallis) :
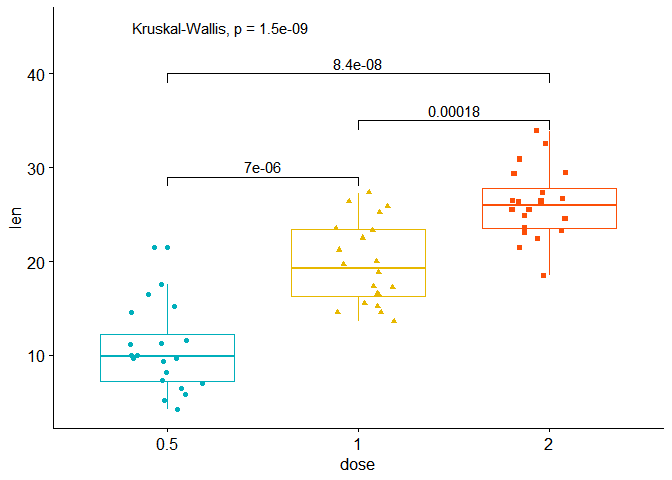
Je disais qu’une des limites du package était que les p-values des comparaisons multiples, affichées sur le graph, étaient les p-values non ajustées. Or quand on réalise une ANOVA (paramétrique ou non paramétrique), les p-values des comparaisons multiples doivent être
ajustées. Et donc que se sont ces p-values ajustées qu’il faudrait pouvoir afficher.
Pour plus d’informations sur « pourquoi il faut ajuster les p-values des comparaisons multiples », consultez l’ article : « Comparaisons multiples et ajustement des pvalues avec le logiciel R«
Et puis la semaine dernière, un lecteur du blog m’a demandé si j’avais finalement trouvé une solution pour afficher ces p-values ajustées.
Je ne m’y étais plus intéressée alors en en première approche je lui ai dit de faire lui même les traits sous ggplot2 avec la fonction `geom_segment()`, puis ajouter les p-values avec la fonction `annotate()`.
Et puis, en cherchant un peu plus, j’ai trouvé une solution qui avait été postée par un utilisateur du package `ggpubr` dans l’onglet « Issue » du répertoire GitHub du package. C’est cette solution que je vous explique ici en pas à pas.
La solution consiste à :
1. Indiquer les comparaisons deux à deux souhaitées sous forme d’une list
2. Créer un data frame qui contiendra, les p-values ajustées en utilisant la fonction compare_means(), et en précisant :
3. Ajouter, à ce data frame, une variable y.position dans laquelle on précise le futur emplacement, sur le graph, au niveau de l’axe des ordonnées, des p-values des comparaisons multiples
4. Faire le graph
J’utilise ici le jeu de données ToothGrowth (contenu dans le package dataset, chargé par défaut !) :
data("ToothGrowth")
TG <- ToothGrowth
head(TG)
## len supp dose
## 1 4.2 VC 0.5
## 2 11.5 VC 0.5
## 3 7.3 VC 0.5
## 4 5.8 VC 0.5
## 5 6.4 VC 0.5
## 6 10.0 VC 0.5
str(TG)
## 'data.frame': 60 obs. of 3 variables:
## $ len : num 4.2 11.5 7.3 5.8 6.4 10 11.2 11.2 5.2 7 ...
## $ supp: Factor w/ 2 levels "OJ","VC": 2 2 2 2 2 2 2 2 2 2 ...
## $ dose: num 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 ... Je commence par passer la variable dose en facteur (par défaut, R la considère comme une variable numérique) :
TG$dose <- as.factor(TG$dose)
str(TG)
## 'data.frame': 60 obs. of 3 variables:
## $ len : num 4.2 11.5 7.3 5.8 6.4 10 11.2 11.2 5.2 7 ...
## $ supp: Factor w/ 2 levels "OJ","VC": 2 2 2 2 2 2 2 2 2 2 ...
## $ dose: Factor w/ 3 levels "0.5","1","2": 1 1 1 1 1 1 1 1 1 1 ... On réalise les 3 étapes décrites précédemment :
# on indique les comparaisons deux à deux
my_comparisons <- list( c("0.5", "1"), c("1", "2"), c("0.5", "2") ) Pour cela, nous utilisons la fonction compare_means(), en précisant la méthode d’ajustement souhaitée, et le type de tests.
