
Si vous utilisez déjà R, vous avez probablement entendu parler du package dplyr. C’est aujourd’hui un outil incontournable pour la manipulation des données : filtrer, transformer, résumer ou encore créer de nouvelles variables.
Si vous débutez avec ce package ou si vous souhaitez revoir les bases, je vous invite à consulter mon article dédié au sujet dans lesquels je présente les fonctions essentielles pour bien démarrer : « Manipulations de données avec le package dplyr »
Manipulations de données avec le package dplyr
En février 2026, une nouvelle version de dplyr (1.2.0) a été publiée, (rapidement suivie d’une mise à jour en version 1.2.1). Cette version apporte plusieurs nouveautés intéressantes, notamment autour des fonctions de filtrage et de recodage.
Je les ai testées dans différents cas d’usage, et je vous propose dans cet article un retour d’expérience, avec des exemples simples pour comprendre ce qu’elles apportent concrètement et dans quels cas elles peuvent vraiment être utiles.
Avant de découvrir ces nouveautés, pensez à vérifier que vous utilisez bien cette version récente du package dplyr, et à le mettre à jour si nécessaire.
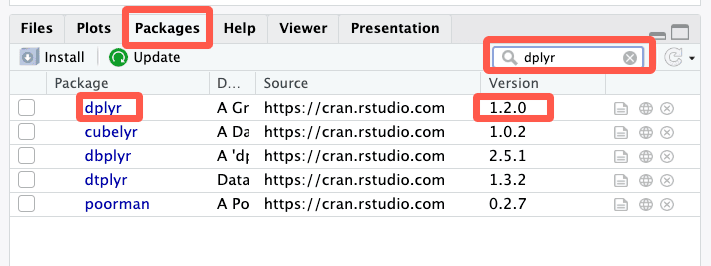
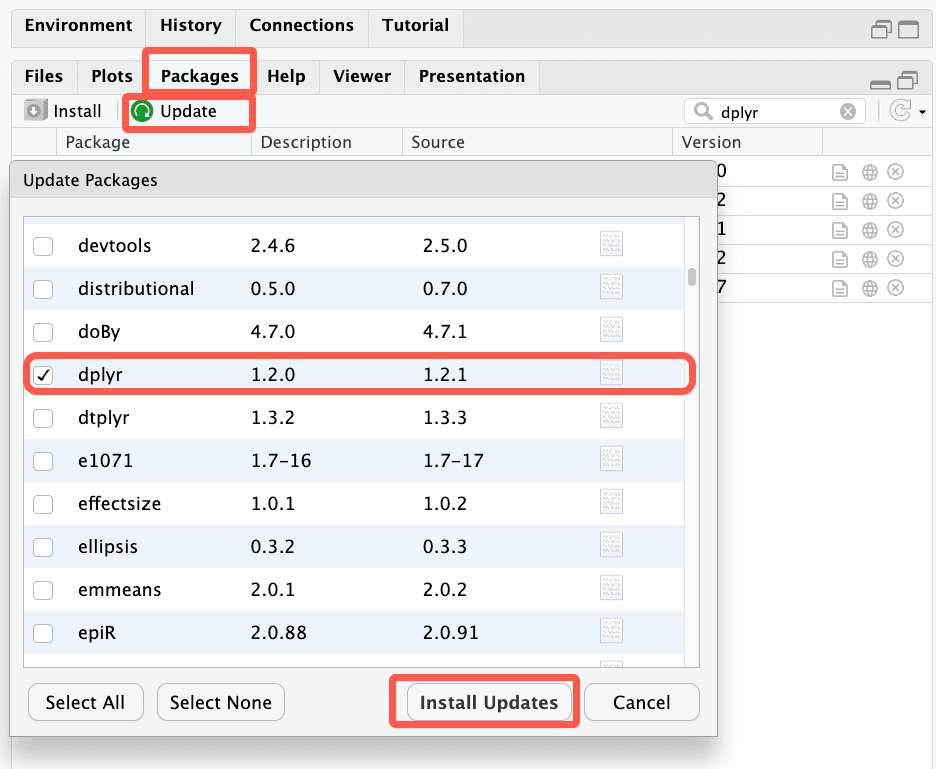
Si votre version est antérieure, vous pouvez la mettre à jour en allant dans l’onglet packages et le sous onglet update, puis en cochant la case correspondant au pcakage dplyr puis en cliquant sur le bouton Install Updates.
