Ressources pour l'ACP
Principe

Cette animation est issue de ce post sur Cross Validated (n’hésitez pas à le consulter il est vraiment intéressant !).
Elle va ensuite considérer cet axe (c’est ce qu’on appelle la première composante principale), et son perpendiculaire (la seconde composante principale), pour définir un plan (le premier plan de l’ACP). Et pour résumer le nuage des observations, l’ACP va les projeter sur le plan défini. Une approche similaire est réalisée avec le nuage des variables.
A la fin de l’ACP, on obtient deux représentations graphiques, en deux dimensions : l’une concernant les observations, l’autre les variables, comme celles-ci :
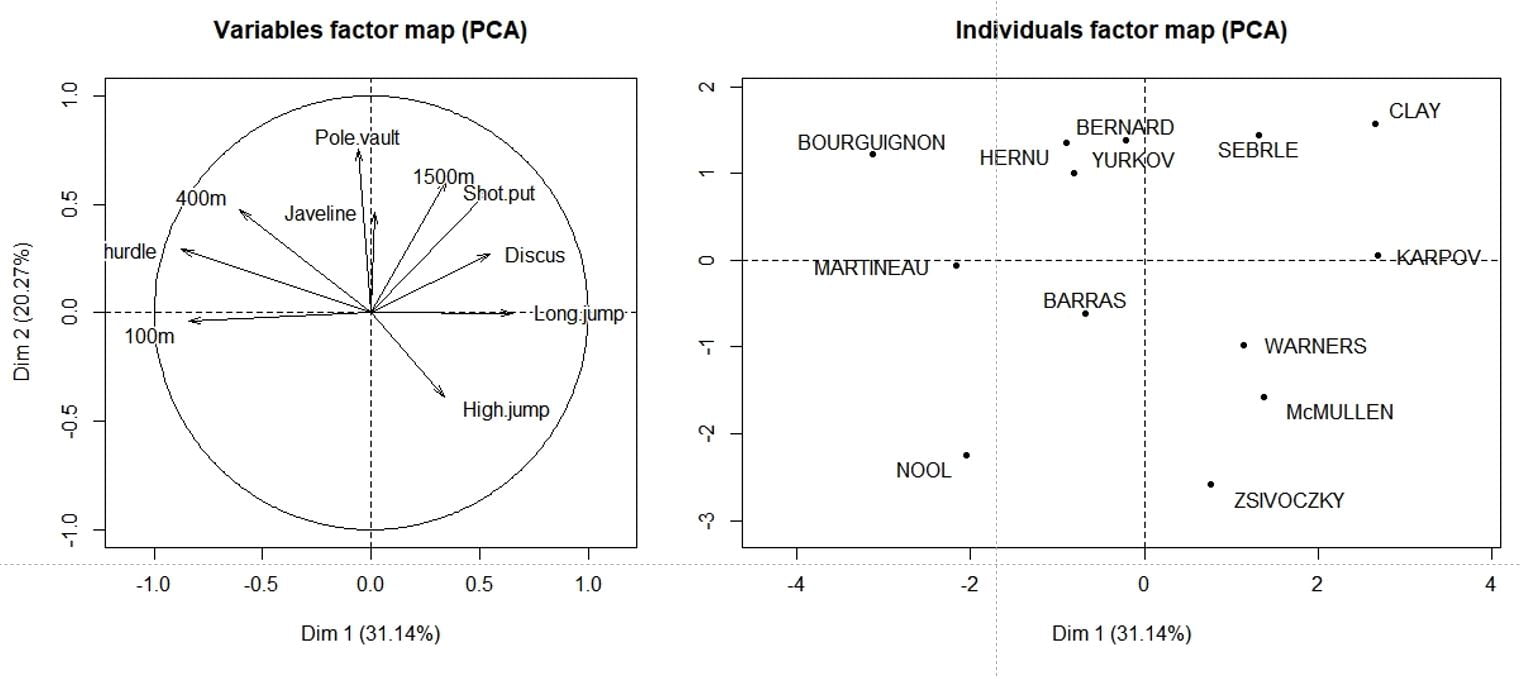
A partir de ces plots on va pouvoir étudier :
- les relations entre les variables (les colonnes),
- les relations entre les observations (lignes),
- les relations entre les observations et les variables (par exemple, quelles sont les observations ayant des valeurs élevées pour telle ou telle variable).