Ici, j’appelle mc_t_test le data frame qui contiendra les informations des comparaisons et notamment les p-values ajustées. Je choisis d’utiliser la méthode d’ajustement d’Holm. D’autres choix sont possibles (cf. paragraphe 5). Et comme il s’agit d’une ANOVA paramétrique, je précise , dans l’argument method que les tests à employer sont des tests t.
mc_t_test <- compare_means(len ~ dose, comparisons = my_comparisons, p.adj= "holm", method='t.test', data = ToothGrowth)
mc_t_test
## # A tibble: 3 x 8
## .y. group1 group2 p p.adj p.format p.signif method
##
## 1 len 0.5 1 1.27e- 7 2.50e- 7 1.3e-07 **** T-test
## 2 len 0.5 2 4.40e-14 1.30e-13 4.4e-14 **** T-test
## 3 len 1 2 1.91e- 5 1.90e- 5 1.9e-05 **** T-test Cette variable `y.position` permet de préciser le futur emplacement, sur le graph, au niveau de l’axe des ordonnées, des p-values des comparaisons multiples:
Je choisis les valeurs y=29 ,y=35, et y=39 en m’aidant du premier graph réalisé dans l’introduction.
# on ajoute la hauteur ou indiquer les p-values sur le graphs
mc_t_test <- mc_t_test %>%
mutate(y.position = c(29, 35, 39))
mc_t_test
## # A tibble: 3 x 9
## .y. group1 group2 p p.adj p.format p.signif method y.position
##
## 1 len 0.5 1 1.27e- 7 2.50e- 7 1.3e-07 **** T-test 29
## 2 len 0.5 2 4.40e-14 1.30e-13 4.4e-14 **** T-test 35
## 3 len 1 2 1.91e- 5 1.90e- 5 1.9e-05 **** T-test 39 Pour plus d’infos sur la création d’une variable à l’aide de la fonction mutate() et de l’utilisation du symbole pipe %>%, consultez l’article « Initiation à la manipulation de données avec le package dplyr «
On indique method = "anova" dans la fonction stat_compare_means() et on indique le data frame mc_t_test dans la fonction stat_pvalue_manual() :
ggboxplot(TG, x = "dose", y = "len", color = "dose",
palette =c("#00AFBB", "#E7B800", "#FC4E07"),
add = "jitter", shape = "dose")+
# ajout de la p-value globale
stat_compare_means(method = "anova", label.y=45)+
# ajout des p-values des comparaisons deux à deux grace à la fonction
# stat_pvalue_manual et l'objet mc_t_test
stat_pvalue_manual(mc_t_test, label = "p.adj")+
theme(legend.position="none") 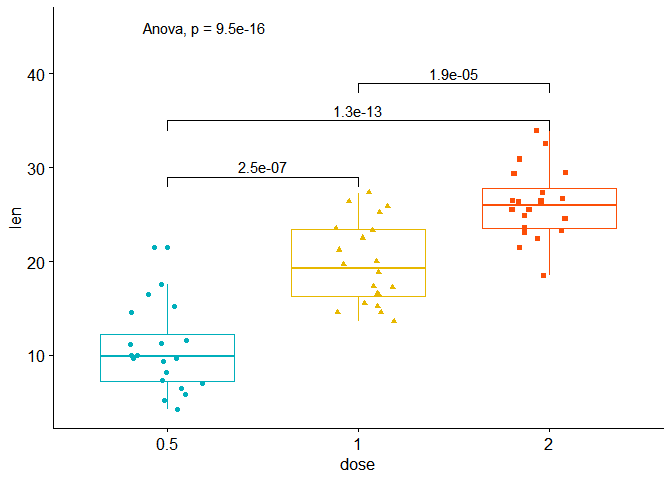
my.anova <- lm(len~dose, data=TG)
library(car)
Anova(my.anova)
## Anova Table (Type II tests)
##
## Response: len
## Sum Sq Df F value Pr(>F)
## dose 2426.4 2 67.416 9.533e-16 ***
## Residuals 1025.8 57
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 La p-value est bien identique à celle du graph.
