
Les heatmaps sont des outils de visualisation qui permettent de représenter un tableau de données, en appliquant une couleur par cellule, en fonction de la valeur de la variable considérée.
Ce type de graphique peut être employé dans deux situations bien distinctes. Dans la première d’entre elles, les heatmaps sont employées pour visualiser l’évolution d’un événement au cours du temps, ou à travers l’espace.
Dans le second type de situations, les heatpmap sont employées pour explorer des données et essayer de mettre en évidence des clusters d’objets (ligne) et de variables (colonnes).
Dans cet article, je vous présente en détail ces deux types de situations et comment réaliser les heatmaps correspondantes, avec R.
Les heatmaps simples sont employées pour visualiser l’évolution d’un événement au cours du temps, ou à travers l’espace. Il peut s’agir, par exemple de suivre l’évolution des températures d’un cours d’eau sur la hauteur la largeur d’un cours d’eau (grâce à un maillage de capteurs), ou encore de suivre l’évolution du prix d’une action en bourse au cours du temps.
Dans cette situation, on ne s’intéresse qu’à une seule variable (la température, ou le prix), et les données ont un ordre intrinsèque dans le tableau de données. Par exemple, pour le suivi du prix d’une action, nous pouvons avoir un tableau de 31 lignes (les jours) et 12 colonnes (les mois).

La heatmap simple consiste uniquement à mettre en couleur cette table de données pour la rendre plus intelligible :

Ce type de heatmap est employé dans un but davantage exploratoire puisqu’il s’agit d’essayer de faire apparaitre des ressemblances entre certaines lignes (objets), et entre certaines colonnes (variables) en permettant aux lignes et aux colonnes d’êtres permutées. Ces permutations sont basées sur un calcul préliminaire de similitudes (ou de distances) entre les objets d’une part, et entre les variables, d’autre part, suivi d’un clustering hiérarchique. En règle générale, et en première approche, ce sont les distances euclidiennes qui sont employées :
\[ d=\sqrt{\left(x_{2}-x_{1}\right)^{2}+\left(y_{2}-y_{1}\right)^{2}+\left(z_{2}-z_{1}\right)^{2}}\]
x, y et z sont des variables.
Dans cette situation, le tableau de données est différent de celui vu précédemment. Les colonnes correspondent à des variables de nature différentes (avec des unités et des échelles qui peuvent être très différentes), sans ordre intrinsèque. Les lignes correspondent à des sujets ou des objets et n’ont pas non plus d’ordre intrinsèque. Il peut s’agir, par exemple, de visualiser différents modèles de voitures (les objets) en fonction de différentes caractéristiques (les variables) :

Voici le type de heatmap que l’on peut réaliser avec ses donnnées :