- essayer de donner une signification « métier » aux axes de l’ACP.
En réalité l’ACP ne s’arrête pas à 2 axes et en définie N-1. Mais, en pratique, on représente généralement les projections des observations et des variables sur les plans définis par les axes 1 et 2, voir 1 et 3 mais rarement plus.
Sans entrer dans le détail des calculs mathématiques, il est assez intuitif de comprendre que le passage d’un nuage de points à N dimensions, dans un espace à deux dimensions, est forcément imparfait et qu’une part de l’information originale se perd dans cette réduction. La dispersion du nuage de points dans les N dimensions originales s’appelle l’inertie, et pour évaluer la quantité d’information conservée par l’approche ACP, on calcul le pourcentage d’inertie expliqué par chacun des axes. Ces pourcentages sont d’ailleurs rapportés sur le plot du cercle des corrélations (plot des variables).
Dans le cadre des analyses prédictives, l’ACP n’est plus vraiment employée pour étudier les relations entres les observations ou entre les variables, mais simplement pour réduire le nombre de variables qui seront inclues dans le modèle de prédiction. Dans cette situation, les variables sont remplacée par les composantes principales.
Ressources vidéos
Et si vous n’accrochez pas, vous pouvez aussi essayer la vidéo suivante, de Jérôme Pagès, lui aussi d’agroucampus ouest. Elle est également très appréciée des étudiants :
Si vous trouvez les vidéos trop longues, vous pouvez les visionner en vitesse 1.5, ça reste très compréhensible !
Le package FactoMineR
- l’ACP ne supporte pas les données manquantes. Or, par défaut, la fonction PCA() de FactoMineR les substitue par la moyenne de la variable. Cela est très pratique lorsque le jeu de données ne comporte que peu de données manquantes.
- par défaut également, les données sont centrées, réduites ; cette procédure n’a donc pas besoin d’être spécifiée.
- les plots des variables et des observations sont générés de façon automatique.
- il est possible d’ajouter des variables supplémentaires sur les plots des variables et/ou des observations pour voir comment celles-ci sont liées aux axes de l’ACP, ou encore aux autres variables du jeu de données.
- les sorties de la fonction PCA peuvent être utilisées avec le package ‘factoextra’ développé par Alboukadel Kassambara (qui gère le site STHDA) afin d’améliorer les plots de base l’ACP ou en réaliser d’autres. Par exemple, pour visualiser la qualité de représentation de chaque variable, ou encore pour visualiser leur contribution aux axes.
Un exemple
Les données du Décastar
Pour cette partie, je vais utiliser une partie du jeu de données décathlon (inclus dans le package FactoMineR). C’est un exemple ultra classique mais je le trouve vraiment pédagogique :
library(FactoMineR)
data(decatlon) library(tidyverse)
data(decathlon)
decastar<- decathlon %>%
filter(Competition=="Decastar") %>%
dplyr::select(-Competition) rownames(decastar) <- rownames(decathlon)[1:13] head(decastar)
100m Long.jump Shot.put High.jump 400m 110m.hurdle Discus
SEBRLE 11.04 7.58 14.83 2.07 49.81 14.69 43.75
CLAY 10.76 7.40 14.26 1.86 49.37 14.05 50.72
KARPOV 11.02 7.30 14.77 2.04 48.37 14.09 48.95
BERNARD 11.02 7.23 14.25 1.92 48.93 14.99 40.87
YURKOV 11.34 7.09 15.19 2.10 50.42 15.31 46.26
WARNERS 11.11 7.60 14.31 1.98 48.68 14.23 41.10
Pole.vault Javeline 1500m Rank Points
SEBRLE 5.02 63.19 291.7 1 8217
CLAY 4.92 60.15 301.5 2 8122
KARPOV 4.92 50.31 300.2 3 8099
BERNARD 5.32 62.77 280.1 4 8067
YURKOV 4.72 63.44 276.4 5 8036
WARNERS 4.92 51.77 278.1 6 8030 La fonction PCA()
Comme expliqué précédemment, par défaut, la fonction ‘PCA()’ de ‘FactoMineR’ centre et réduit les variables avant de réaliser l’ACP. Cette étape est importante afin que toutes les variables aient le même poids dans la construction des plans de l’ACP. Si pour une raison ou une autre vous souhaitez vous passer de la réduction des variables, (ce qui n’est pas recommandé) vous pouvez utiliser l’argument ‘scale.unit=FALSE’.