Lorsque l’argument method='t.test' est utilisé dans la fonction compare_mean() du package ggpubr , les tests t employés sont des tests pour variances inégales. Ces tests t sont aussi appelés tests de Welch.
Il est possible de réaliser tous les tests t deux à deux, en utilisant la fonction pairwise.t.test. Pour obtenir des tests de Welch, on utilise l’argument pool.sd =FALSE.
pairwise.t.test(TG$len, TG$dose, p.adj="holm", pool.sd =FALSE)
##
## Pairwise comparisons using t tests with non-pooled SD
##
## data: TG$len and TG$dose
##
## 0.5 1
## 1 2.5e-07 -
## 2 1.3e-13 1.9e-05
##
## P value adjustment method: holm Lorsque l’argument method='t.test' est utilisé dans la fonction compare_mean() du package ggpubr , les tests t employés sont des tests pour variances inégales. Ces tests t sont aussi appelés tests de Welch.
Il est possible de réaliser tous les tests t deux à deux, en utilisant la fonction pairwise.t.test. Pour obtenir des tests de Welch, on utilise l’argument pool.sd =FALSE.
Ces p-values correspondent bien à celle du graph.
L’ANOVA non paramétrique est appelée test de Kruskal Wallis.
On conserve les comparaisons deux à deux précédentes:
# on indique les comparaisons deux à deux
my_comparisons <- list( c("0.5", "1"), c("1", "2"), c("0.5", "2") )
mc_wilcox_test <- compare_means(len ~ dose, comparisons = my_comparisons, p.adj= "holm", method='wilcox.test', data = ToothGrowth) Pour cela, nous utilisons la fonction compare_means()`, en précisant la méthode d’ajustement souhaitée, et le type de tests.
Ici j’appelle `mc_wilcox_test` le data frame qui contiendra les informations des comparaisons et notamment les p-values ajustées. Comme précédemment, je choisis d’utiliser la méthode d’ajustement d’Holm. D’autres choix sont possibles (paragraphe 5 ). Et comme il s’agit d’une ANOVA non paramétrique, je précise que les tests à employer sont des tests de wilcoxon.
mc_wilcox_test
## # A tibble: 3 x 8
## .y. group1 group2 p p.adj p.format p.signif method
##
## 1 len 0.5 1 0.00000702 0.000014 7.0e-06 **** Wilcoxon
## 2 len 0.5 2 0.0000000841 0.00000025 8.4e-08 **** Wilcoxon
## 3 len 1 2 0.000177 0.00018 0.00018 *** Wilcoxon Je garde les même valeurs que précédemment : y=29 ,y=35, et y=39
# on ajoute la hauteur ou indiquer les p-values sur le graphs
mc_wilcox_test <- mc_wilcox_test %>%
mutate(y.position = c(29, 35, 39))
mc_wilcox_test
## # A tibble: 3 x 9
## .y. group1 group2 p p.adj p.format p.signif method y.position
##
## 1 len 0.5 1 7.02e-6 1.40e-5 7.0e-06 **** Wilco~ 29
## 2 len 0.5 2 8.41e-8 2.50e-7 8.4e-08 **** Wilco~ 35
## 3 len 1 2 1.77e-4 1.80e-4 0.00018 *** Wilco~ 39 On indique method = "kruskal.test" dans la fonction stat_compare_means() et on indique le data frame mc_wilcox_test dans la fonction stat_pvalue_manual()
ggboxplot(TG, x = "dose", y = "len", color = "dose",
palette =c("#00AFBB", "#E7B800", "#FC4E07"),
add = "jitter", shape = "dose")+
# ajout de la p-value globale
stat_compare_means(method = "kruskal.test", label.y=45)+
# ajout des p-values des comparaisons deux à deux grace à la fonction
# stat_pvalue_manual et l'objet mc_wilcox_test
stat_pvalue_manual(mc_wilcox_test, label = "p.adj")+
theme(legend.position="none") 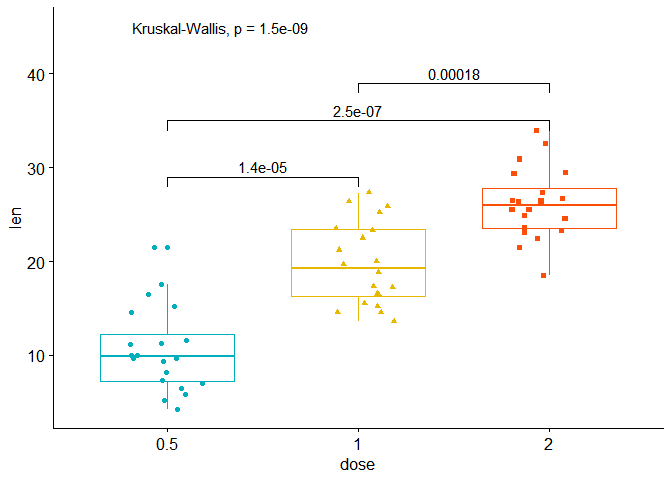
my.ks <- kruskal.test(len~dose, data=TG)
