
Cette publication est la mise en forme d’une intervention réalisée le 6 mai dernier au congrès ACADM 2026, le congrès des data managers académiques, dans laquelle j’ai illustré par des exemples concrets comment R peut répondre aux besoins quotidiens du data management. La question du passage à R se pose aujourd’hui pour de nombreuses structures publiques, dans un contexte où la fin annoncée des licences SAS les amène à chercher des alternatives crédibles et pérennes.
Avant les exemples, quelques arguments de fond :
Avant d’aller plus loin, deux mots pour clarifier de quoi on parle. R et RStudio sont souvent évoqués ensemble, mais ce sont deux outils distincts.
R est le langage de programmation.
C’est lui qui exécute le code, fait les calculs, produit les graphiques. Il s’utilise via une console — mais une console toute seule n’est pas très confortable au quotidien.
RStudio est l’interface de développement (un IDE) conçue spécifiquement pour travailler avec R.
C’est l’environnement où l’on écrit ses scripts, exécute son code, visualise ses résultats, et organise ses projets.
En pratique, on installe les deux : R d’abord (le moteur), RStudio ensuite (le tableau de bord). L’interface de RStudio se divise en quatre zones principales :
L’éditeur de scripts (haut gauche) — où l’on rédige son code, qu’on peut sauvegarder, partager et rejouer.
La console (bas gauche) — où le code s’exécute et où s’affichent les sorties textuelles.
L’environnement (haut droite) — qui liste tous les objets actifs : data frames, vecteurs, variables, fonctions…
Le panneau utilitaire (bas droite) — qui regroupe les fichiers du projet, les graphiques produits, les packages installés, l’aide.
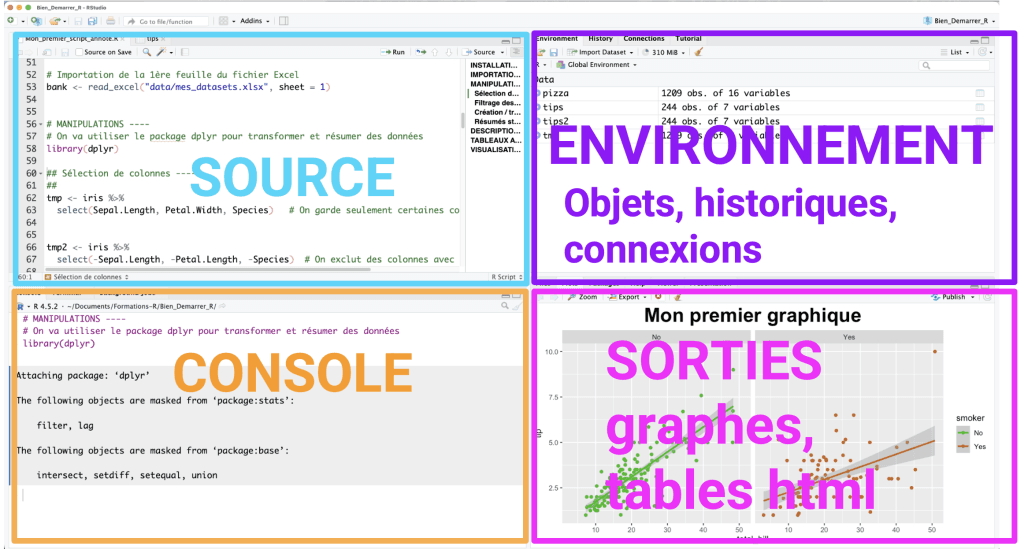
Cette organisation peut paraître chargée au premier abord, mais on s’y repère très vite. Et toute la suite : l’écriture de scripts reproductibles, l’enchaînement des manipulations, la production de rapports , se fait sans jamais quitter cet environnement unique.
Pour rendre les exemples concrets, j’utilise tout au long de cet article un même jeu de données fictif, nommé clinical_data.
Il s’agit de données cliniques simulées, longitudinales : chaque ligne représente un patient à une visite donnée (Screening, Mois 1, Mois 3). On y trouve typiquement un identifiant de sujet, un centre investigateur, un sexe codé numériquement, un âge, une date de randomisation, une date de visite, un score clinique (score de pression artérielle, score_bp), et un groupe de traitement.