Comme souvent avec R, il existe plusieurs packages pour réaliser des heatmaps. Celui que j’utilise actuellement c’est le package pheatmap (p pour pretty). Il possède de nombreux arguments qui permettent de contrôler assez finement l’apparence des heatmaps réalisées.
library(pheatmap) Nous allons représenter l’évolution du prix à la fermeture de l’ADA (cryptomonnaie du projet Cardino) au cours de l’année 2021. J’ai téléchargé les données sur Kaggle : https://www.kaggle.com/datasets/ranugadisansagamage/cardano-cryoto-price
Si vous voulez reproduire l’exemple, vous devez placer le fichier ADA-USD.csv dans un dossier data à la racine de votre projet R
library(tidyverse)
library(lubridate)
mydata <- read_csv("data/ADA-USD.csv")
head(mydata)
## # A tibble: 6 x 7
## Date Open High Low Close `Adj Close` Volume
## <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2017-11-09 0.0252 0.0351 0.0250 0.0321 0.0321 18716200
## 2 2017-11-10 0.0322 0.0333 0.0265 0.0271 0.0271 6766780
## 3 2017-11-11 0.0269 0.0297 0.0257 0.0274 0.0274 5532220
## 4 2017-11-12 0.0275 0.0280 0.0226 0.0240 0.0240 7280250
## 5 2017-11-13 0.0244 0.0263 0.0235 0.0258 0.0258 4419440
## 6 2017-11-14 0.0258 0.0268 0.0253 0.0262 0.0262 3033290
# je ne garde que les données de l'année 2021,
mydata21 <- mydata %>%
filter(Date>= "2021-01-01" & Date <= "2021-12-31") %>% # filtre des données de 2021
mutate(Month=month(Date, label=TRUE, abbr=TRUE),
Day=day(Date)) %>% # permet de creer des variables Day et Month (en lettre)
select(Month, Day, Close) # je ne garde que les variable Month Day et Close (prix à la fermeture)
head(mydata21)
# A tibble: 6 x 3
Month Day Close
<ord> <int> <dbl>
1 janv 1 0.175
2 janv 2 0.177
3 janv 3 0.205
4 janv 4 0.225
5 janv 5 0.258
6 janv 6 0.332
Il faut ensuite passer les données dans un format wide pour avoir les mois en colonne et les jours en ligne :
mydata21W <- mydata21 %>%
pivot_wider(
names_from=Month,
values_from=Close) %>%
column_to_rownames(var="Day")
head(mydata21W)
janv févr mars avr mai juin juil août sept oct nov déc
1 0.18 0.40 1.29 1.19 1.35 1.73 1.34 1.32 2.87 2.26 1.95 1.55
2 0.18 0.43 1.23 1.20 1.33 1.75 1.39 1.31 2.96 2.25 1.97 1.72
3 0.20 0.44 1.22 1.17 1.36 1.84 1.41 1.37 2.97 2.25 2.06 1.56
4 0.22 0.44 1.11 1.19 1.27 1.71 1.46 1.38 2.83 2.19 1.98 1.42
5 0.26 0.54 1.17 1.21 1.48 1.66 1.40 1.39 2.91 2.23 1.99 1.38
6 0.33 0.63 1.13 1.26 1.65 1.68 1.42 1.40 2.83 2.21 2.01 1.43 Nous pouvons à présent représenter les données avec une heatmap simple.
Par défaut, la fonction pheatmap() calcule des distances euclidiennes et réarrange les lignes et les colonnes pour créer des clusters.
Pour obtenir une heatmap simple (donc sans calcul des distances euclidiennes et réarrangement), il faut préciser :
cluster_cols = FALSE, etcluster_rows = FALSE.library(pheatmap)
pheatmap(mydata21W,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = FALSE,# pour ne pas faire de réarrangement de colonnes
cluster_rows = FALSE) # pour ne pas faire de réarrangement de lignes Dans cette situation, on place les objets en lignes et les variables en colonnes. Ici, nous allons employer le jeu de données mtcars sur lequel je vais seulement retirer les variables vs (Engine (0 = V-shaped, 1 = straight) et am (Transmission (0 = automatic, 1 = manual)), qui sont en réalité des variables catégorielles.
mtcars2 <- mtcars %>%
select(-am, -vs)
head(mtcars2)
## mpg cyl disp hp drat wt qsec gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 3 1 Les objets, en lignes, sont les modèles de voitures et les variables sont en colonne. Ici les modèles des voitures sont déjà en noms de lignes (rownames), c’est ce qui permettra d’obtenir le nom des modèles sur la heatmap. Si vous importez vos données, il faudra très probablement passer le nom des objets en rownames, puis supprimer la variable nom. Vous pourrez le faire comme ceci :
rownames(mydf) <- mydf$nom
mydf$nom <- NULL Pour visualiser les données, nous pouvons faire unepremière heatmap sans réarrangement :
pheatmap(mtcars2,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = FALSE,# pour ne pas faire de réarrangement de colonnes