Ici, on va réaliser l’ACP uniquement sur les 10 variables des disciplines; les variables score et rank seront ajoutées comme variables supplémentaires dans un second temps. Les plots des variables et des observations sont générés automatiquement.
decastar.pca <- PCA(decastar[,1:10]) Ajouter des variables supplémentaires
decastar <- decastar %>%
mutate(group=ifelse(Points>8000, "high", "low")) quanti.supp et quali.supp :decastar.pca2 <- PCA(decastar, quanti.sup=11:12, quali.sup=13) 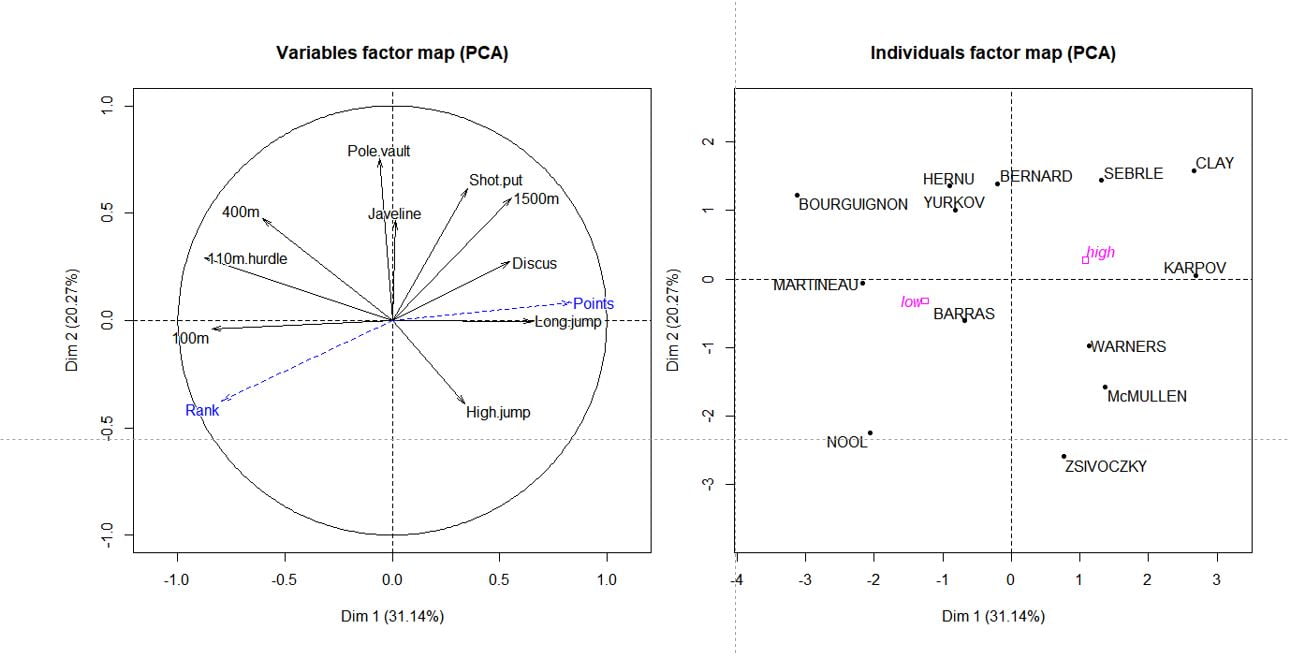
Autres types de résultats
La fonction summary() permet d’accéder à de nombreuses informations.
