
Au programme
Voici quelques sujets qui ont retenu mon attention ces dernières semaines : une mise à jour notable de RStudio, une extension Quarto pour intégrer des diagrammes, et deux lectures autour de l’évaluation normalité et des études pilotes.
🚀 RStudio Desktop (v2026.05) : améliorations importantes de la visionneuse des données
La version 2026.05 de RStudio Desktop (nom de code « Golden Wattle ») apporte une mise à jour importante de la visionneuse des données (View()).
La visionneuse gagne considérablement en fluidité et s’enrichit de nouvelles fonctionnalités interactives pour explorer les tableaux de données directement depuis l’IDE.
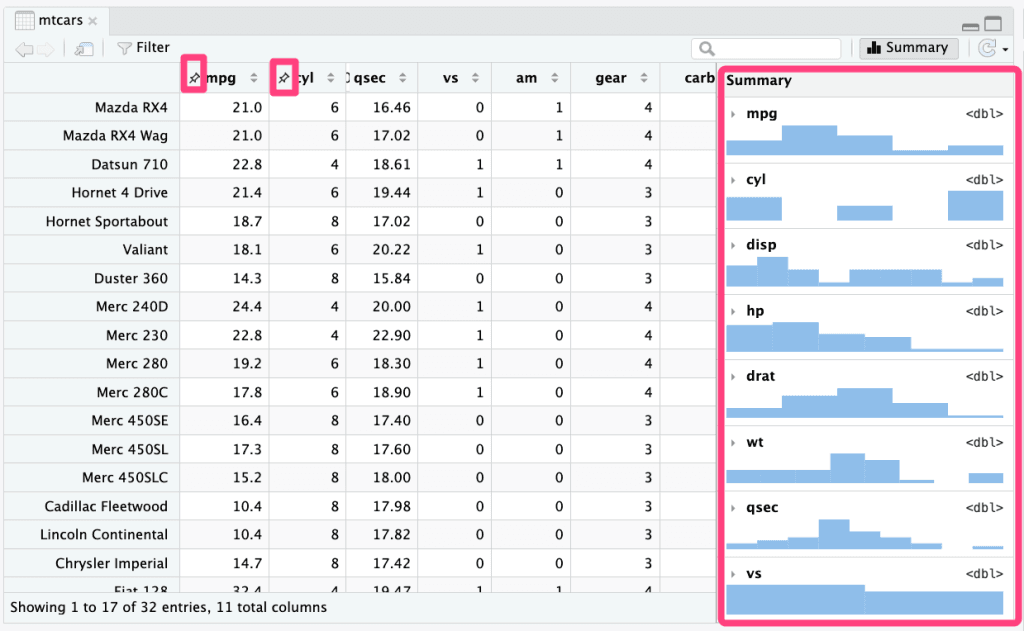
📌 Les grandes nouveautés de la visionneuse de données
- Blocage et épinglage des colonnes (Pinnable columns) : fini le défilement horizontal qui fait perdre de vue l’essentiel. Il est désormais possible de « fixer » une ou plusieurs colonnes (comme un identifiant ou un nom de variable) sur le côté gauche de l’écran. Elles restent ainsi visibles en permanence pendant la navigation dans le reste du tableau.
- Panneau de description et statistiques dynamiques : un nouveau volet latéral fait son apparition, avec des mini-histogrammes (sparklines) pour visualiser immédiatement la distribution des données.
- Affichage augmenté : le visualiseur gère mieux les grands volumes et permet désormais d’afficher jusqu’à 200 colonnes simultanément (contre 50 auparavant), sans aucune perte de fluidité.
Pour découvrir l’intégralité des corrections et des améliorations de cette version, vous pouvez consulter les Release Notes officielles de Posit.
Si vous débutez avec R et RStudio, je reprends tout cela pas à pas dans ma formation vidéo Bien démarrer avec R et RStudio.
