Gérer les données de date et d'heure avec le package lubridate
Si vous avez déjà dû travailler sur des fichiers comportant des données indiquant le temps, avec des dates, ou des heures (et des minutes et des secondes), ou les deux à la fois, vous savez que ce n’est pas toujours facile à gérer. D’abord, parce que les dates ne sont pas toujours écrites de la même façon. Par exemple, pour le premier mars 2019, on peut trouver « 2019-03-01 » ou encore 1-mars-2019, ou encore 01/03/2019, etc… La même remarque peut être faite pour les heures, les minutes et les secondes. Et ensuite, parce qu’il faut convertir ces données, qui sont généralement considérées comme des chaînes de caractères, ou des modalités d’une variable catégorielle à l’issue de l’importation dans R, dans un format (ou classe) reconnu comme étant du temps dans R. Ces formats (ou classes) sont notamment le format POSIXct et le format Date.
Une fois que ces données indiquant le temps, sont correctement reconnues par R, il est alors possible de les manipuler, de réaliser des analyses descriptives (par année, mois, jour, heure, etc…), de les représenter visuellement, ou encore de réaliser des calculs.
Le package lubridate a été spécialement conçu pour gérer ces données de temps et les rendre facilement manipulables. Cet article est alors une courte introduction à l’utilisation de ce package.
Le format standard des données de temps (date et heure)
Depuis 1988, il existe un format standardisé des données de date et d’heure. Ce format est régi par la norme ISO 8601. Cette norme spécifie que les dates doivent être exprimées selon le format YYYY-MM-DD (années-mois-jour) et que les heures doivent être exprimées selon le format HH:MM:SS (heures:minutes:secondes).
Ce sont ces formats qui sont utilisés par R. C’est donc vers ces formats qu’il faut transformer les données indiquant le temps.
Les données de date et d'heures utilisées
Pour illustrer cet article, j’ai choisi d’utiliser le jeu de données « Pollution in Atchison Village, Richmond CA » disponible sur Kaggle.
Ce jeu de données contient des mesures de pollution et de vent réalisées entre août et novembre 2015, dans le Village d’Atchison, en Californie.
mydata <- read.csv(here::here("data", "AtchisonUV_20150801_to_20151119.csv"), stringsAsFactors = FALSE)
head(mydata,3)
## Date Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
## 1 10/10/15 3:15 2.5 2.5 2.5 2.5 2.50 220.61 162
## 2 10/10/15 2:00 2.5 2.5 2.5 2.5 2.50 184.78 158
## 3 10/10/15 4:30 2.5 2.5 2.5 2.5 573.36 144.61 166
## Wind.Speed Wind.Origin
## 1 6 SSE
## 2 7 SSE
## 3 5 SSE Comme vous pouvez le voir, le jeu de données comporte une variable Date qui contient à la fois des informations de dates et d’heures (et de minutes, mais pas de secondes). En utilisant la fonction tail(), on peut se rendre compte que les dates sont exprimées dans un format « mois/jour/année ». Les heures, quant à elles, sont exprimées dans un format « heure : minutes ».
tail(mydata,3)
## Date Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
## 31640 11/18/15 23:50 2.5 2.5 20.61 2.5 2.5 2.5 107
## 31641 11/18/15 23:55 2.5 2.5 20.59 2.5 2.5 2.5 100
## 31642 11/19/15 0:00 2.5 2.5 20.47 2.5 2.5 2.5 86
## Wind.Speed Wind.Origin
## 31640 2 ESE
## 31641 2 E
## 31642 2 E L’étude de la structure de ces données par la fonction str(), nous permet de voir que cette variable « Date » est considérée comme une chaîne de caractères. Cela est dû au fait que l’argument « stringsAsFactors = FALSE » a été employé dans la fonction read.csv(). Sans cet argument, la variable « Date » serait considérée comme une variable catégorielle. Cela n’a pas d’influence pour la gestion des données indiquant le temps.
str(mydata$Date)
## chr [1:31642] "10/10/15 3:15" "10/10/15 2:00" "10/10/15 4:30" .. Changer le format et la classe des données de date et d'heure
Le package lubridate contient plusieurs fonctions de parsing, qui prennent en entrée les données dans leur format original, et les transforment, d’une part dans le format standardisé, et d’autre part, dans une classe reconnue comme étant du temps, la fameuse classe POSIXct !