Les nouvelles fonctionnnalités s’articulent principalement autour de deux axes:
l’extension de la fonction de filtre filter() avec l’apparition de filter_out(), ainsi que des fonction when_any() et when_all()
l’extension de la fonction de recodage case_when() avec l’apparition des fonctions replace_when(), recode_values(), replace_values()
Ces nouvelles fonctions ne révolutionnent pas complètement la manière de manipuler les données, mais elles permettent d’écrire un code plus lisible et plus proche de l’intention que l’on souhaite exprimer.
La fonction filter_out() est une nouvelle fonction qui permet de supprimer des lignes en raisonnant directement en termes de lignes à exclure, plutôt que d’utiliser une condition négative avec la fonction filter().
Pour illustrer son utilisation, prenons un exemple simple à partir des 10 premières lignes du jeu de données airquality (directement disponible dans R) :
# ouverture du package
library(dplyr)
# creation du data frame
mydata <- airquality |>
slice_head(n=10)
# affichage
mydata
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10 Avec la fonction filter(), pour supprimer toutes les lignes qui ont une valeur de Solar.E supérieur à 100, nous devons écrire une condition “inverse”, c’est-à-dire indiquer ce que l’on souhaite conserver :
mysubset1 <- mydata |>
filter(Solar.R <= 100)
mysubset1
Ozone Solar.R Wind Temp Month Day
1 19 99 13.8 59 5 8
2 8 19 20.1 61 5 9 On raisonne donc en opposition, ce qui peut parfois être un peu moins intuitif.
Avec la nouvelle fonction filter_out(), nous pouvons directement dire ce que nous souhaitons exclure (ici les lignes qui ont une valeur de Solar.E supérieur à 100).
mysubset2 <- mydata |>
filter_out(Solar.R > 100)
mysubset2
Ozone Solar.R Wind Temp Month Day
1 NA NA 14.3 56 5 5
2 28 NA 14.9 66 5 6
3 19 99 13.8 59 5 8
4 8 19 20.1 61 5 9 Cette écriture est plus naturelle, car elle correspond directement à l’intention : supprimer certaines lignes.
Un autre aspect intéressant concerne la gestion des valeurs manquantes (NA) :
filter() :les lignes contenant des NA dans Solar.R ne sont pas conservéesfilter_out() : ces lignes sont conservées par défautCe comportement est plutôt protecteur, car il évite de supprimer des données sans s’en rendre compte. On peut ensuite décider explicitement de supprimer les NA si nécessaire.
Pour obtenir le même résultat avec filter(), il faut écrire :
mysubset1bis <- mydata |>
filter(Solar.R <= 100 | is.na(Solar.R ))
mysubset1bis
Ozone Solar.R Wind Temp Month Day
1 NA NA 14.3 56 5 5
2 28 NA 14.9 66 5 6
3 19 99 13.8 59 5 8
4 8 19 20.1 61 5 9 La fonction filter_out() fonctionne également avec les variables qualitatives.
Prenons un exemple avec le jeu de données iris, en conservant seulement deux observations par espèce :
# création d'un subset d'iris avec 2 lignes pour chaque espèce
my_iris <- iris |>
slice(1,2, 51,52, 101, 102)
my_iris
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 7.0 3.2 4.7 1.4 versicolor
4 6.4 3.2 4.5 1.5 versicolor
5 6.3 3.3 6.0 2.5 virginica
6 5.8 2.7 5.1 1.9 virginica Si l’on souhaite supprimer les lignes correspondant à l’espèce “setosa” :
filter() : nous devons dire que nous souhaitons garder “tout ce qui n’est pas setosa” avec l’opérateur != (toujours le raisonnement en opposition):tmp <- my_iris |>
filter(Species != "setosa")
tmp
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.0 3.2 4.7 1.4 versicolor
2 6.4 3.2 4.5 1.5 versicolor
3 6.3 3.3 6.0 2.5 virginica
4 5.8 2.7 5.1 filter_out(), nous pouvons directement exprimer que nous souhaitons supprimer ces lignes, comme ceci :tmp2 <- my_iris |>
filter_out(Species == "setosa")
tmp2
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.0 3.2 4.7 1.4 versicolor
2 6.4 3.2 4.5 1.5 versicolor
3 6.3 3.3 6.0 2.5 virginica
4 5.8 2.7 5.1 Pour ma part, cette fonction filter_out() est validée.
