Le théorème central limite (TCL) est un théorème très important en biostatistique. Ce théorème nous dit que, quelle que soit la distribution d’une variable aléatoire X, la somme de cette variable (S(x)), et par extension, la moyenne (moy(x)), puisque la moyenne est une somme divisée par une constante), suivent une distribution normale.
Autrement dit, même si une variable ne suit pas une distribution normale, la moyenne de cette variable suit une distribution normale.
C’est le recours à ce théorème qui nous permet, entre autres, d’estimer l’intervalle de confiance d’une moyenne, en employant la formule :
\[IC = \bar{x} \pm z_{1-\frac{\alpha}{2}}\;\frac{sd(x)}{\sqrt{n}}\]
On parle d’approximation normale de l’intervalle de confiance, puisque le terme Z1_α/2 est le quantile de la loi normale correspondant à la probabilité 1−α/2 .
Pour un intervalle de confiance à 95%, α = 0.05 et le quantile correspondant à la probabilité 0.975 (les 5% sont répartis pour moitié à droite, pour moitié à gauche) est égal à 1.965.
Il est courant d’accepter l’application de ce théorème lorsque le nombre de données est au moins égale à 30 (c’est un chiffre que l’on retrouve souvent, je ne sais pas d’où il vient, et je ne doute que ce nombre soit toujours suffisant).
Pour cela, nous allons simuler 50 valeurs d’une variable X, selon une loi uniforme, en spécifiant une valeur minimum de 10 et une valeur maximale de 20.
La loi uniforme spécifie que la densité de probabilité est constante sur l’intervalle [min; max]
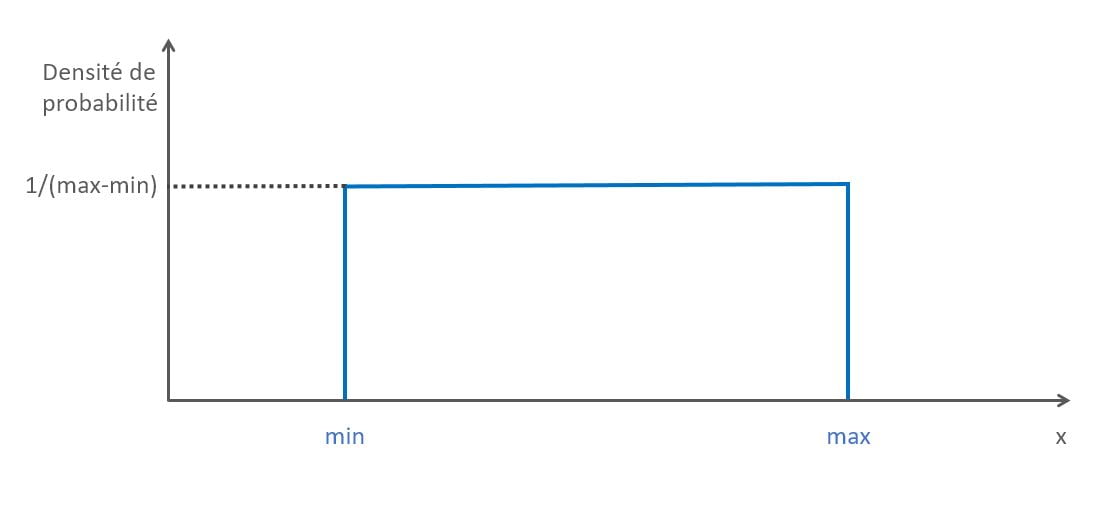
Autrement dit, la probabilité de sélectionner une valeur entre le min et le max spécifiés est la même, elle est constante.