summary(decastar.pca) 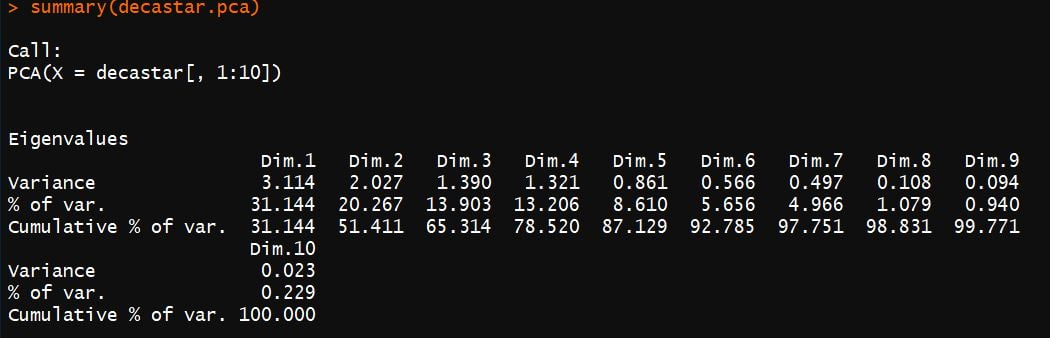
Remarque : les pourcentages d’inertie sont les valeurs propres ou d’eigen values (il s’agit de la quantité de variance expliquée), exprimées en pourcentage.
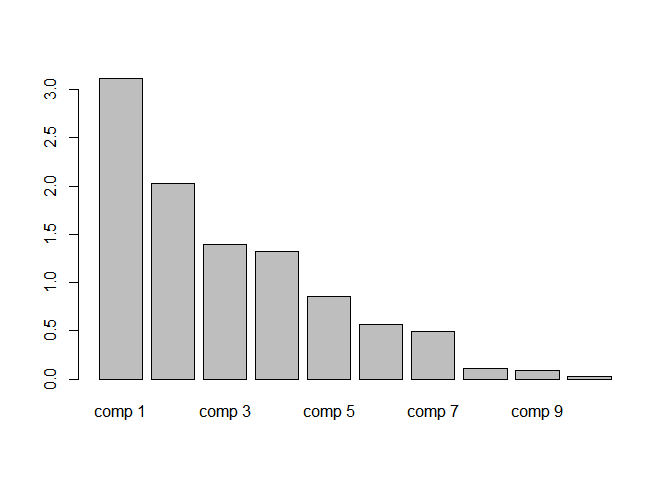
Il est également possible de réaliser un plot pour visualiser ces pourcentages d’inertie :
barplot(decastar.pca$eig[,1])
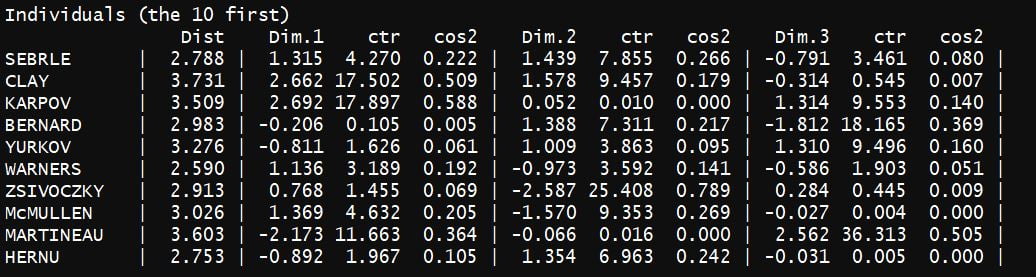
La troisième partie des résultats est identique à la deuxième, mais concerne les variables :

Utiliser le package factoextra
Visualiser le pourcentage d'inertie des axes
library(factoextra)
library(corrplot)
fviz_eig(decastar.pca, addlabels = TRUE) 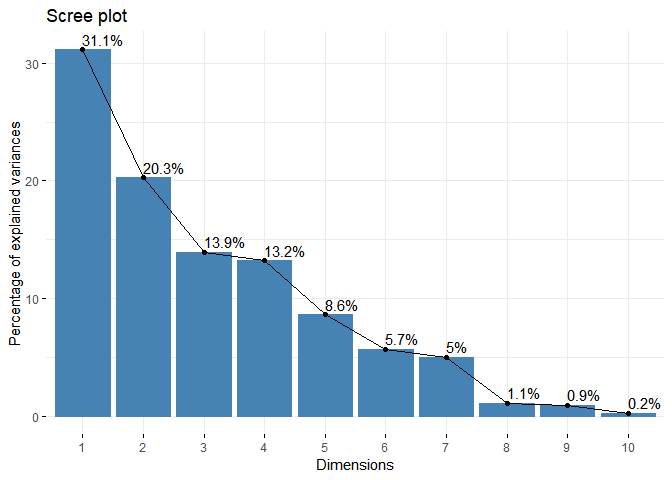