Comme dans la vraie vie, le fichier de départ n’est pas propre :
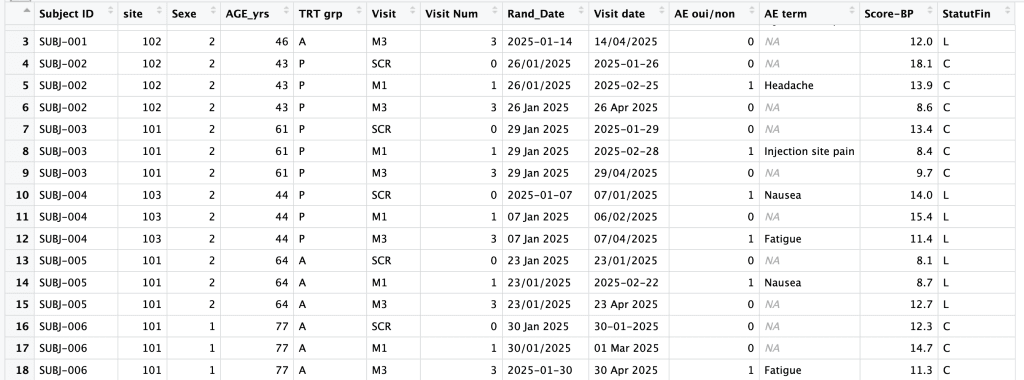
Bref, un fichier représentatif de ce qu’on récupère quotidiennement en data management. C’est précisément ce désordre qui va servir de point d’appui pour illustrer ce que R, et plus particulièrement le tidyverse, permet de faire — proprement, simplement, et de manière reproductible.
library(readr)
clinical_data<- read_csv(here::here("data/clinical_data_messy.csv")) Avant de plonger dans les exemples, un mot sur ce qui rend R particulièrement adapté au travail de data manager : le tidyverse. Le tidyverse est une collection cohérente de packages R conçus pour la manipulation, la transformation et la visualisation de données.
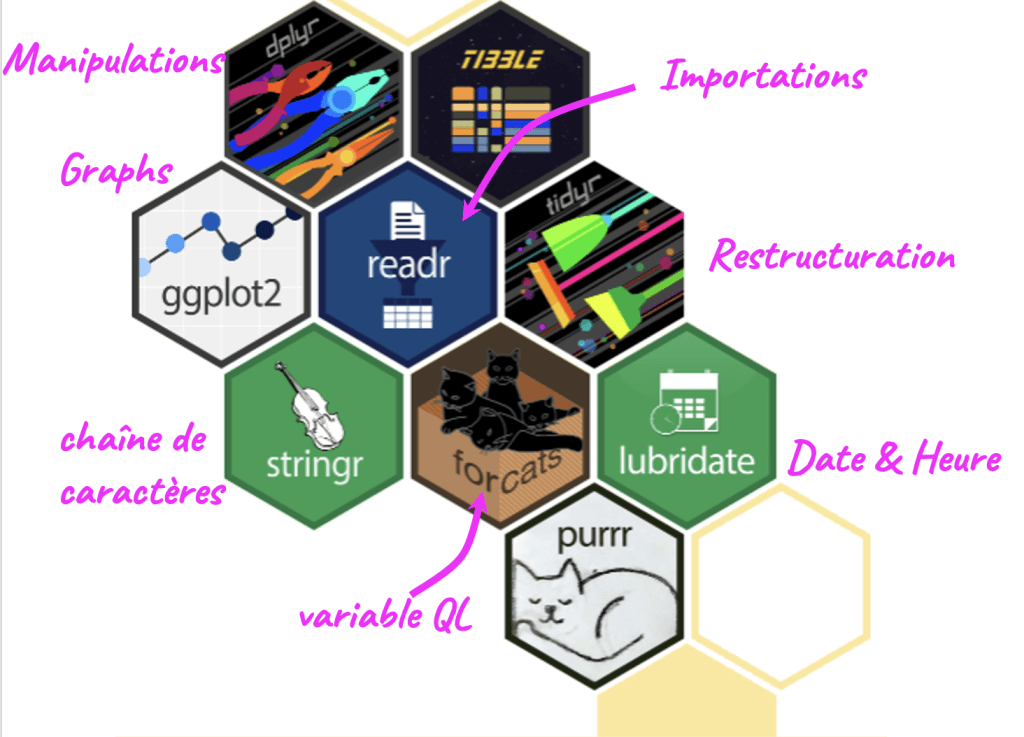
Chaque package couvre un domaine précis : dplyr pour manipuler les data frames, tidyr pour les restructurer, lubridate pour les dates, stringr pour les chaînes de caractères, ggplot2 pour les graphiques.