▶️ Intégrer des diagrammes dans Quarto
Toujours dans l’écosystème R/Quarto, voici une extension bien pratique pour illustrer vos documents.
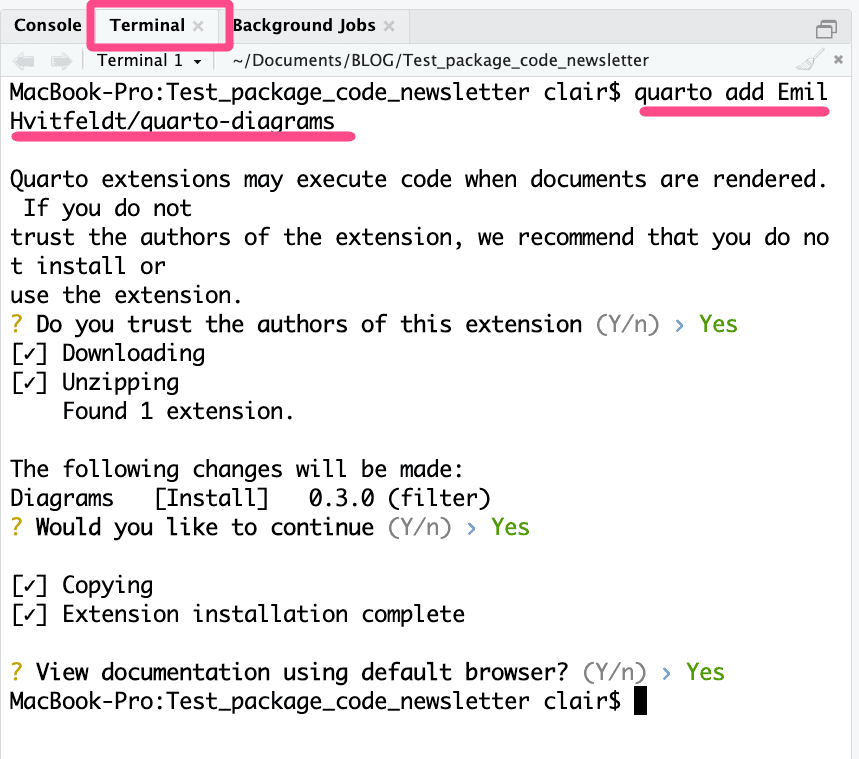
L’intégration des diagrammes est possible via une extension développée par Emil Hvitfeldt.
Vous retrouverez des informations sur cette extension sur ces pages :
- https://emilhvitfeldt.com/post/quarto-diagrams/
- https://github.com/EmilHvitfeldt/quarto-diagrams#readme
L’extension doit être installée dans un projet R, depuis le terminal, en utilisant la commande quarto add EmilHvitfeldt/quarto-diagrams.