Elle permet d’écrire un code plus naturel et plus proche de notre manière de raisonner, tout en évitant certaines erreurs, notamment liées aux valeurs manquantes.
Je pense donc l’intégrer à mes routines et à mes formations sur la manipulation des données :
Formation – Manipulations_dplyr
Formation – R-Data-analyse
Les fonctions when_any() et when_all() sont deux nouvelles fonctions qui permettent de simplifier l’écriture de conditions multiples dans des fonctions comme filter() ou filter_out().
Jusqu’à présent, lorsque l’on voulait combiner plusieurs conditions, on utilisait :
| pour dire “au moins une condition est vraie” (c’est une combinaison de conditions de type OU)& pour dire “toutes les conditions sont vraies” (c’est une combinaison de conditions de type ET)Cela fonctionne très bien, mais lorsque les conditions deviennent longues ou nombreuses, le code peut devenir un peu difficile à lire.
Les fonctions when_any() et when_all() permettent d’améliorer la lisibilité du code dans ces situations :
when_any() s’utilise lorsque nous souhaitons qu’au moins une condition soit vraie (équivalent de |).when_all() lorsque nous souhaitons que toutes les conditions sont vraies (équivalent de &).Pour illustrer l’utilisation de la fonction when_any(), nous allons sélectionner les lignes du data frame airquality correspondant à au moins une des situations suivantes :
Nous sommes ici dans une situation avec plusieurs conditions de type OU, chacune combinant également des conditions de type ET
Avec l’approche classique nous écrivons :
mysubset3 <- airquality |>
filter(
(Solar.R > 150 & Temp > 70) |
(Wind < 10 & Temp > 80) |
(Solar.R > 200 & Wind < 8)
)
mysubset3
Ozone Solar.R Wind Temp Month Day
1 11 320 16.6 73 5 22
2 45 252 14.9 81 5 29
3 115 223 5.7 79 5 30
4 37 279 7.4 76 5 31
5 NA 286 8.6 78 6 1
6 NA 287 9.7 74 6 2
7 NA 186 9.2 84 6 4
- - - - - - - - - - - - - - - - - - -
85 28 238 6.3 77 9 13
86 46 237 6.9 78 9 16
87 16 201 8.0 82 9 20
88 14 191 14.3 75 9 28 Ici, cela reste lisible, mais la présence de plusieurs parenthèses et des opérateurs | rend la lecture un peu moins fluide.
Avec la fonction when_any() :
mysubset4<- airquality |>
filter(
when_any(
Solar.R > 150 & Temp > 70,
Wind < 10 & Temp > 80,
Solar.R > 200 & Wind < 8
)
)
mysubset4
Ozone Solar.R Wind Temp Month Day
1 11 320 16.6 73 5 22
2 45 252 14.9 81 5 29
3 115 223 5.7 79 5 30
4 37 279 7.4 76 5 31
5 NA 286 8.6 78 6 1
6 NA 287 9.7 74 6 2
- - - - - - - - - - - - - - - - - - -
85 28 238 6.3 77 9 13
86 46 237 6.9 78 9 16
87 16 201 8.0 82 9 20
88 14 191 14.3 75 9 28 Le changement n’est pas spectaculaire, mais chaque condition apparaît plus clairement séparée. L’instruction est globalement plus lisible, et il me semble que la logique de type “OU” se comprend plus facilement.