L’ensemble repose sur une logique commune : des verbes simples pour chaque action : filter()pour filtrer, select() pour sélectionner, mutate() pour créer ou transformer, rename() pour renommer.
Le principe clé qui rend le code particulièrement lisible est le pipe (|> ou %>%).
Il permet d’enchaîner les étapes naturellement, sans imbriquer les fonctions ou multiplier les objets intermédiaires.
Voici un exemple typique :
# pour ouvrir tous les packages du tidyverse
library(tidyverse)
clinical_data |>
select(sexe, age, score_bp) |>
filter(sexe == "F") |>
mutate(age_cat = if_else(age > 50, "50+", "<50")) Cela se lit comme une phrase : “prendre les données clinical_data et puis, sélectionner trois variables, et puis filtrer les femmes, et puis créer une variable age_cat avec un if_else. »
Le code raconte l’histoire de la transformation, étape par étape. Cela facilite la relecture, l’audit, et le travail en équipe.
Le tidyverse, c’est donc à la fois une boîte à outils complète pour la quasi-totalité des tâches courantes de data management, et une syntaxe accessible qui rend la prise en main très rapide.
C’est l’une des premières difficultés quand on récupère un fichier de données collectées : des noms de colonnes hétérogènes, avec majuscules, espaces, accents, caractères spéciaux.

Renommer une par une est fastidieux. Avec le package janitor, c’est une ligne :
library(janitor)
clinical_data_clean <- clinical_data |>
clean_names() Ici, le résultat de l’opération est stocké dans un nouvel objet nommé clinical_data_clean.

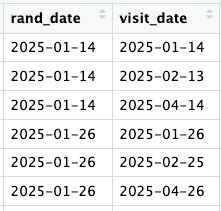
Autre défi classique du data management : les dates. Dans un même fichier, une colonne de dates peut contenir 15/03/2024, 2024-03-15, 15 mars 2024, 03/15/2024, ou encore 15-03-24 , autant de formats différents à harmoniser avant de pouvoir travailler. C’est précisément ce qu’on retrouve dans le tableau clinical_data :
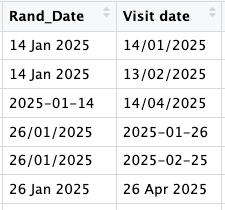
Le package datefixR règle ça en une commande :
library(datefixR)
clinical_data_clean <- clinical_data_clean |>
fix_date_df(c("rand_date", "visit_date")) Toutes les dates sont automatiquement normalisées au format ISO 8601 (YYYY-MM-DD), prêtes à être exploitées.
C’est sans doute l’argument qui parle le plus aux data managers issus de SAS : pouvoir associer à chaque variable un label descriptif, et à chaque code une décodification lisible. Le packagelabelled permet exactement ça :
library(labelled)
# Labels de variables
var_label(clinical_data_clean) <- list(
subject_id = "Identifiant du sujet",
site = "Centre investigateur",
sexe = "Sexe du patient"
)
# Labels de valeurs
val_labels(clinical_data_clean$sexe) <- c("Homme" = 1, "Femme" = 2)
val_labels(clinical_data_clean$visit) <- c("Screening" = "SCR",
"Mois 1" = "M1",
"Mois 3" = "M3")
val_labels(clinical_data_clean$site) <- c("Lariboisière" = 101,
"CHU Lyon" = 102,
"IPC (Marseille)" = 103) Les noms de variables restent courts pour le code, mais les libellés enrichis viennent documenter la base de données.
Important : lors de l’import de fichiers SAS dans R, les labels de variables sont automatiquement conservés dans R. La transition est donc transparente.