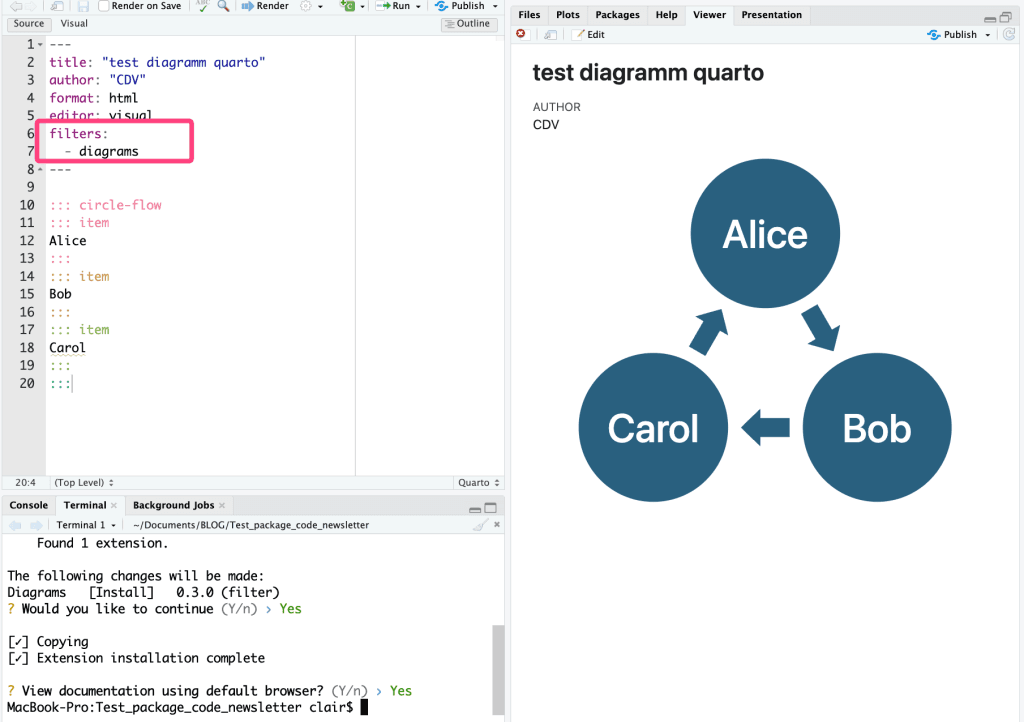
Il est ensuite nécessaire d’ajouter l’élément suivant dans l’en-tête YAML du document Quarto :
yaml
filters:
- diagramsIl vous suffit ensuite d’employer les éléments qui correspondent aux différents diagrammes, et que vous trouverez sur les pages citées précédemment. Par exemple :
::: {.circle-flow node-color="#41516C"}
::: item
Plan
:::
::: item
Build
:::
::: item
Ship
:::
:::
Liste des diagrammes disponibles
🔍 Evaluer la normalité : les limites du test de Shapiro-Wilk
Côté méthode, un mot sur un réflexe très répandu : utiliser un test statistique pour vérifier la condition de normalité (des données ou des résidus) avant un test de comparaison de moyennes ou une régression. Le test de Shapiro-Wilk est le plus employé dans ce but. Mais il est souvent mal interprété.
Une publication récente résume bien ce problème bien connu :
Shatz, I. (2024). Assumption-checking rather than (just) testing: The importance of visualization and effect size in statistical diagnostics. Behavior Research Methods, 56(2), 826-845.https://pubmed.ncbi.nlm.nih.gov/36869217/
Voici ce qu’il faut en retenir.
Le test ne répond pas à la question qu’on se pose
Ses hypothèses sont :
- H0 : les données sont compatibles avec une loi normale ;
- H1 : les données ne le sont pas.
Avec le seuil habituel de 5 %, une p-value inférieure à 0,05 conduit à rejeter H0 : on conclut à une non-normalité, avec un risque d’erreur contrôlé à 5 %.
Une p-value supérieure à 0,05, en revanche, ne prouve pas la normalité. Elle signifie seulement qu’on n’a pas mis en évidence d’écart significatif. Le risque de conclure à tort à la normalité, lui, n’est pas contrôlé.
Le test cherche donc des preuves de non-normalité ; il ne démontre jamais la normalité. Or c’est souvent l’inverse qu’on voudrait montrer : que les données sont assez proches d’une loi normale, avec un bon niveau de confiance (95 %, par exemple). Le Shapiro-Wilk ne répond pas à cette question.
Le résultat dépend beaucoup de l’effectif
- Sur un petit échantillon, le test manque de puissance : il détecte mal les écarts à la normalité et ne rejette presque jamais H0.
- Sur un grand échantillon, c’est l’inverse : il devient si sensible qu’il repère des écarts minimes, sans portée pratique, et rejette H0 même quand la distribution paraît très normale.
Conséquence : plus l’effectif est faible, plus il est « facile » de ne pas rejeter la normalité. Mais cette absence de rejet traduit surtout le manque de puissance du test, pas une vraie normalité.