my.ks
##
## Kruskal-Wallis rank sum test
##
## data: len by dose
## Kruskal-Wallis chi-squared = 40.669, df = 2, p-value = 1.475e-09 La p-value est bien identique à celle du graph.
Il est possible de réaliser tous les tests de Wilcoxon deux à deux, en utilisant la fonction pairwise.wilcox.test :
pairwise.wilcox.test(TG$len, TG$dose, p.adj="holm")
##
## Pairwise comparisons using Wilcoxon rank sum test
##
## data: TG$len and TG$dose
##
## 0.5 1
## 1 1.4e-05 -
## 2 2.5e-07 0.00018
##
## P value adjustment method: holm Ces p-values correspondent bien à celle du graph.
Remarques : les messages de warning indiquent simplement qu’il existe des valeurs de `len` identiques dans plusieurs groupes et que cela rend impossible le calcule d’une p-value exacte. Une approximation sera alors utilisée (ce n’est pas grave !).
Il existe plusieurs méthodes d’ajustement des p-values qui peuvent être employées dans les fonctions compare_means(), pairwise.t.test() et pairwise.wilcox.test(), via l’arugment p.adj.
Pour connaitre comment préciser ces méthodes, utiliser la commande suivante :
p.adjust.methods
## [1] "holm" "hochberg" "hommel" "bonferroni" "BH"
## [6] "BY" "fdr" "none" Pour plus d’information, consulter la page d’aide, en utilisant la commande :
?p.adjust Crédits photos : geralt

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
13 réponses
Très intéressant. À recommander vivement. L’illustration graphique est parlante.
Merci claire pour cet article très riche
Je trouve cela particulièrement intéressant, car, personnellement, je ne trouvais une pas grande utilité à comparer des boxplots. Mais avec les p-values indiqués comme ceci ça a une vraie valeur ajoutée !
Merci Claire
Bonjour, tout d’abord merci pour l’article.
J’aimerai savoir s’il est possible de spécifier le nombre de comparaison que l’on souhaite faire dans le p.adj. Car spécifier que la correction se fait avec Holms est une chose mais j’aimerai être sur que le nombre de comparaisons est exactement celui que je souhaite.
Bine à vous,
MP
Bonjour,
On ne précise pas directement le nombre de comparaisons mais on spécifie les comparaisons individuellement via
my_comparisons <- list( c("0.5", "1"), c("1", "2"), c("0.5", "2") )et ensuite my_comparaisons passe en argument de stat_compare_means(). Bonne continuation
Bonjour,
Encore merci Claire pour le partage.
Cordialement
Mais comment faire lorsque le modèle de comparaison est sous tendu par un glm et non un lm
Et ben, je pense qu’il faut faire les segments horizontaux sous ggplot2 avec geom_segment() et ajouter les p-values ajustées avec annotate(), mais c’est fastidieux. J’essaierai de le montrer dans un prochain article.
Bonne continuation
Merci beaucoup Claire. Cet article m’est très utile. Merci
Bonjour, Je vous remercie pour cet article vraiment intéressant. J’avais une question pour le test de kruskal Wallis, comment est-ce qu’on pourrait procéder quand on se retrouve dans un cas avec un rang, au lieu de plusieurs.
Bonjour,
je pense que ce n’est pas possible, vous devez avoir des réplicats.
Bonne continuation
Très utiles
Merci.