Visualiser la qualité de la représentation des variables
res <- get_pca_var(decastar.pca)
corrplot(res$cos2) 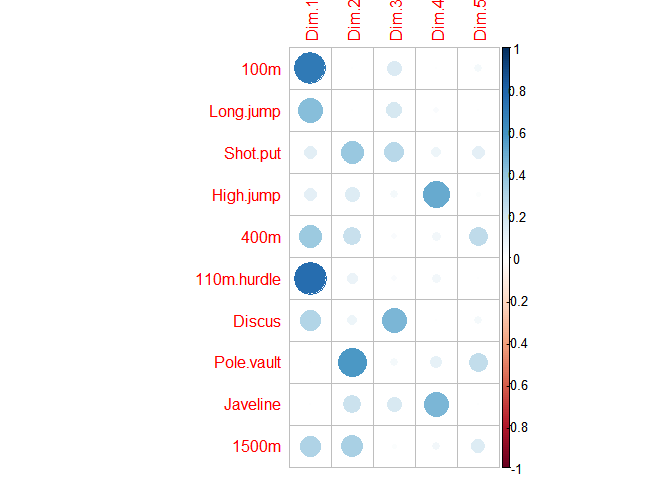
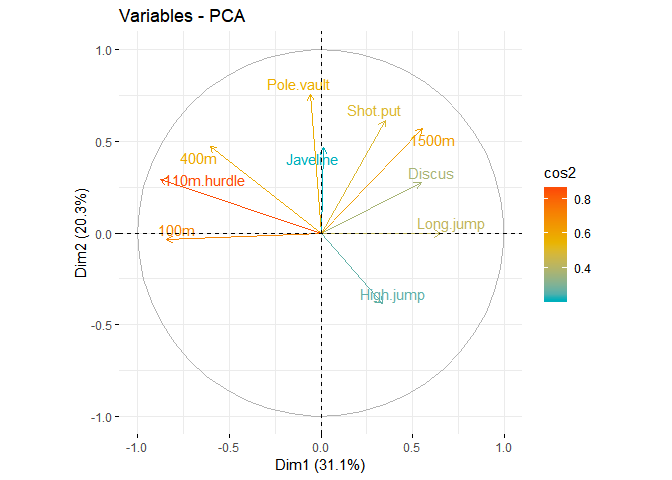
fviz_pca_var (decastar.pca, col.var = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Évite le chevauchement de texte
) 
Visualiser la contribution des variables aux axes
corrplot(res$contrib, is.corr=FALSE) 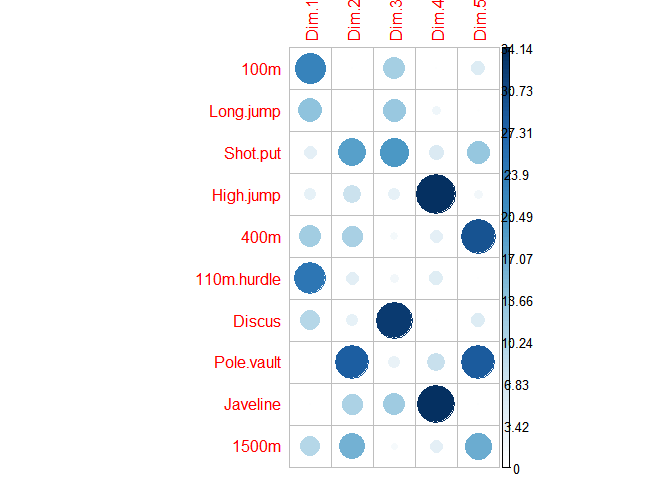
Visualiser la qualité de la représentation des observations
fviz_pca_ind (decastar.pca, col.ind = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Évite le chevauchement de texte) 
Vous trouverez d’autres exemples de représentations ici.