# permet de fixer la graine du tirage aléatoire, pour que l'exemple soit reproductible
set.seed(2)
# génération de 50 données selon la loi uniforme de min=10 et max=20
x <- runif(50,min=10, max=20)
Nous allons, à présent, afficher les 6 premières valeurs simulées et visualiser la distribution de l’ensemble des 50 valeurs :
# affichage de 6 premières valeurs simulées
head(x)
## [1] 11.84882 17.02374 15.73326 11.68052 19.43839 19.43475
# visualisation de la distribution des
hist(x, breaks=10, col="skyblue", main="Simulation de l'échantillon\n selon une loi uniforme") 
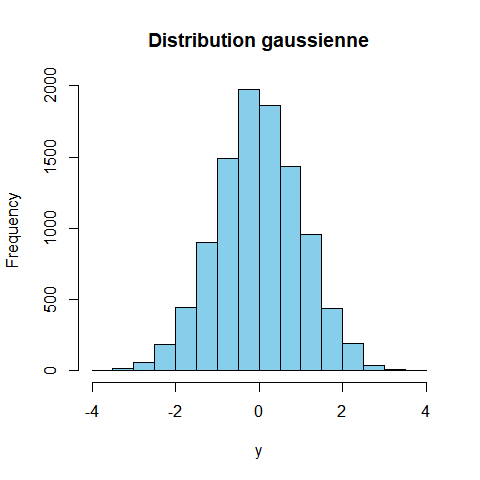
Comme nous pouvons le voir la distribution de la variable x a plutôt une forme uniforme, et absolument pas normale (on dit aussi gaussienne). Une distribution gaussienne à une forme en cloche comme ceci :
Enfin, nous calculons la moyenne (moy(x)):
moy_x = mean(x)
moy_x
## [1] 15.11183 Pour évaluer la distribution de la moyenne de x (moy(x)), une seule valeur n’est pas suffisante ! Il nous faut donc recommencer la simulation d’un échantillon de valeurs un grand nombre de fois (10 000 par exemple), et stocker la moyenne de chaque échantillon dans un vecteur :
# Nombre de simulations
nb_sim <- 10000
# Taille de l'échantillon simulé
sample_size <- 50
# initialisation du vecteur de stockage des moyennes
moy_vec <- vector(length=nb_sim)
# simulations
set.seed(2)
for (i in 1 : nb_sim)
{
x <- runif(sample_size,10, 20)
moy_vec[i] <- mean(x)
} A présent que la moyenne de chaque échantillon simulé est contenue dans le vecteur, nous allons pouvoir visualiser la distribution de ces moyennes :
hist(moy_vec, breaks=20, col="red3", main="Distribution des moyennes\n des échantillons simulés\n selon une loi uniforme") 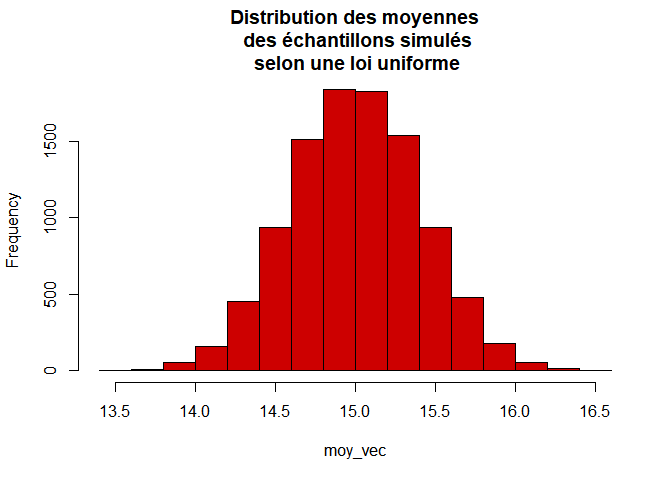
Nous pouvons voir que les moyennes ont bien une distribution gaussienne !
Essayons, à présent, avec une autre distribution, log-normale par exemple, qui est une distribution asymétrique :
# permet de fixer la graine du tirage aléatoire, pour que l'exemple soit reproductible
set.seed(2)
# génération de 50 données selon la loi log normal (meanlog=0, sdlog=1)
x <- rlnorm(50, meanlog = 0, sdlog = 1)
hist(x, breaks=10,col="skyblue", main="Simulation de l'échantillon\n selon une loi log-normale" ) 
Comme attendu, nous pouvons voir que la distribution de la variable x est bien asymétrique, et absolument pas normale.
