Dans cet article, je vais vous présenter quelques fonctions particulièrement intéressantes pour visualiser et explorer les données manquantes présentes dans un data frame, en termes de quantité (nombre ou pourcentage), de localisation, ou encore de distribution parmi les variables.
Dans cet article, je vais vous présenter quelques fonctions particulièrement intéressantes pour visualiser et explorer les données manquantes présentes dans un data frame, en termes de quantité (nombre ou pourcentage), de localisation, ou encore de distribution parmi les variables.
library(datasets)
data("airquality")
str(airquality)
'data.frame': 153 obs. of 6 variables:
$ Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$ Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ...
$ Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
$ Temp : int 67 72 74 62 56 66 65 59 61 69 ...
$ Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ... La première fonction que nous pouvons employer est la fonction `summary()`, qui renvoie, pour chaque variable, le nombre de données manquantes (NA dans R).
summary(airquality)
Ozone Solar.R Wind
Min. : 1.00 Min. : 7.0 Min. : 1.700
1st Qu.: 18.00 1st Qu.:115.8 1st Qu.: 7.400
Median : 31.50 Median :205.0 Median : 9.700
Mean : 42.13 Mean :185.9 Mean : 9.958
3rd Qu.: 63.25 3rd Qu.:258.8 3rd Qu.:11.500
Max. :168.00 Max. :334.0 Max. :20.700
NA's :37 NA's :7
Temp Month Day
Min. :56.00 Min. :5.000 Min. : 1.0
1st Qu.:72.00 1st Qu.:6.000 1st Qu.: 8.0
Median :79.00 Median :7.000 Median :16.0
Mean :77.88 Mean :6.993 Mean :15.8
3rd Qu.:85.00 3rd Qu.:8.000 3rd Qu.:23.0
Max. :97.00 Max. :9.000 Max. :31.0 aiquality comporte :Une autre fonction, également très utile, pour connaître le nombre de données manquantes et le pourcentage correspondant, pour chaque variable, est
la fonction `df_status()`, du package `funModeling`:
library(funModeling)
df_status(airquality)
variable q_zeros p_zeros q_na p_na q_inf p_inf
1 Ozone 0 0 37 24.18 0 0
2 Solar.R 0 0 7 4.58 0 0
3 Wind 0 0 0 0.00 0 0
4 Temp 0 0 0 0.00 0 0
5 Month 0 0 0 0.00 0 0
6 Day 0 0 0 0.00 0 0