Ces fonctions sont nommées :
- ymd_hms(), ymd_hm(), ymd_h()
- ydm_hms(), ydm_hm(), ymd_h()
- mdy_hms(), mdy_hm(), mdy_h()
y pour year, m pour month, d pour day, h pour hour, m pour minute et s pour second.
Il suffit de repérer l’ordre dans lequel sont exprimées les années, mois, jours puis heurs, minutes et secondes, puis d’utiliser la fonction correspondante pour transformer les données dans le format standardisé « YYYY-MM-DD HH:MM:SS ».
Par exemple, ici les données de temps sont exprimées en mois/jour/années puis heure : minute. Pour les transformer dans le format standardisé, il faut donc utiliser la fonction mdy_hm().
library(lubridate)
mydata$Date2 <- mdy_hm(mydata$Date)
head(mydata,3)
## Date Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
## 1 10/10/15 3:15 2.5 2.5 2.5 2.5 2.50 220.61 162
## 2 10/10/15 2:00 2.5 2.5 2.5 2.5 2.50 184.78 158
## 3 10/10/15 4:30 2.5 2.5 2.5 2.5 573.36 144.61 166
## Wind.Speed Wind.Origin Date2
## 1 6 SSE 2015-10-10 03:15:00
## 2 7 SSE 2015-10-10 02:00:00
## 3 5 SSE 2015-10-10 04:30:00 Les données de la variable Date2 sont bien dans le format standardisé, présenté précédemment.
Et si on regarde la structure, on peut voir que la variable Date2 est de classe POSIXct, alors que la variable Date est une chaîne de caractères.
str(mydata$Date2)
## POSIXct[1:31642], format: "2015-10-10 03:15:00" "2015-10-10 02:00:00" ...
str(mydata$Date)
## chr [1:31642] "10/10/15 3:15" "10/10/15 2:00" "10/10/15 4:30" ...
Voici d'autres exemples de parsing :
Voici d’autres exemples de parsing :
ymd("20190301")
## [1] "2019-03-01"
ymd("2019/03/01")
## [1] "2019-03-01"
dmy("01/03/2019")
## [1] "2019-03-01"
ymd_hms('2019-03-01 21:15:53')
## [1] "2019-03-01 21:15:53 UTC" Ces fonctions sont décrites dans la cheat sheet du package lubridate, téléchargeable ici.

Et si vous ne trouvez pas votre bonheur dans ces fonctions de parsing, vous pouvez spécifier précisément vos besoins en utilisant la fonction parse_date_time(). Pour plus de détails, consultez la page d’aide :
?parse_date_time Ne conserver que la date
Parfois, on n’est pas du tout intéressé par la partie Heure. Dans ce cas, pour obtenir une variable contenant uniquement la date, j’utilise la fonction date() du package lubridate :
mydata$Date_only <- lubridate::date(mydata$Date2)
head(mydata,3)
## Date Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
## 1 10/10/15 3:15 2.5 2.5 2.5 2.5 2.50 220.61 162
## 2 10/10/15 2:00 2.5 2.5 2.5 2.5 2.50 184.78 158
## 3 10/10/15 4:30 2.5 2.5 2.5 2.5 573.36 144.61 166
## Wind.Speed Wind.Origin Date2 Date_only
## 1 6 SSE 2015-10-10 03:15:00 2015-10-10
## 2 7 SSE 2015-10-10 02:00:00 2015-10-10
## 3 5 SSE 2015-10-10 04:30:00 2015-10-10 Séparer les composants de la date
Dans certaines situations,on peut avoir besoin d’étudier les données en fonction de certains éléments de la date, comme le mois, ou le jour par exemple. Pour cela, il est très utile de pouvoir créer une nouvelle variable « Month » par exemple, qui ne contiendra que le mois de la date considérée. Là encore le package lubridate permet de créer facilement ces variables grâce aux fonctions year(), month(), day(), hour(), minute(), second() etc..