mean(x)
## [1] 1.920796
# Nombre de simulations
nb_sim <- 10000
# Taille de l'échantillon simulé
sample_size <- 50
# initialisation du vecteur de stockage des moyennes
moy_vec <- vector(length=nb_sim)
# simulations
set.seed(1)
for (i in 1 : nb_sim)
{
x <- rlnorm(sample_size , meanlog = 0, sdlog = 1)
moy_vec[i] <- mean(x)
} hist(moy_vec, breaks=20, col="red3", main="Distribution des moyennes\n des échantillons simulés\n selon une loi log normale (n=50)") 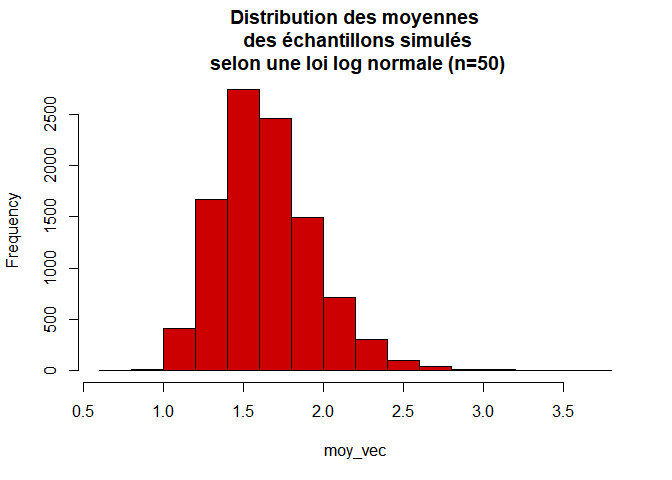
Bien que la distribution ne soit pas parfaitement gaussienne, elle en a globalement la forme.
Si nous augmentons la taille des échantillons générés à 100, nous pouvons voir que la “normalité” s’améliore :
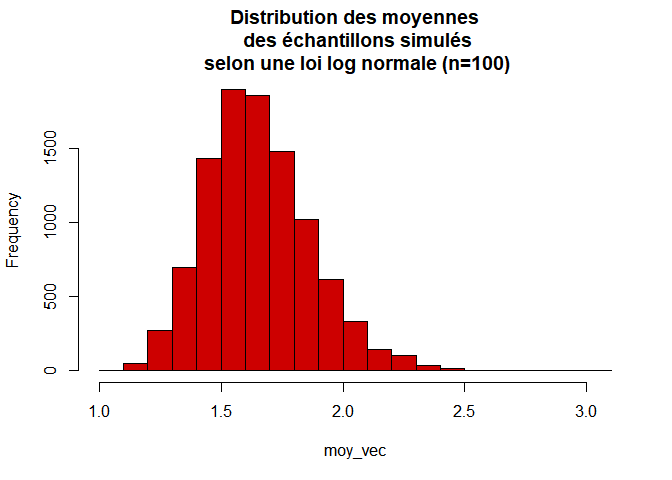

La normalité s’améliore encore davantage avec n=200 !
J’espère que cette petite illustration vous permettra de mieux comprendre ce théorème central limite, et son implication dans le calcul de l’intervalle de confiance.
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
17 réponses
Merci Claire pour ce rappel très instructif.
Intéressant bien détaillé super boulot
Bonjour Madame.
Vous accomplissez un travail formidable.
Vos articles regorgent beaucoup d’intérêt et de pertinence.
Merci.
Un article très itéressant MERCI
Félicitations, Madame !
Grâce à vous, je comprends mieux ce théorème.
Merci beaucoup.
Hey !
Merci pour cet article, mais j’ai deux petites questions concernant l’application pratique du théorème.
1) Mettons que le labo où je bosse me demande une analyse statistique sur les résultats de 100 prélèvements concernant un gène X.
Les valeurs ne suivent pas une loi normale (on va dire qu’elles sont uniformes). Comme est-ce que le CTL s’applique ? Je ne peux pas générer des valeurs aléatoires pour obtenir plusieurs moyennes comme on le fait ici, puisque je dois travailler sur ces 100 prélèvements.
2) Dans le cas où l’on peut appliquer le CTL, celui-ci ne sert bien qu’à déterminer les intervalles de confiance n’est-ce pas ? Est-ce que cela ne revient pas au même que de calculer les intervalles de confiance via le SEM ?
Merci d’avance ^^
BONJOUR Mme CLAIRE DELLA VEDORA
Merci Infiniment pour votre collaboration
veuillez nous informer sur logiciel « R » réseau neurone artificiel
et merci d’avance
Bonjour Sabri Assia,
à priori, ça ne sera pas pour tout de suite, tout de suite…
Bonne continuation.
Merci Claire pour cette belle démonstration qui vient nous édifier d’avantage et comme d’habitude.
Un Grand Merci.
je vous remercie vivement pour votre initiative
Merci Kazim !
Bonne continuation
Merci beaucoup Claire.
Bien cordialement, avec toute notre attention.
Moïse,
Je lance un 20 fois un dès équilibré à 6 faces. j’aimerais savoir la probabilité pour que la sommes soit au moins égales à 100.
J’ai calculé l’espérance pour une lance et la variance. Comment puis je faire pour trouver la sommes pour une lance?
Vous prétendez démontrer et ne faites qu’illustrer.
Ce qui revient au même dans le cas présent…..