type unique
1 integer 67
2 integer 117
3 numeric 31
4 integer 40
5 integer 5
6 integer 31 Nous pouvons voir que les 37 données manquantes au niveau de la variable `Ozone` correspondent à 24.18% des valeurs de cette variable `Ozone`. De même, les 7 NA de la variable `Solar.R` correspondent à 4.58%.
La fonction gg_miss_var() du package naniarpermet d’obtenir un graphique synthétique avec le nombre de données manquantes (ou le pourcentage) pour chaque variable :
library(naniar)
gg_miss_var(airquality) 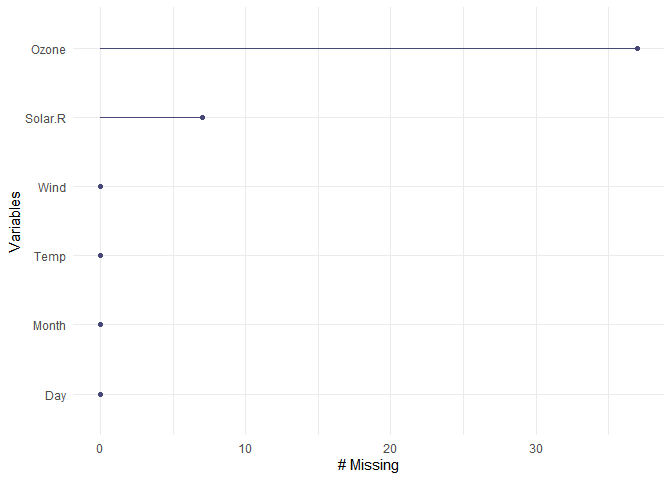
Pour obtenir les pourcentages correspondants, il suffit d’employer l’argument show_pct = TRUE:
gg_miss_var(airquality,show_pct = TRUE) 
Pour cela, nous pouvons employer les fonctions vis_dat() du package visdat:
library(visdat)
vis_dat(airquality) 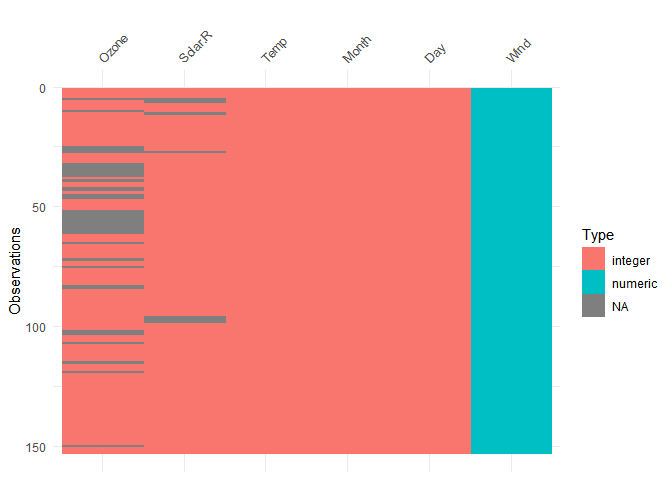
Pour obtenir les positions précises nous pouvons employer les fonction which() et is.na(), comme ceci :
which(is.na(airquality$Ozone))
[1] 5 10 25 26 27 32 33 34 35 36 37 39
[13] 42 43 45 46 52 53 54 55 56 57 58 59
[25] 60 61 65 72 75 83 84 102 103 107 115 119
[37] 150
which(is.na(airquality$Solar.R))
[1] 5 6 11 27 96 97 98 Ces positions sont cohérentes avec celles représentées sur le plot, précédemment.
Un autre plot, peut également être réalisé avec la fonction vis_miss(), qui permet de connaître à la fois la position des données manquantes et le pourcentage qu’elles représentent :
visdat::vis_miss(airquality) 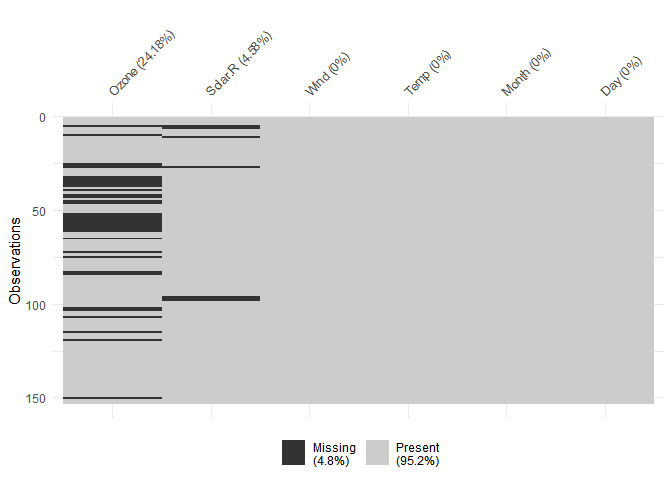
Le package `naniar` dispose d’une fonction particulièrement intéressante pour étudier les relations entre les NA des différentes variables : la fonction `gg_miss_upset()`.
Cette fonction permet de réaliser un graphique qui illustre le nombre de NA partagées par plusieurs variables
naniar::gg_miss_upset(airquality)
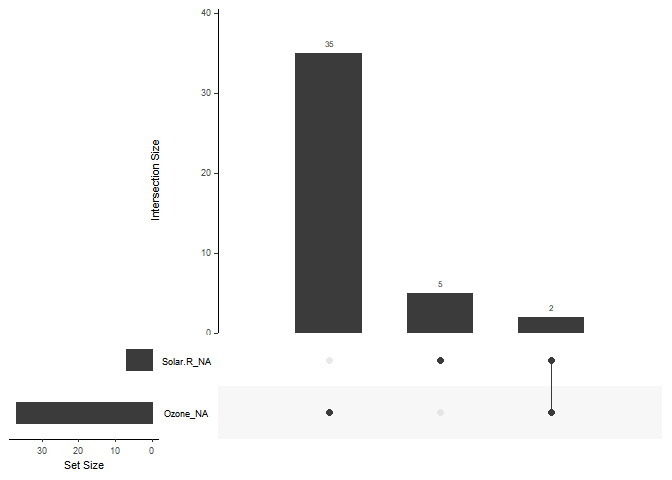
Par exemple, ici, nous pouvons voir que parmi les 37 observations qui ne disposent pas de données pour la variable Ozone, autrement dit qui sont de données manquantes, deux le sont aussi pour la variable Solar.R.