Voici un exemple pour décomposer la variable Date en année, mois, jour, heure et minute :
mydata <- mydata %>%
arrange(Date2) %>%
mutate(Year=year(Date2),
Month=month(Date2),
Day=day(Date2),
Hour=hour(Date2),
Min=minute(Date2)
) Voici ce que ça donne:
mydata[c(285:295),]
## Date Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
## 285 8/1/15 23:40 2.5 2.5 14.85 2.5 2.5 2.5 184
## 286 8/1/15 23:45 2.5 2.5 14.44 2.5 2.5 2.5 191
## 287 8/1/15 23:50 2.5 2.5 16.00 2.5 2.5 2.5 189
## 288 8/1/15 23:55 2.5 2.5 15.15 2.5 2.5 2.5 182
## 289 8/2/15 0:00 2.5 2.5 14.21 2.5 2.5 2.5 171
## 290 8/2/15 0:05 2.5 2.5 15.25 2.5 2.5 2.5 185
## 291 8/2/15 0:10 2.5 2.5 13.70 2.5 2.5 2.5 182
## 292 8/2/15 0:15 2.5 2.5 14.15 2.5 2.5 2.5 167
## 293 8/2/15 0:20 2.5 2.5 14.86 2.5 2.5 2.5 181
## 294 8/2/15 0:25 2.5 2.5 13.59 2.5 2.5 2.5 191
## 295 8/2/15 0:30 2.5 2.5 14.82 2.5 2.5 2.5 186
## Wind.Speed Wind.Origin Date2 Date_only Year Month Day
## 285 6 S 2015-08-01 23:40:00 2015-08-01 2015 8 1
## 286 6 S 2015-08-01 23:45:00 2015-08-01 2015 8 1
## 287 6 S 2015-08-01 23:50:00 2015-08-01 2015 8 1
## 288 7 S 2015-08-01 23:55:00 2015-08-01 2015 8 1
## 289 4 S 2015-08-02 00:00:00 2015-08-02 2015 8 2
## 290 6 S 2015-08-02 00:05:00 2015-08-02 2015 8 2
## 291 6 S 2015-08-02 00:10:00 2015-08-02 2015 8 2
## 292 4 SSE 2015-08-02 00:15:00 2015-08-02 2015 8 2
## 293 6 S 2015-08-02 00:20:00 2015-08-02 2015 8 2
## 294 6 S 2015-08-02 00:25:00 2015-08-02 2015 8 2
## 295 5 S 2015-08-02 00:30:00 2015-08-02 2015 8 2
## Hour Min
## 285 23 40
## 286 23 45
## 287 23 50
## 288 23 55
## 289 0 0
## 290 0 5
## 291 0 10
## 292 0 15
## 293 0 20
## 294 0 25
## 295 0 30 Vous pourrez retrouver la liste complète des fonctions permettant de séparer les composantes d’une date sur la cheat sheet de lubridate .
Arrondir les dates
Le package lubridate propose trois fonctions principales pour arrondir les dates, à l’unité désirée, qui peut être la seconde, la minute, l’heure, le jour, la semaine, le mois, les deux mois, le trimestre, la saison, la demi-année et l’année. Ces fonctions sont:
- floor_date() : pour arrondir à l’unité inférieure,
- ceiling_date(): pour arrondir à l’unité supérieure,
- round_date() : pour arrondir à l’unité la plus proche.
Pour illustrer ces fonctions, je vais les appliquer successivement sur les trois dates suivantes, qui se situent de part et d’autre de 12h, et à 12h, le 1er août 2015, en utilisant une unité d’heure puis de jour.