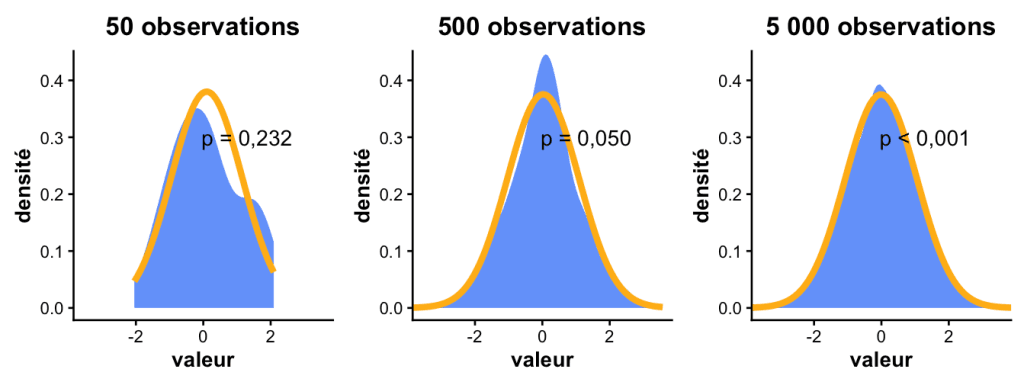
Il peut passer à côté de certaines formes de non-normalité
Même à effectif donné, le test ne repère pas toujours une distribution pourtant clairement non normale, surtout quand l’effectif est limité. Une distribution bimodale ou bruitée peut très bien donner une p-value supérieure à 0,05. Là encore, ne pas rejeter H0 n’est pas une preuve de normalité.
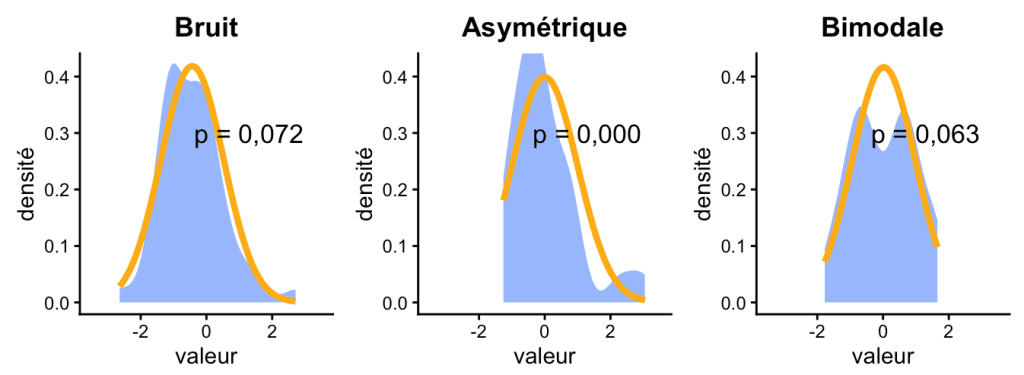
En pratique
Mieux vaut ne pas s’en remettre au seul Shapiro-Wilk. On gagne à compléter par une inspection graphique (histogramme, courbe de densité, QQ-plot) et par une réflexion sur l’importance pratique des écarts observés.
J’aborde ces notions dans mes formations de biostatistiques appliquées : Fondamentaux et tests statistiques usuels avec R ou avec Jamovi
🔬 À propos de l’article A Brief Overview of Pilot Studies and Their Sample Size Justification
Pour finir, une lecture côté méthodologie clinique : comment penser, et dimensionner une étude pilote.
Voici ce qui a retenu mon attention.
Étude pilote : ce qu’il faut retenir avant de dimensionner l’essai principal
Une étude pilote n’est pas un essai confirmatoire. Elle n’est pas pilotée par les tests d’hypothèse : pas de calcul de puissance formel, pas de logique « p-value ». L’analyse repose sur des statistiques descriptives (moyennes, écarts-types, quantiles, fréquences) et sur la précision des estimations, c’est-à-dire la largeur des intervalles de confiance.