La fonction when_all() fonctionne sur le même principe que when_any(), mais elle s’utilise lorsque l’on souhaite que toutes les conditions soient vérifiées en même temps (équivalent de &)
Pour illustrer son utilisation, nous allons sélectionner les lignes pour lesquelles toutes les conditions suivantes sont vérifiées :
Avec l’approche classique :
mysubset5 <- airquality |>
filter(
(between(Solar.R, 150, 300) & !is.na(Solar.R)) &
(between(Temp, 75, 95) & Month %in% c(6, 7, 8)) &
(between(Wind, 5, 15) & Day <= 20)
)
mysubset5
Ozone Solar.R Wind Temp Month Day
1 NA 286 8.6 78 6 1
2 NA 186 9.2 84 6 4
3 NA 220 8.6 85 6 5
4 NA 264 14.3 79 6 6
5 NA 273 6.9 87 6 8
6 71 291 13.8 90 6 9
- - - - - - - - - - - - - - - - - - -
27 28 273 11.5 82 8 13
28 65 157 9.7 80 8 14
29 31 244 10.9 78 8 19
30 44 190 10.3 78 8 20 Avec la fonction when_all():
mysubset6 <- airquality |>
filter(
when_all(
between(Solar.R, 150, 300) & !is.na(Solar.R),
between(Temp, 75, 95) & Month %in% c(6, 7, 8),
between(Wind, 5, 15) & Day <= 20
)
)
mysubset6
Ozone Solar.R Wind Temp Month Day
1 NA 286 8.6 78 6 1
2 NA 186 9.2 84 6 4
3 NA 220 8.6 85 6 5
4 NA 264 14.3 79 6 6
5 NA 273 6.9 87 6 8
6 71 291 13.8 90 6 9
- - - - - - - - - - - - - - - - - - -
27 28 273 11.5 82 8 13
28 65 157 9.7 80 8 14
29 31 244 10.9 78 8 19
30 44 190 10.3 78 8 20 Là encore, la différence n’est pas radicale, mais chaque condition apparaît plus clairement séparée. L’instruction reste lisible, et nous comprenons plus facilement qu’il s’agit d’une combinaison de type “et”.
L’amélioration apportée par ces deux nouvelles fonctions n’est pas toujours spectaculaire, surtout sur des cas simples. En revanche, elles permettent de mieux comprendre la logique du filtre : on identifie plus facilement les « ou » et les « et ».
Au final, il me semble que l’intérêt de when_any() et when_all()repose sur un compromis entre le coût de changement et le gain en lisibilité. Pour les débutants, elles peuvent faciliter la compréhension des conditions. Pour les utilisateurs plus expérimentés, le bénéfice peut paraître plus limité au regard des habitudes déjà en place.
En plus de la fonction case_when(), 3 nouvelles fonctions font leur apparition : replace_when(), recode_values(), replace_values().
Ces fonctions s’inscrivent dans la continuité de case_when(), mais chacune répond à un besoin un peu différent :
case_when() permet de créer une nouvelle variable à partir de conditions.replace_when() permet de modifier les valeurs d’une variable existante en fonction de conditions, sans avoir à la recréer entièrement.recode_values() permet de créer une nouvelle variable en remplaçant des valeurs par d’autres, sans utiliser de conditions mais en définissant directement une correspondance entre valeurs.replace_values() permet de modifier certaines valeurs d’une variable existante en utilisant une correspondance entre valeurs, tout en conservant les autres valeurs inchangées.Posit à publier un petit tableau récapitulatif :

Dans la plupart des cas, les opérations réalisées avec replace_when(), recode_values() ou replace_values() pourraient également être effectuées avec case_when(). Cependant, ces nouvelles fonctions permettent d’écrire un code plus simple, plus lisible et surtout plus proche de l’intention réelle : modifier une variable existante ou remplacer certaines valeurs, plutôt que de reconstruire entièrement la variable.
Avant de découvrir ces nouvelles fonctions, revenons brièvement sur le fonctionnement de case_when(), qui reste la fonction de référence pour écrire des conditions en dplyr.
La fonction case_when() permet de créer une nouvelle variable à partir de plusieurs conditions.