Conclusion
Poursuivez votre lecture avec d’autres articles de data analyse

Je recherchais justement un cours assezsouple sur l’ACP et vous me rendez ce grand service. Je vous remercie pour tout et surtout pour ces belles illustrations qui m’aideront beaucoup.
Bonjour Claire,
Pour tout ce qui est analyse multivariée, il y a aussi le fameux package ade4 sous R (https://cran.r-project.org/web/packages/ade4/index.html), auquel est maintenant associé un livre : https://www.springer.com/fr/book/9781493988488.
Tout ça est maintenu par des collègues de mon labo : https://lbbe.univ-lyon1.fr/?lang=fr.
Amitiés,
Sandrine
Bonjour Claire,
Merci encore pour cet article pour qui vient enrichir nos connaissances.
Merci beaucoup
Bonjour Claire,
Je tiens à vous remercier pour ce beau travail 🙂
Merci pour le rappel très utile, cours effectuée en DEA d’économie mais trop générique à l’époque (avec Eviews). C’est on a du mal à trouver sur le net des ressources sur la question pour une mise à niveau.
Très bon article merci!
Je n’ai pas trouvé sur votre blog, auriez vous par hasard la même chose pour l’AFC?
L’ACM?
On ne sait jamais 🙂
Très bonne continuation et à bientôt sur ce très bon blog!
Bonjour,
Non, rien sur l’AFC et ACM, mais je pense que vous allez trouver votre bonheur ici : https://husson.github.io/MOOC.html
Bonne continuation.
Bravo Claire !
Comme d’habitue vous nous fascinez par vos très baux articles et très belles astuces sur votre tops adorable blog,
NB: Je signale que vous n’avez pas mis le bon code de « factoextra » quant au graphe des variables,
Merci infiniment,
très bon article avec des explications tassez clair et précis. Merci
Bonjour, y a t il un support théorique de l ACP
En général l’analyse factorielle
Bonjour,
merci pour ce bel article, toujours bien expliqué !
Serait-il possible de corriger le code du package factoextra, qui permet de faire le graphique des variables ?
Merci !
Bonjour,
je vais essayer….
Bonjour Claire,
dans l’exemple, le nom des athlètes n’est pas contenu dans une variable, mais en label des lignes. Comment est-il possible de faire de même avec une autre base de données, sachant que l’ID de chaque individu est en colonne 1 ?
Merci 🙂
Bonjour, pourquoi les résultats des packages « FactoMineR » et « ade4 » donnent-ils des résultats différents par exemple pour les coordonnées des individus les signes sont inversés. J’ai fait un calcul manuel en utilisant les formules théoriques et mes calculs concordent plus avec le package « ade4 »
Je pense que les résultats doivent simplement être inversés. cela n’a pas d’importance. Si ils sont un peu différents, c’est peut être qu’une standardisation est faite de façon différente. Dans tous les cas, les distances entre les points restent identiques.
Bonne continuation.