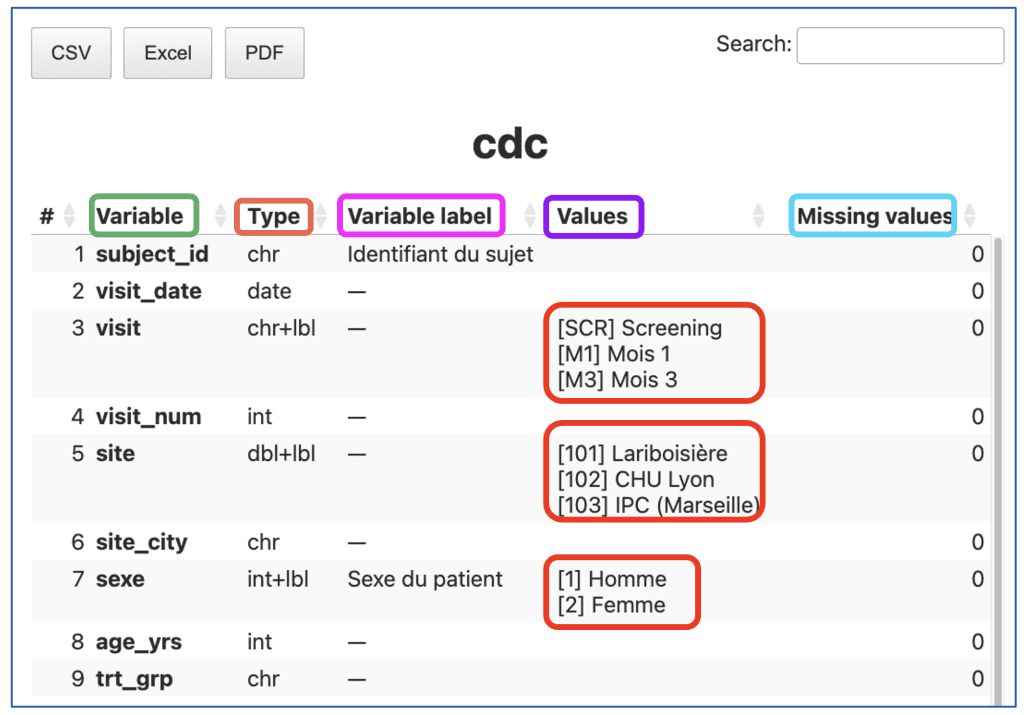
Visualiser le dictionnaire des variables
Une fois les labels en place, le package guideR permet de produire en une commande un dictionnaire complet de la base de données, exploitable directement dans RStudio :
library(guideR)
clinical_data_clean |>
view_dictionary() On obtient un tableau qui croise, pour chaque variable : son nom court, son label descriptif, son type, et les libellés associés à ses valeurs codées. C’est un livrable extrêmement utile pour la documentation, l’audit, et la transmission de la base à un autre intervenant.
Une fois les labels définis, ils peuvent aussi être repris automatiquement dans les graphiques et les tables, dès lors que les fonctions utilisées sont compatibles avec le format labelled (ce qui est le cas de la grande majorité des packages dédiés aux tables descriptives et à la visualisation).
Plus besoin de se rappeler que sexe = 1 correspond aux hommes : la sortie l’indique directement.
C’est l’un des grands intérêts d’investir un peu de temps pour poser les labels au début d’un projet : tout le travail aval (tables descriptives, graphiques, contrôles, rapports) en bénéficie automatiquement.
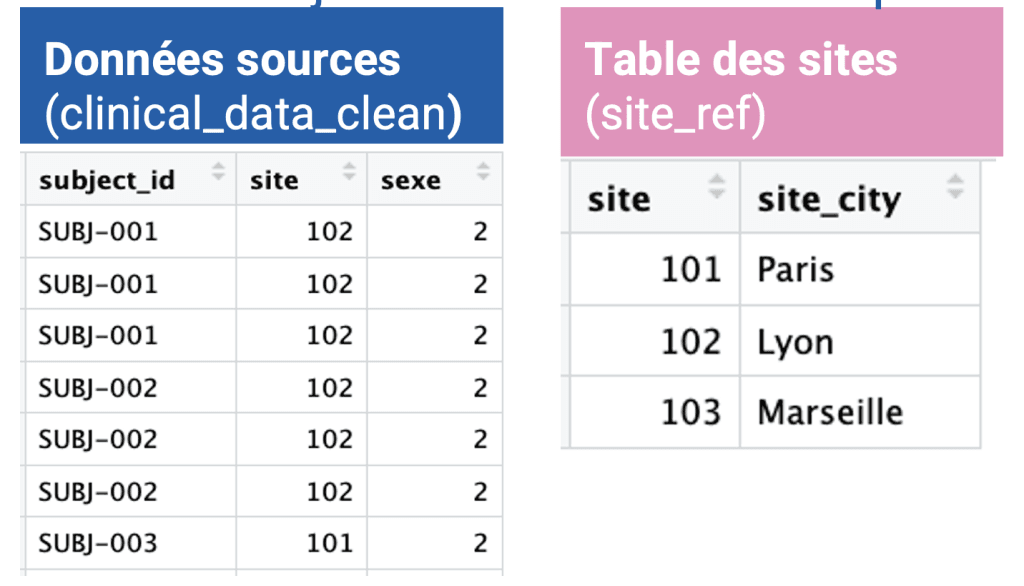
Le data management implique presque toujours de combiner plusieurs sources de données : enrichir une base patient avec un référentiel de centres, fusionner une cohorte de cas et une cohorte de témoins, agréger plusieurs exports d’extraction. R offre une syntaxe limpide pour ces opérations grâce à dplyr.