Elle est particulièrement utile lorsque nous souhaitons créer une nouvelle variable, notamment une variable catégorielle, à partir de règles logiques.
Le principe est simple : on définit une série de conditions, et pour chacune, on précise la valeur à attribuer lorsqu’elle est vérifiée. Pour chaque ligne du jeu de données, ces conditions sont ensuite testées dans l’ordre où elles apparaissent dans le code. Dès qu’une condition est vraie, la valeur correspondante est attribuée, et les conditions suivantes ne sont plus évaluées. Et, si aucune condition n’est vérifiée pour une ligne donnée, alors la valeur retournée est NA (mais on peut le modifier).
Reprenons notre jeu de données constitué des 10 premières lignes du dataset airquality, en ajoutant une donnée manquante sur la température de la première ligne :
library(dplyr)
mydata <- airquality |>
slice_head(n = 10)
mydata$Temp[1] <- NA
mydata
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 NA 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10 Nous allons créer une nouvelle variable temp_cat qui catégorise la température (Temp) en trois groupes :
Temp < 60Temp est entre 60 et 70Temp > 70mydata7 <- mydata |>
mutate(
temp_cat = case_when(
Temp < 60 ~ "froid",
Temp <= 70 ~ "tempéré",
Temp > 70 ~ "chaud"
)
)
mydata7
Ozone Solar.R Wind Temp Month Day temp_cat
1 41 190 7.4 NA 5 1 <NA>
2 36 118 8.0 72 5 2 chaud
3 12 149 12.6 74 5 3 chaud
4 18 313 11.5 62 5 4 tempéré
5 NA NA 14.3 56 5 5 froid
6 28 NA 14.9 66 5 6 tempéré
7 23 299 8.6 65 5 7 tempéré
8 19 99 13.8 59 5 8 froid
9 8 19 20.1 61 5 9 tempéré
10 NA 194 8.6 69 5 10 tempéré Il est important de comprendre que l’ordre des conditions à une importance. Par exemple, si vous écrivez :
mydata8_bad <- mydata |>
mutate(
temp_cat = case_when(
Temp <= 70 ~ "tempéré",
Temp < 60 ~ "froid"
)
) La condition Temp < 60 ne sera jamais utilisée, car elle est déjà incluse dans Temp <= 70.
mydata8_bad
Ozone Solar.R Wind Temp Month Day temp_cat
1 41 190 7.4 NA 5 1 <NA>
2 36 118 8.0 72 5 2 <NA>
3 12 149 12.6 74 5 3 <NA>
4 18 313 11.5 62 5 4 tempéré
5 NA NA 14.3 56 5 5 tempéré
6 28 NA 14.9 66 5 6 tempéré
7 23 299 8.6 65 5 7 tempéré
8 19 99 13.8 59 5 8 tempéré
9 8 19 20.1 61 5 9 tempéré
10 NA 194 8.6 69 5 10 tempéré Comme mentionné précédemment, si certaines valeurs ne correspondent à aucune condition, alors le résultat est NA. C’est pour cela que la modalité attribuée à la ligne 1 est NA.
Pour éviter cette attribution de NA lorsqu’aucune des conditions n’est rencontrée, on peut ajouter un cas par défaut avec l’élément TRUE~ , comme ceci:
mydata9 <- mydata |>
mutate(
temp_cat = case_when(
Temp < 60 ~ "froid",
Temp <= 70 ~ "tempéré",
Temp > 70 ~ "chaud",
TRUE ~ "autre"
)
)
mydata9
Ozone Solar.R Wind Temp Month Day temp_cat
1 41 190 7.4 NA 5 1 autre
2 36 118 8.0 72 5 2 chaud
3 12 149 12.6 74 5 3 chaud
4 18 313 11.5 62 5 4 tempéré
5 NA NA 14.3 56 5 5 froid
6 28 NA 14.9 66 5 6 tempéré
7 23 299 8.6 65 5 7 tempéré
8 19 99 13.8 59 5 8 froid
9 8 19 20.1 61 5 9 tempéré
10 NA 194 8.6 69 5 10 tempéré Dans cette nouvelle version de {dplyr}, case_when() dispose à présent d’un argument .unmatched, avec une option “error” qui permet alors de générer une erreur et donc l’arrêt de l’exécution du code, si certaines valeurs ne correspondent à aucune condition. Cela permet de sécuriser le code, et donc d’être sûre qu’on a bien tout prévu :
mydata10 <- mydata |>
mutate(
temp_cat = case_when(
Temp < 60 ~ "froid",
Temp <= 70 ~ "tempéré",
Temp > 70 ~ "chaud",
.unmatched = "error"
)
)
Error in `mutate()`:
ℹ In argument: `temp_cat = case_when(...)`.