Bonjour à vous, le package FactoMineR prend en compte les NA par défaut dans son analyse, si vous voulez qu’il fasse pareil que ade4, il faut lui ajouter l’argument complete.obs
Cela est dû à un traitement différent des valeurs manquantes. Alors que *dudi.acm* de ade4 exclu les valeurs manquantes, *MCA* de FactoMineR les considérent, par défaut comme une modalité additionnelle. Pour calculer l’ACM uniquement sur les individus n’ayant pas de valeurs manquantes avec FactoMineR, on aura recours à *complete.cases*
Bonjour à vous,
Cela est dû à un traitement différent des valeurs manquantes. Alors que *dudi.acm* de ade4 exclu les valeurs manquantes, *MCA* de FactoMineR les considérent, par défaut comme une modalité additionnelle. Pour calculer l’ACM uniquement sur les individus n’ayant pas de valeurs manquantes avec FactoMineR, on aura recours à *complete.cases*
Merci Claire,
Vos cours sont d’une simplicité inégalée.
Bonne continuation…
[…] dernières solutions. J’ai découvert FactoMineR après la lecture du très bon article de Claire Della Vedova. Quant à Factoshiny, je m’y suis familiarisé grâce au tutoriel de François […]
bonjour Claire, c’est toujours super bien expliqué votre blog. Juste une petite erreur dans 4.5.2, l’affichage est bien les variables, mais les commandes sont pour l’affichage des individus. sinon, avec pca de FactoMiner, je n’obtiens qu’une figure de variables, mais pas celle de individus.
Bonjour Claire!
Merci pour cette explication ! Je suis nouvelle sur R et ce cercle des corrélation est particulièrement approprié je trouve.
J’ai une petite question. Le package factoextra ne semble pas fonctionner et du coup, je ne peux pas adapter le visuel de la représentation par individus, car il ne reconnait pas la fonction fviz_pca_ind.
Y’a-t-il un autre moyen d’indiquer à R de faire des catégories, comme il est possible de le faire dans ggplot, par exemple avec des ellipse ?
Salomé
Bonjour,
je suis étonnée que le package factoextra ne fonctionne pas. Avez vous essayer de faire les mises à jour de R et des packages ?
https://statistique-et-logiciel-r.com/tutoriel-mise-a-jour-de-r/
Bonjour, je voulais juste vous dire qu’il y a une tout petite erreur dans la partie : Utiliser le package factoextra / Visualiser la qualité de la représentation des variables
Le script écrit :
fviz_pca_ind (decastar.pca, col.ind = « cos2 »,
gradient.cols = c(« #00AFBB », « #E7B800 », « #FC4E07 »),
repel = TRUE # Évite le chevauchement de texte
)
Mais c’est : fviz_pca_VAR (decastar.pca, col.VAR = …..
Sinon c’est super, ça ma beaucoup aidé, merci !
Bonjour Adrien,
merci beaucoup pour le signalement, je viens de modifier !
merci énormément claire
Bonjour,
depuis aujourd’hui, le package FactoMines ne se charge plus. J’ai cette erreur qui apparait
Error: package or namespace load failed for ‘FactoMineR’ in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]]):
there is no package called ‘emmeans’
J'ai tenté de réinstallé sans succès.
Auriez-vous une idée? Merci bcp … et bravo pour tous vos conseils et infos 🙂
Bonjour Véronique,
D’après le message d’erreur, j’ai l’impression qu’il y a un problème avec le package emmeans.
Je vous suggère de commencer par essayer d’installer le package emmeans, puis de réinstaller FactoMineR.
Si cela ne fonctionne pas, c’est peut être un problème de comptabilité avec la nouvelle version de R (4.3.3) qui vient de sortir. Dans ce cas, il faut installer cette nouvelle version. Vous trouverez des explications pour le faire facilement dans cet article :
https://delladata.fr/tutoriel-mise-a-jour-de-r/
Vous pouvez consulter aussi cet article pour tenter les installations des packages via des fichiers zip
https://delladata.fr/comment-reussir-installation-des-packages/
Bien à vous.