Pour justifier la taille d’échantillon d’une étude pilote, trois approches :
- par la précision : par exemple l’IC à 95 % d’une proportion pour un critère binaire (taux de rétention, adhérence au protocole). Viser 90 % de rétention avec une marge de 5 % demande ainsi 36 participants ;
- par les règles empiriques : 12 à 35 sujets par groupe pour un critère continu, 60 à 100 par groupe pour un critère binaire ;
- par les règles d’effectif indexées sur la taille d’effet (d de Cohen). Si la différence minimale cliniquement pertinente (MCID) est connue à l’avance, on peut estimer la taille de l’effet attendu pour l’étude finale (le d de Cohen) : d = MCID / sd. Des grilles de correspondance permettent alors de choisir l’effectif de la pilote en fonction de ce palier. Par exemple, pour un effet moyen, la littérature recommande un palier à 15 sujets par bras.
Pour dimensionner l’essai principal à partir du pilote, deux pièges classiques :
- ne pas reprendre la taille d’effet observée dans le pilote : sur un petit effectif, elle est très souvent surestimée ce qui conduira à un essai principal sous-dimensionné. Mieux vaut s’appuyer sur la différence minimale cliniquement importante (MCID) ;
- ne pas reprendre l’écart-type observé tel quel : il est fréquemment sous-estimé. Une proposition consiste à utiliser la borne supérieure de l’IC à 80 % de l’écart-type, et à compléter par des analyses de sensibilité (tester une plage de tailles d’échantillon plausibles).
Pour finir
C’est tout pour cette édition. Si l’un de ces sujets vous intéresse ou que vous souhaitez aller plus loin, n’hésitez pas à laisser un commentaire et à me dire quels thèmes vous aimeriez retrouver dans les prochaines veilles.



Bonjour Claire,
C’est Philippe, je voulais te dire que j’adore ce format de « Veille Della Data » je suis très heureux que tu reprennes ça même si j’imagine le boulot en amont que ça doit demander…
C’est extrèmement pratique pour des basic users comme moi et je t’en remercie !
Amicalement
Philippe (complètement converti à Quarto… ;-))
Bonjour Philippe,
Merci pour ton message. Oui c’est du travail, mais j’ai essayé de m’organiser pour que cela soit le plus fluide possible. Je prends moi aussi beaucoup de plaisir à explorer, tester, et synthétiser pour le partager aux « basic users » comme tu dis.
Bien à toi
Bonjour,
Ce format est effectivement excellent
Merci pour tout votre travail
Bonjour Claire,
Juste un grand merci pour ce travail de veille et d’information.
J’apprécie votre esprit de synthèse ainsi que la précision et la diversité des vos informations et de vos tests.
J’apprends beaucoup sur vos différents supports.
Bien amicalement,
Fabrice
Bonjour Fabrice,
Merci beaucoup pour votre message, qui me fait très plaisir.
Je suis heureuse de voir que ce travail de veille vous est utile et qu’il vous permet de découvrir de nouveaux outils et usages. C’est précisément l’objectif : explorer, tester, puis en partager une synthèse aussi claire et pratique que possible.
Merci encore pour votre fidélité et pour ce retour encourageant.
Bien cordialement,
Claire
Bonjour,
Merci pour ce format très instructif !
Antoine
Bonjour Claire,
Toujours un réel plaisir de vous lire. Merci
Bonjour Claire,
Merci pour ce travail de veille régulier.
C’est très précieux ! En quelques minutes, on peut intégrer des nouveautés ou des astuces bien utiles dans les développements au quotidien !
Pour citer un sujet qui m’intéresse: avez-vous déjà développer quelque chose avec DT et shiny pour publier en ligne des tableaux, graphes interactifs ? Peut-être un sujet à traiter si vous avez cette expertise.