Caused by error in `case_when()`:
! Each location must be matched.
✖ Location 1 is unmatched. Personnelement, je pense que je vais adopter l’utilisation de ce nouvel argument car j’ai déjà eu de mauvaises surprises en employant cette fonction case_when().
La fonction replace_when() permet de modifier les valeurs d’une variable existante en fonction de conditions, sans avoir à la recréer entièrement.
Elle fonctionne sur le même principe que case_when(), mais avec une logique légèrement différente : au lieu de reconstruire une variable à partir de zéro, on part d’une variable existante et on vient simplement remplacer certaines valeurs.
Autrement dit, lorsque l’on souhaite effectuer des modifications ciblées, replace_when() est souvent plus adaptée que case_when().
Pour illustrer son utilisation, nous allons modifier la variable Temp du jeu de données airquality selon deux règles simples :
mydata11 <- mydata |>
mutate(
Temp = Temp |>
replace_when(
Temp < 60 ~ NA,
Temp > 90 ~ Temp + 5
)
)
mydata11
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 NA 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 NA 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 NA 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10 La fonction recode_values() permet de créer une nouvelle variable en remplaçant des valeurs par d’autres, sans utiliser de conditions, mais en définissant directement une correspondance entre valeurs.
Autrement dit, au lieu d’écrire des conditions (comme avec case_when()), nous indiquons simplement comment chaque valeur doit être transformée.
Cette approche est particulièrement utile lorsque l’on travaille avec des variables comportant un nombre limité de modalités, que l’on souhaite recoder.
Pour illustrer son utilisation, créons un sous-ensemble du jeu de données airquality, avec deux lignes pour chaque mois :
# creation d'un data frame avec deux lignes par mois
AQ1 <- airquality |>
slice(1,2,32,33, 62, 63, 93, 94, 124, 125)
AQ1
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 NA 286 8.6 78 6 1
4 NA 287 9.7 74 6 2
5 135 269 4.1 84 7 1
6 49 248 9.2 85 7 2
7 39 83 6.9 81 8 1
8 9 24 13.8 81 8 2
9 96 167 6.9 91 9 1
10 78 197 5.1 92 9 2 Nous allons recoder la variable Month en noms de mois. Autrement dit, remplacer les valeurs numériques (5, 6, 7, etc.) par “Mai”, “Juin”, “Juillet”, etc.
AQ2 <- AQ1 |>
mutate(
Month = Month |>
recode_values(
5 ~ "Mai",
6 ~ "Juin",
7 ~ "Juillet",
8 ~ "Août",
9 ~ "Septembre"
)
)
AQ2
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 Mai 1
2 36 118 8.0 72 Mai 2
3 NA 286 8.6 78 Juin 1
4 NA 287 9.7 74 Juin 2
5 135 269 4.1 84 Juillet 1
6 49 248 9.2 85 Juillet 2
7 39 83 6.9 81 Août 1
8 9 24 13.8 81 Août 2
9 96 167 6.9 91 Septembre 1
10 78 197 5.1 92 Septembre 2 La même manipulation est possible avec la fonction case_when(), mais le code est plus répétitif (Month == ) et moins fluide :
AQ3 <- AQ1 |>
mutate(
Month = case_when(
Month == 5 ~ "Mai",
Month == 6 ~ "Juin",
Month == 7 ~ "Juillet",
Month == 8 ~ "Août",
Month == 9 ~ "Septembre"
)
)
AQ3
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 Mai 1
2 36 118 8.0 72 Mai 2
3 NA 286 8.6 78 Juin 1
4 NA 287 9.7 74 Juin 2
5 135 269 4.1 84 Juillet 1
6 49 248 9.2 85 Juillet 2
7 39 83 6.9 81 Août 1
8 9 24 13.8 81 Août 2
9 96 167 6.9 91 Septembre 1
10 78 197 5.1 92 Septembre 2 Un avantage intéressant de recode_values() est qu’elle permet de s’appuyer sur une table de correspondance.