Imaginons que nos centres investigateurs soient codés (101, 102, 103) et qu’on dispose en parallèle d’une table de référence site_ref qui associe chaque code à la ville correspondante
Pour enrichir clinical_data_clean avec ces informations, une seule fonction suffit :
clinical_data_clean <- clinical_data_clean |>
left_join(site_ref, by = "site") Voici le résultat :
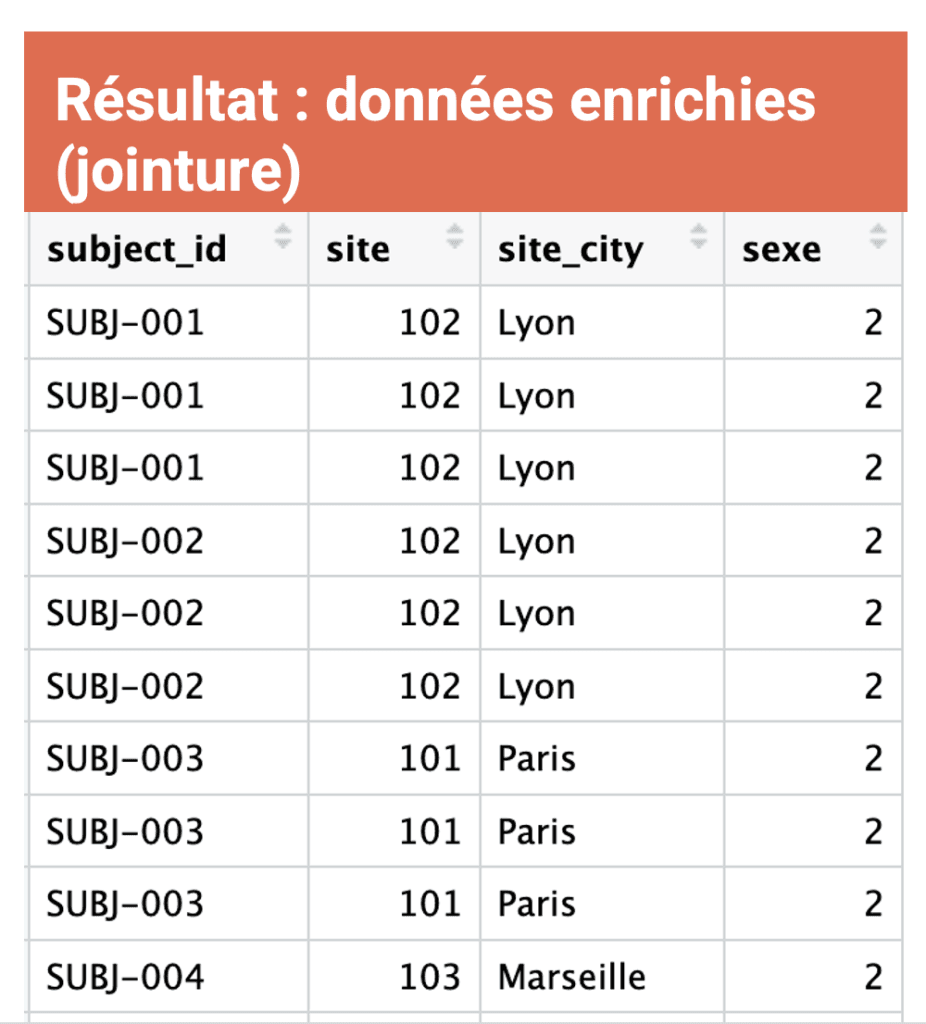
left_join() conserve toutes les lignes de la table de gauche (clinical_data_clean) et y ajoute les colonnes correspondantes de la table de droite (site_ref), en s’appuyant sur la clé commune (site). C’est l’équivalent d’un MERGE SAS, en plus lisible. D’autres fonctions sont également disponibles :
inner_join() ne conserve que les lignes pour lesquelles une correspondance existe dans les deux tables.right_join() fait l’inverse du left_join() : toutes les lignes de la table de droite sont conservées, même lorsqu’aucune correspondance n’existe dans la table de