mydata$Date2[144:146]
## [1] "2015-08-01 11:55:00 UTC" "2015-08-01 12:00:00 UTC"
## [3] "2015-08-01 12:05:00 UTC"
floor_date(mydata$Date2[144:146], unit="hour")
## [1] "2015-08-01 11:00:00 UTC" "2015-08-01 12:00:00 UTC"
## [3] "2015-08-01 12:00:00 UTC"
floor_date(mydata$Date2[144:146], unit="day")
## [1] "2015-08-01 UTC" "2015-08-01 UTC" "2015-08-01 UTC"
ceiling_date(mydata$Date2[144:146], unit="hour")
## [1] "2015-08-01 12:00:00 UTC" "2015-08-01 12:00:00 UTC"
## [3] "2015-08-01 13:00:00 UTC"
ceiling_date(mydata$Date2[144:146], unit="day")
## [1] "2015-08-02 UTC" "2015-08-02 UTC" "2015-08-02 UTC"
round_date(mydata$Date2[144:146], unit="hour")
## [1] "2015-08-01 12:00:00 UTC" "2015-08-01 12:00:00 UTC"
## [3] "2015-08-01 12:00:00 UTC"
round_date(mydata$Date2[144:146], unit="day")
## [1] "2015-08-01 UTC" "2015-08-02 UTC" "2015-08-02 UTC" Manipuler les données de date et d'heure
Par exemple, pour créer un fichier ne comportant que les données se situant au-delà du 17 novembre 2015 :
mydata_last_2days <- mydata %>%
filter(Date_only > ymd("2015-11-17"))
Ou encore pour créer un sous fichier ne contenant que les données du mois de novembre :
mydata_nov <- mydata %>%
filter(Month==11)
head(mydata_nov, 3)
## Date Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
## 1 11/1/15 0:00 2.5 2.5 27.86 2.5 2.5 2.5 230
## 2 11/1/15 0:05 2.5 2.5 27.80 2.5 2.5 2.5 233
## 3 11/1/15 0:10 2.5 2.5 27.41 2.5 2.5 2.5 255
## Wind.Speed Wind.Origin Date2 Date_only Year Month Day
## 1 4 SW 2015-11-01 00:00:00 2015-11-01 2015 11 1
## 2 5 SW 2015-11-01 00:05:00 2015-11-01 2015 11 1
## 3 4 WSW 2015-11-01 00:10:00 2015-11-01 2015 11 1
## Hour Min
## 1 0 0
## 2 0 5
## 3 0 10 Il est également est très facile de calculer des statistiques descriptives en employant notamment les fonctions group_by() et summarise_*() du package dplyr. Ici par exemple, les mesures de pollution et de vent sont moyennées pour chaque jour de chacun de mois :
mydata_avg_day <- mydata %>%
select(Benzene:Wind.Speed, Date2,Date_only,Month, Day) %>%
group_by(Month, Day) %>%
summarise_all(funs(mean(.,na.rm=TRUE)))
head(mydata_avg_day)
## # A tibble: 6 x 12
## # Groups: Month [1]
## Month Day Benzene CS2 Ozone SO2 Toluene Xylene Wind.Direction
##
## 1 8 1 2.5 2.5 17.7 2.5 2.5 2.5 196.
## 2 8 2 2.5 2.5 14.6 2.5 2.5 2.5 190.
## 3 8 3 2.5 2.5 15.3 2.5 2.5 2.5 211.
## 4 8 4 2.5 2.5 15.2 2.5 2.5 2.5 209.
## 5 8 5 2.5 2.5 15.9 2.5 2.5 2.5 165.
## 6 8 6 2.5 2.5 17.4 2.5 2.5 2.5 165.
## # ... with 3 more variables: Wind.Speed , Date2 ,
## # Date_only Autres
Le package lubridate permet également de calculer des durées, des périodes et des intervalles et de gérer les time zones.
Par exemple, on peut calculer que 50 jours séparent le 10 janvier 2019, du premier mars 2019 :
ymd("2019-03-01")-ymd("2019-01-10")
## Time difference of 50 days Pour plus d’information, vous pouvez vous référer à la cheat sheet, ou encore au chapitre 16 du livre R for Data science d’Hadley Wickham.