L’idée est simple : plutôt que d’écrire directement les transformations dans le code, nous pouvons définir un petit tableau qui fait le lien entre les anciennes et les nouvelles valeurs.
Par exemple, nous pouvons créer une table lookup qui associe chaque mois numérique à son équivalent en toutes lettres :
lookup <- tibble::tibble(
from = c(5, 6, 7, 8, 9),
to = c("Mai", "Juin", "Juillet", "Août", "Septembre")
)
lookup
# A tibble: 5 × 2
from to
<dbl> <chr>
1 5 Mai
2 6 Juin
3 7 Juillet
4 8 Août
5 9 Septembre Nous pouvons ensuite utiliser cette table dans la fonction recode_values() :
AQ4 <- AQ1 |>
mutate(
Month = recode_values(
Month,
from = lookup$from,
to = lookup$to
)
)
AQ4
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 Mai 1
2 36 118 8.0 72 Mai 2
3 NA 286 8.6 78 Juin 1
4 NA 287 9.7 74 Juin 2
5 135 269 4.1 84 Juillet 1
6 49 248 9.2 85 Juillet 2
7 39 83 6.9 81 Août 1
8 9 24 13.8 81 Août 2
9 96 167 6.9 91 Septembre 1
10 78 197 5.1 92 Septembre 2 Pour les biostatisticiens et data-managers, ça me semble une façon assez propre de gérer les code et recode. À ce stade, c’est plutôt une impression qu’un retour d’expérience, car je ne l’ai pas encore vraiment utilisée en pratique.
La fonction recode_values() peut également faire penser à la fonction fct_recode() du package forcats, qui permet de recoder les modalités d’une variable factorielle. On retrouve une logique similaire de correspondance entre anciennes et nouvelles valeur.
La fonction replace_values() permet de modifier certaines valeurs d’une variable existante en utilisant une correspondance entre valeurs, tout en conservant automatiquement les autres valeurs inchangées.
Elle est donc proche de recode_values(), mais avec une différence importante : recode_values() sert à recoder une variable en définissant une nouvelle correspondance, alors que replace_values() est plus adaptée lorsque nous souhaitons seulement modifier certaines modalités, sans toucher aux autres.
Pour illustrer son utilisation, repartons de notre jeu de données AQ3, dans lequel la variable Month contient déjà les noms des mois.
Imaginons maintenant que nous souhaitions regrouper certaines modalités de cette variable :
Tout en laissant le mois de septembre inchangé :
AQ4 <- AQ3 |>
mutate(
Month = Month |>
replace_values(
c("Mai", "Juin") ~ "Printemps - début été",
c("Juillet", "Août") ~ "Plein été"
)
)
AQ4
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 Printemps - début été 1
2 36 118 8.0 72 Printemps - début été 2
3 NA 286 8.6 78 Printemps - début été 1
4 NA 287 9.7 74 Printemps - début été 2
5 135 269 4.1 84 Plein été 1
6 49 248 9.2 85 Plein été 2
7 39 83 6.9 81 Plein été 1
8 9 24 13.8 81 Plein été 2
9 96 167 6.9 91 Septembre 1
10 78 197 5.1 92 Septembre Nous pourrions obtenir le même résultat avec recode_values(), à condition de préciser explicitement que les valeurs non concernées doivent être conservées avec l’argument default:
AQ5 <- AQ3 |>
mutate(
Month = recode_values(
Month,
c("Mai", "Juin") ~ "Printemps - début été",
c("Juillet", "Août") ~ "Plein été",
default = Month
)
)
AQ5
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 Printemps - début été 1
2 36 118 8.0 72 Printemps - début été 2
3 NA 286 8.6 78 Printemps - début été 1
4 NA 287 9.7 74 Printemps - début été 2
5 135 269 4.1 84 Plein été 1
6 49 248 9.2 85 Plein été 2
7 39 83 6.9 81 Plein été 1
8 9 24 13.8 81 Plein été 2
9 96 167 6.9 91 Septembre 1
10 78 197 5.1 92 Septembre Cette écriture fonctionne, mais elle est un peu moins directe. replace_values() est ici plus naturelle, car elle correspond exactement à notre intention : remplacer certaines valeurs et laisser les autres inchangées.