gauche.full_join() conserve toutes les lignes des deux tables, qu’il y ait ou non une correspondance.anti_join() permet d’identifier les lignes présentes dans une table mais absentes de l’autre – très utile pour détecter des sujets non appariés, des codes inconnus ou des problèmes de qualité de données.semi_join() conserve uniquement les lignes de la première table ayant une correspondance dans la seconde, sans ajouter les colonnes de cette dernièreAutre cas fréquent : on a constitué séparément une table patients et une table temoins, et on veut les empiler pour les analyser ensemble. La structure des deux tables est identique (mêmes variables, mêmes formats), on les concatène simplement :
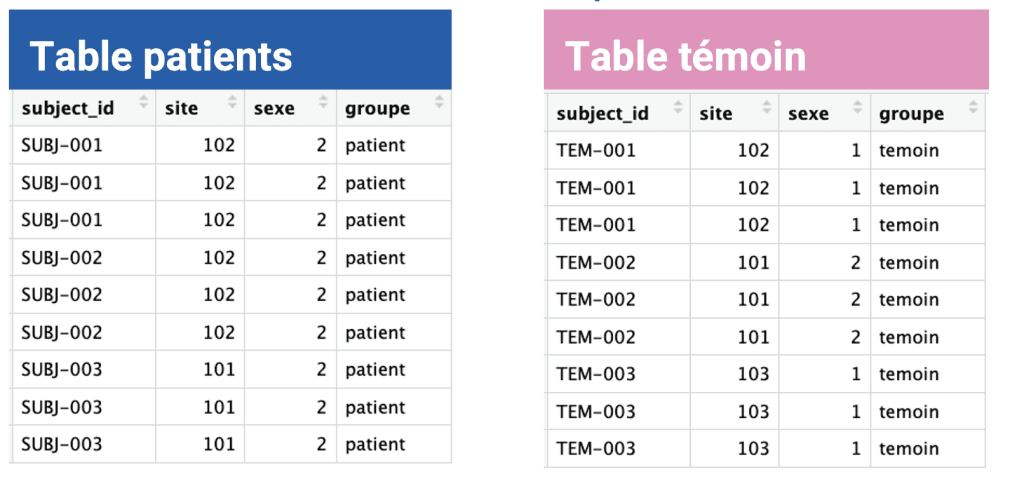
rdata_all <- patients |>
bind_rows(temoins) La fonction bind_rows() empile les lignes de la deuxième table sous celles de la première. À la différence d’une jointure, on n’ajoute pas de colonnes : on allonge la table en gardant la même structure.