Visualisation des données temporelles
ggplot(mydata_avg_day, aes(x=Date_only, y=Ozone))+
geom_line()
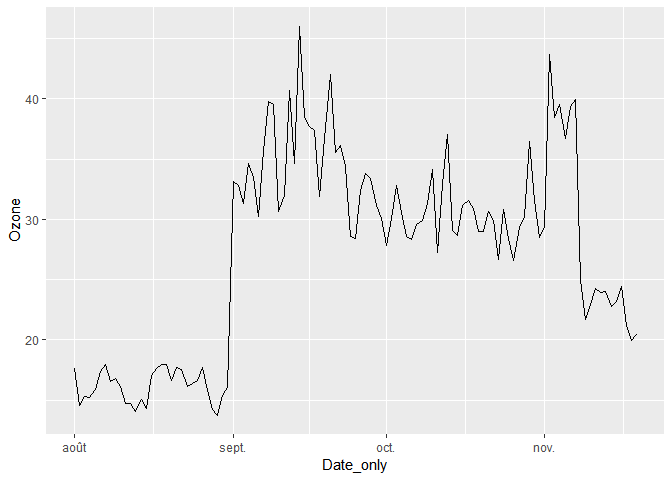
ggplot(mydata_avg_day, aes(x=Date_only, y=Ozone))+
geom_line()+
geom_line(aes(x=Date_only,y=SO2), col="blue") 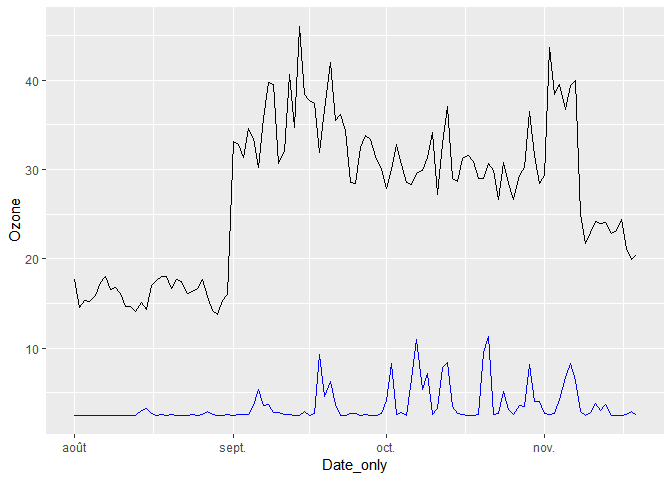
mydata_avg_day_long <- mydata_avg_day %>%
gather(var, value, -Month, -Day, -Date2, -Date_only)
head(mydata_avg_day_long)
## # A tibble: 6 x 6
## # Groups: Month [1]
## Month Day Date2 Date_only var value
##
## 1 8 1 2015-08-01 11:57:30 2015-08-01 Benzene 2.5
## 2 8 2 2015-08-02 11:57:30 2015-08-02 Benzene 2.5
## 3 8 3 2015-08-03 11:57:30 2015-08-03 Benzene 2.5
## 4 8 4 2015-08-04 11:57:30 2015-08-04 Benzene 2.5
## 5 8 5 2015-08-05 11:57:30 2015-08-05 Benzene 2.5
## 6 8 6 2015-08-06 11:57:30 2015-08-06 Benzene 2.5
ggplot(mydata_avg_day_long, aes(y=value, x=Date_only, col=var))+
geom_line()+
facet_wrap(~var, scales="free")+
theme(legend.position="none" 
En utilisant, les fonctions scale_x_datetime() (lorsque les données de temps comportent une date et une heure) et scale_x_date() (lorsque les données ne contiennent qu’une date), il est possible de modifier le format des étiquettes de la variable temps. Ces fonctions nécessitent de charger le package scales.
library(scales)
ggplot(mydata_avg_day_long, aes(y=value, x=Date2, col=var))+
geom_line()+
facet_wrap(~var, scales="free")+
scale_x_datetime(labels=date_format("%b %Y")) +
theme(axis.text.x = element_text(angle=30, hjust=1))+
theme(legend.position="none")
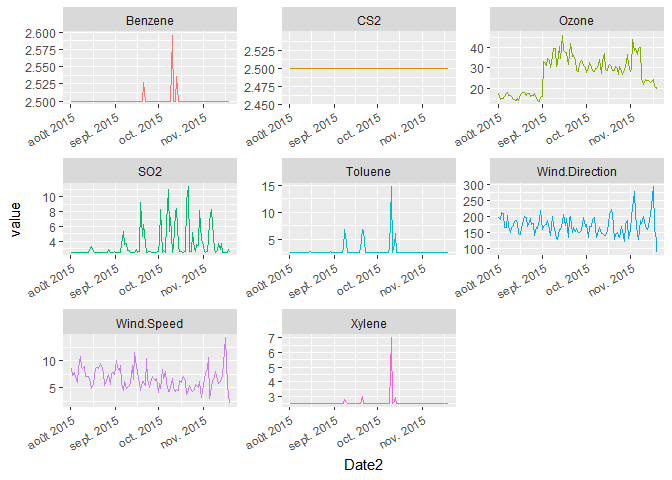
Les options des formats de dates (les lettres %b, %Y, %W etc..) sont décrites dans la page d’aide de la fonction strptime()
?strptime Vous trouverez d’autres exemples, dans le livre R Graphics Cookbook de Winston Chang :

J’espère que cet article permettra aux débutants de mieux comprendre comment fonctionne la gestion des données de date et d’heure sous R, et comment faire les premières manipulations .