La fonction replace_values() me semble assez proche de fct_collapse() du package forcats, dans l’idée de regrouper plusieurs modalités sous une même étiquette.
Là encore, l’avancée n’est pas majeure, mais elle simplifie tout de même un peu la manipulation des données.
Cette nouvelle version de dplyr apporte plusieurs fonctions intéressantes qui viennent enrichir les outils de manipulation des données.
Comme nous l’avons vu, les nouveautés proposées ne sont pas toujours révolutionnaires dans leur usage, car il était déjà possible d’obtenir des résultats similaires avec des fonctions existantes comme case_when() ou filter(). En revanche, elles permettent d’écrire un code plus lisible, plus direct et souvent plus proche de l’intention que l’on souhaite exprimer.
Certaines fonctions, comme filter_out(), m’ont particulièrement convaincue et je pense les intégrer rapidement dans mes pratiques. J’ai également beaucoup apprécié la fonction recode_values(), qui me semble très adaptée pour gérer des problématiques de codage et décodage de manière propre et structurée.
D’autres fonctions, comme when_any(), when_all() ou encore replace_values(), me semblent intéressantes, mais leur adoption dépendra probablement des habitudes de chacun et du contexte d’utilisation.
Si vous souhaitez aller plus loin sur la manipulation des données avec dplyr, je vous invite à consulter mes autres articles sur le sujet, en cliquant sur le liens :
Et vous, avez-vous déjà testé ces nouvelles fonctions dans vos projets ?
N’hésitez pas à partager votre retour d’expérience ou à poser vos questions en commentaire. L’idée est vraiment de pouvoir échanger et progresser ensemble autour de ces outils.
Si cet article vous a été utile, c’est peut-être le bon moment pour structurer votre pratique.
Je propose des formations complètes ainsi que des ateliers plus ciblés pour travailler concrètement la manipulation de données, les analyses statistiques ou le reporting avec R.

CAMPUS DELLADATA
Je propose désormais une formation en ligne pour démarrer avec R et RStudio, pensée pour les profils scientifiques (recherche médicale, biologie, agro, environnement…). D’autres modules arrivent prochainement.

Je suis Claire Della-Vedova, consultante en biostatistique, méthodologie clinique et expertise R.
J’accompagne les fabricants de dispositifs médicaux et les équipes scientifiques des sciences du vivant dans leurs projets d’évaluation clinique, d’analyse statistique et d’analyse de données sous R.
🎓 Formations professionnelles R et biostatistiques
🤝 Prestations et accompagnement sur mesure
📅 Discuter d’un accompagnement ou d’une prestation sur mesure
Vous pouvez soutenir mon travail en faisant un don libre sur le Tipeee du blog

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
2 réponses
Merci Claire, toujours un plaisir de voir un nouvel article sur ce blog, et ces nouvelles foncions sont vraiment intéressantes ! Je vais mettre à jour dplyr 🙂
Merci beaucoup pour cet article très intéressant.
Je me demande quelle est la différence entre cette nouvelle fonction filter_out() et l’utilisation des ! dans la fonction filter() normale.
Par example, j’utilise souvent filter(!is.na(variable)) ou filter(! variable == 0) ce qui permet d’éviter les raisonnements en opposition. Je crois que ça donne le même résultat si on utilise filter_out(is.na(variable)) ou filter_out(variable == 0), mais peut-être que j’oublie un aspect important ?