Voici le résultat :
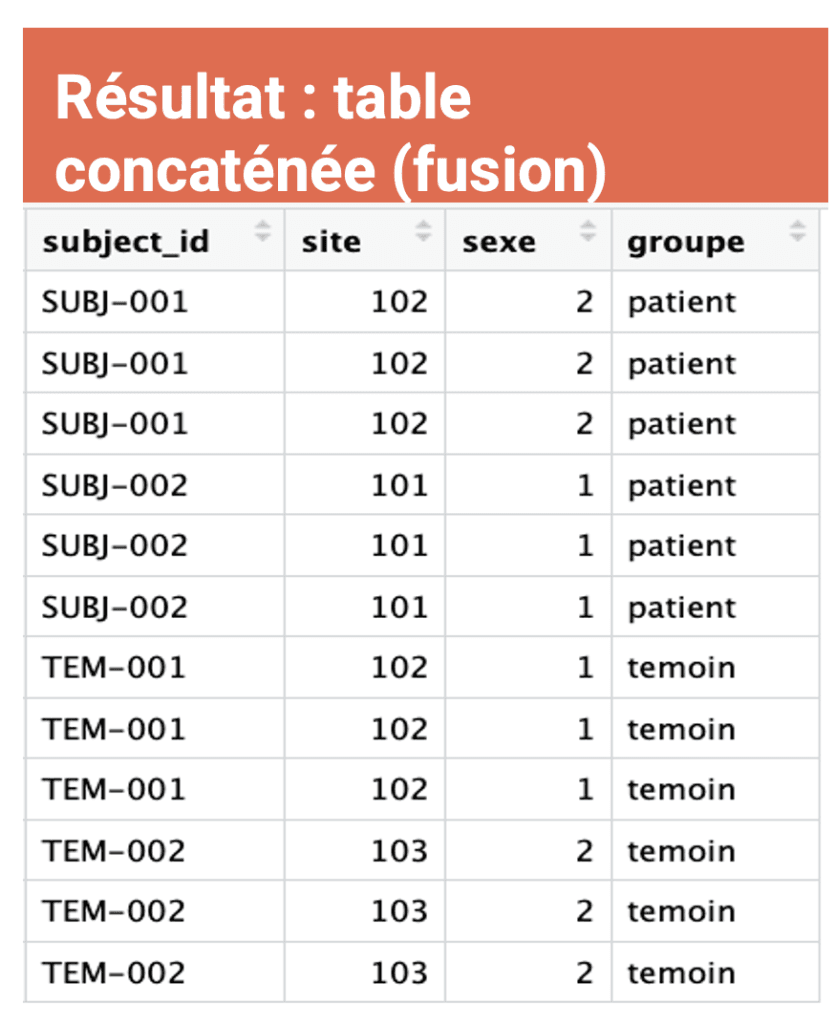
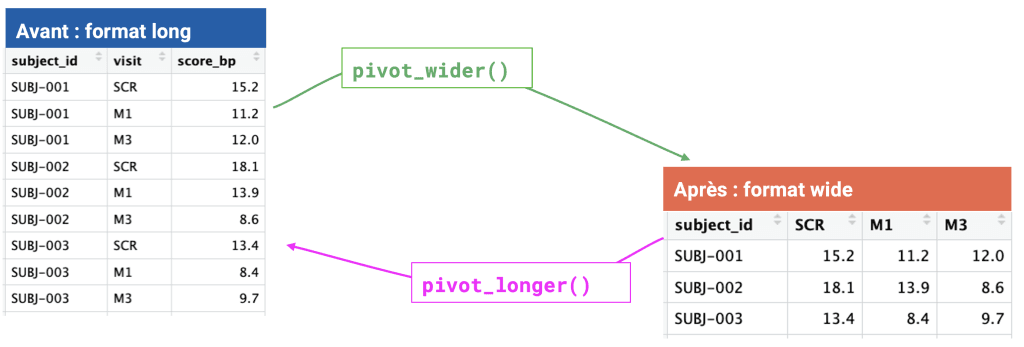
Les données cliniques sont souvent collectées en format long : une ligne par sujet × visite. Pour certaines analyses, présentations ou exports vers d’autres logiciels, on a besoin du format wide : une seule ligne par sujet, avec une colonne par visite. Le package tidyr permet de passer de l’un à l’autre en une commande. Du long au wide avec pivot_wider()
library(tidyr)
clinical_data_wide <- clinical_data_clean |>
pivot_wider(
id_cols = subject_id,
names_from = visit,
values_from = score_bp
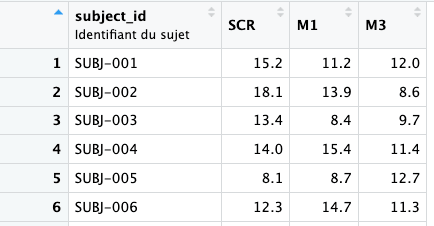
) 
Trois arguments structurent l’opération :
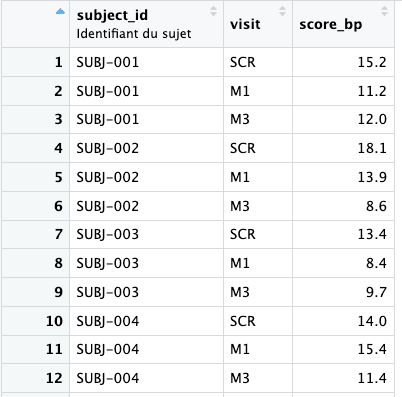
id_cols = subject_id indique la (ou les) colonne(s) qui identifient un sujet de manière unique. C’est ce qui sera conservé en ligne dans la table résultante.names_from = visit indique que les noms des nouvelles colonnes vont être prélevés dans la variable visit. Si visit contient les valeurs SCR, M1, M3, on obtiendra trois colonnes nommées SCR, M1 et M3. values_from = score_bp indique la variable dont les valeurs vont remplir les nouvelles colonnes.Résultat : une table avec une ligne par sujet, et trois colonnes correspondant aux scores à chacune des trois visites — pratique pour comparer en un coup d’œil l’évolution d’un patient.