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee
Crédit photo : geralt


Très utiles !
Merci.
Bonsoir Claire, Merci encore pour ces infos. Article très très informatif et instructif. J’ai bien aimé.
Bonjour Claire, merci pour cet article très utile qui répond à un problème auquel je suis confrontée!
Bonjour Claire
Je vous souhaite une Meilleure années 2019
Pleine de Santé et
Plein de Succès
Chaque jour je verifie si j’ai quelque chose de nouveau
émanant de vous.
C’est très interessant.
Aziz
Bonjour,
Je viens de lire cet article et j’aimerais faire la commande suivante mais sans avoir à créer un nouveau fichier de données, en sélectionnant la période qui m’intéresse et en lui indiquant la localisation.
mydata_last_2days %
filter(Date_only > ymd(« 2015-11-17 »))
mydata_last_2days$Localization <- c("vol")
Avez-vous la solution svp ?
Merci encore !
Très enrichissant
Merci !
Trop intéressant
Très intéressant pour ce que je cherche à réaliser.
J’ai crée à partir d’une date (année/mois/jour) les données « mois » et « jours ». Mais je ne parviens pas à extraire des intervalles de date, par exemple, les données comprises entre le 01/03 et le 30/04 quelque soit les années.
Merci.
Peut être qu’il faudrait reconstituer une date sans année avec la fonction make_date().
C’est une piste…
Bonne continuation.
Merci pour cet article toujours très clair.
Peut on s’affranchir de l’année dans le format date ? Pourquoi ? J’ai des séries pluri-annuelles de mesures de températures journalières et je veux représenter sur un même graphe les courbes de températures du mois d’avril par exemple, mais de plusieurs années. Donc en abscisse les jours d’avril (donc les dates ?) et en ordonnées les valeurs par jour avec des couleurs différentes par année par exemple.
ça doit être simple mais cela plusieurs jours que je cherche… il faut avouer que je commence seulement à abandonner excel pour R.
Merci et bonne continuation. Au plaisir de vous lire dans de futurs articles.
Je pense qu’il faut extraire les éléments jour, mois et année , et dans ggplot , utiliser ggplot(mydata(aes(x=jour, y=temperature, group=year, col=year).
J’espère que ça vous aide un peu…
Je vous remercie tardivement… mais merci beaucoup pour votre réponse. Effectivement ça fonctionne. Je travaille maintenant pour imposer les couleurs et là je rencontre d’autres soucis.
En tous cas merci encore, vos publication sont toujours intéressantes et je regrette seulement de ne pas trouver le financement pour suivre vos formations ou bénéficier d’un appui ponctuel.
Cordialement.
Bonjour,
Je réalise souvent des graphiques en utilisant des dates. J’ai des problèmes d’affichages lorsque je réalise ce genre de graphique en voulant faire par décade ou mois à cheval sur deux années (ex : de septembre à juin).
Si je conserve le format date pour le mois par exemple, janvier apparait en premier alors qu’il devrait apparaitre après décembre. Les graphiques par décade me posent aussi problème car le package lubridate ne connait pas cette unité de temps.
Si vous avez exploré ce genre de choses, je suis preneuse.
Dans tous les cas, vos articles sont claires et sont très utiles !
Merci
J’ai réussi à trouver une alternative pour l’affichage en utilisant scale_x_discrete et l’argument labels =
Bonjour Véronique,
je pense que la solution est de conserver le format date avec DD-MM-YYYY, de faire le graph et de gérer l’étiquette de la date pour que celle-ci corresponde à voter besoin.
Vous trouverez un exemple dans cet article https://delladata.fr/plot-serie-temporelle/
Bonne continuation.
Claire Della Vedova