geom_miss_point() du package ggplot2.ggplot(airquality, aes(y = Ozone, x = Solar.R))+
geom_point(width=0.1, height=0.1) +
geom_miss_point() 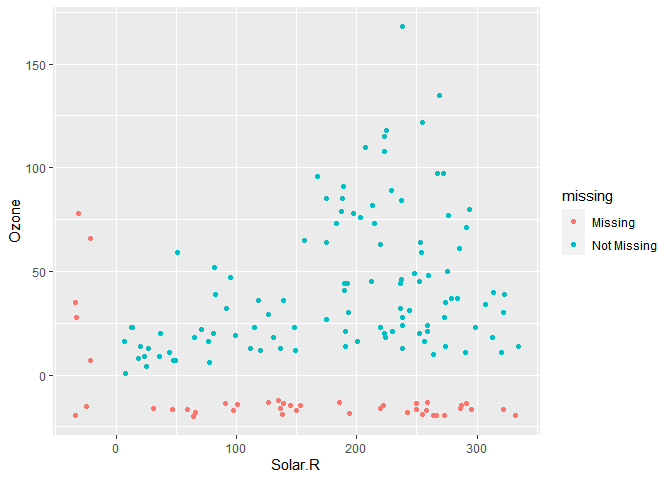
A gauche, en rouge, nous pouvons voir la représentation des 7 NA de la variable `Solar.R`. Et en bas, également, en rouge, la représentation des 37 données manquantes de la variable `Ozone`. Les deux données dans l’angle inférieur gauche sont les deux NA, conjointement présentes dans les variables `Solar.R`et `Ozone`.
Vous trouverez plus d’informations sur les packages visdat et naniar ici, et là.
Et vous, quelles fonctions employez vous pour explorer les NA de vos jeux de données? Partagez les en commentaire ?
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
10 réponses
Bonjour
Merci pour ce blog très bien fait et bien utile. Après ce papier sur la visualisation des données manquantes, pourriez-vous nous expliquer les différentes possibilités de remplacer les valeurs manquantes, en particulier dans le cas des variables qualitatives ?
Merci à vous, et avec mon soutien
Vous nous donnez d’excellents cours à travers ce grand logiciel R, et mieux, vous nous encouragez à en faire notre quotidien.
Merci beaucoup Claire. C’est très édifiant !
Bonjour. Merci pour l’article! J’avais justement un problème de données manquantes!
Est-ce que l’image de l’article (le Monsieur à la loupe) est libre d’utilisation, s’il-vous-plaît?
Oui l’image est libre.
Bonne continuation.
Pour savoir si je peux l’utiliser aussi. Merci.
Merci Claire, Très bon article que l’on doit voir avant de faire les stats descriptives et autres analyses
Merci pour votre clairvoyance. Je vous felicite
Merci d’aborder le sujet. Cependant j’ai du mal a comprendre comment conclure a partir de ces graphs si il s’agit de donnee manquante de type MCAR , MAR ou MNAR? Que nous apprend le dernier graph avec la fonction geom_miss_ point?
Bonjour,
je connais mal le sujet des MCAR, MAR et MNAR, je ne sais donc pas si les graph permettent de conclure définitivement sur le type de données manquantes.
POur ce qui du graph geom_miss_point, il permet néanmoins d’appréhender la distribution des données manquantes (en termes de valeurs de la seconde variable). Par exemple, on voit que les valeurs Solar. R des 36 données qui ont une valeur manquante pour l’ozone, sont globalement assez bien réparties. Elles ne correspondent pas à un groupe de valeurs spécifiques (hautes ou basses par exemple).
J’espère que cela vous aide.
Bonne continuation