L’opération inverse permet de revenir au format long. Utile par exemple pour produire un graphique avec ggplot2, qui fonctionne presque toujours mieux sur des données en format long.
clinical_data_long <- clinical_data_wide |>
pivot_longer(
cols = -subject_id,
names_to = "visit",
values_to = "score_bp"
) 
Trois arguments cette fois aussi :
cols = -subject_id désigne les colonnes à empiler. La syntaxe -subject_id signifie “toutes les colonnes sauf subject_id”. On peut aussi lister explicitement les colonnes à concerner (par exemple cols = c(SCR, M1, M3)).names_to = "visit" indique le nom de la nouvelle variable qui va contenir les anciens noms de colonnes (SCR, M1, M3). C’est l’inverse de names_from dans pivot_wider().values_to = "score_bp"indique le nom de la nouvelle variable qui va contenir les valeurs. C’est l’inverse de values_from.Résultat : on retrouve une table en format long (une ligne par sujet × visite), avec une colonne visit et une colonne score_bp. C’est strictement réversible ; on peut revenir au wide à tout moment avec pivot_wider().
Plus besoin de scripts complexes ou de macros SAS. Une commande, un résultat lisible, réversible avec pivot_longer() si besoin.
Pour retrouver davantage d’information sur le pivot de tables avec R, vous pouvez consulter mon article Format long vs format wide en R : comment utiliser pivot_longer sans se tromper
Pour un data manager qui produit régulièrement des livrables , Quarto est l’outil qui change le plus profondément le quotidien.
Il permet de combiner texte, code R et résultats dans un document unique, exporté en HTML, PDF ou Word. Quand vos données changent, vous relancez le document en un clic, et tout se met à jour automatiquement. Quarto est la nouvelle génération de R Markdown (.Rmd), pensée pour être plus puissante, plus flexible et multi-langages (R, Python, Julia…). Quarto est directement intégré à R Studio.
Le principe : un script .qmd
Un document Quarto est un fichier .qmd qui combine trois éléments :
Les fonctionnalités qui font gagner du temps
C’est exactement le type d’outil qu’on attend en data management : reproductible, traçable, multi-format, automatisable. Une fois qu’on l’a adopté, on ne revient plus en arrière!
L’un des freins les plus fréquents au passage à R est la crainte de la difficulté. En pratique :
Si cet article vous donne envie d’aller plus loin, je propose plusieurs formations professionnelles en distanciel, en petit groupe (environ 5 participants) :
Tarif : 1 500 € HT pour les formations de 3 jours, 500 € HT pour les ateliers d’une journée.
Certaines de ces formations sont mutualisées avec un organisme certifié Qualiopi, ce qui permet d’envisager une prise en charge par votre OPCO. Pour un format intra-entreprise ou un devis personnalisé, n’hésitez pas à me contacter.

Je suis Claire Della-Vedova, consultante en biostatistique, méthodologie clinique et expertise R.
J’accompagne les fabricants de dispositifs médicaux et les équipes scientifiques des sciences du vivant dans leurs projets d’évaluation clinique, d’analyse statistique et d’analyse de données sous R.
🎓 Formations professionnelles R et biostatistiques
🤝 Prestations et accompagnement sur mesure
📅 Discuter d’un accompagnement ou d’une prestation sur mesure

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
2 réponses
Super Clair,
J’adore vos blogs, toujours très clairs et très pédagogiques qui donnent envie de pratiquer en toute sérénité .
Je transmets ce blog à mon fils qui est data analyst dans une société en Angleterre et l’incite fortement à se former et à pratiquer ce language R .
Continuez à stimuler nos motivations .
Bien cordialement.
C’est très intéressant M. Claire et c’est gentil de votre part. Merci encore une fois