cluster_rows = FALSE) # pour ne pas faire de réarrangement de lignes 
De nombreuses cases apparaissent en bleu, ce qui ne nous donne pas beaucoup d’informations. Le problème ici, c’est que les variables sont dans des unités et des échelles très différentes (ce que nous n’avions pas dans la heatmap simple car il s’agissait d’une seule et même variable). La palette de couleurs est construite pour des valeurs allant de 0 à plus de 400 !
Dans cette situation, il est préférable de standardiser (centrer et réduire) les données, avant de les visualiser. La standardisation permet d’obtenir des variables dans la même échelle, avec des valeurs globalement comprises entre -3 et 3.
La fonction pheatmap() contient un argument scale, qui permet de faire cette standardisation directement :
pheatmap(mtcars2,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = FALSE,# pour ne pas faire de réarrangement de colonnes
cluster_rows = FALSE, # pour ne pas faire de réarrangement de lignes
scale="column") 
C’est déjà un peu plus indicatif. Ensuite, on peut demander un réarrangement des lignes et des colonnes pour créer des clusters d’objets (ligne, ici voitures), et de variable en se basant sur les distances euclidiennes :
pheatmap(mtcars2,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = TRUE,# pour obtenir un réarrangement de colonnes
cluster_rows = TRUE, # pour obtenir un réarrangement de lignes
scale="column") 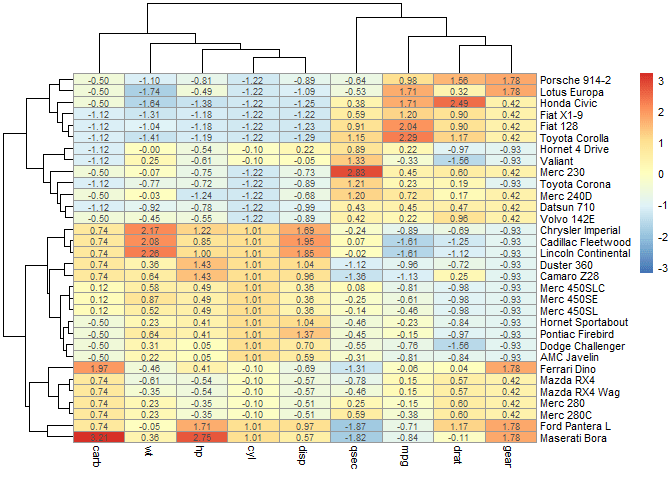
Remarque 1: La standardisation a une influence sur le calcul des distances euclidiennes. Avec la standardisation, les variables ont toutes le même poids (la même influence) dans le calcul de la distance.
Remarque 2: En employant les arguments cluster_rows = TRUE et cluster_cols = TRUE, les arguments
clustering_distance_rows= "euclidean",clustering_distance_cols = "euclidean" etclustering_method = "complete" sont aussi employés, par défaut (automatiquement)Pour vérifier, vous pouvez employer les commandes suivantes. Vous obtiendrez la même heatmap.
pheatmap(mtcars2,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = TRUE,# pour obtenir un réarrangement de colonnes
cluster_rows = TRUE, # pour obtenir un réarrangement de lignes
scale="column",
clustering_distance_rows= "euclidean",
clustering_distance_cols = "euclidean",
clustering_method = "complete"
) On peut ensuite demander de démarquer deux groupes en ligne, avec l’argument cutree_rows = 2, idem en colonne avec cutree_cols = 2:
pheatmap(mtcars2,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = TRUE,# pour obtenir un réarrangement de colonnes
cluster_rows = TRUE, # pour obtenir un réarrangement de lignes
scale="column",
clustering_distance_rows= "euclidean",
clustering_distance_cols = "euclidean",
clustering_method = "complete",
cutree_rows = 2,
cutree_cols = 2
) 
Ici on a deux clusters de voitures : celles ayant des valeurs de carb, wt, hp, cy et disp plutôt faibles et des valeurs de qsec, mpg, drat, et gear plutot élevées. Et inversement pour le second groupe.
On pourrait aussi démarquer 3 clusters :
pheatmap(mtcars2,
display_numbers = TRUE,# pour afficher les valeurs
fontsize = 8, # pour diminuer la police des valeurs
cluster_cols = TRUE,# pour obtenir un réarrangement de colonnes
cluster_rows = TRUE, # pour obtenir un réarrangement de lignes
scale="column",
clustering_distance_rows= "euclidean",
clustering_distance_cols = "euclidean",
clustering_method = "complete",
cutree_rows =3,
cutree_cols = 2
) La fonction pheatmap() permet également de réaliser des annotations. Vous trouverez des exemples
Et des exemples d’utilisations de palettes ici : https://r-charts.com/correlation/pheatmap/#color
J’espère que ce court article vous permettra de mieux comprendre les heatmaps et de les réaliser facilement, selon vos besoins, avec vos propres données.
Si vous souhaitez soutenir mon travail, vous pouvez faire un don libre sur la page tipeee du blog ;


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
Une réponse
c’est génial, très intérèssant