Cette semaine, au cours d’une séance de coaching “libre”, on m’a demandé comment faire de multiples tests de wilcoxon de façon automatisés (il y en avait plus de 250 à faire), et comment récupérer la p-value, afin ensuite de faire un sous jeu de données avec seulement les variables qui seraient significatives.
J’ai trouvé cette question vraiment intéressante, parce que c’est vrai que ça peut être super utile de savoir le faire ! Et aussi parce que j’y ai vu une bonne occasion de me (re)pencher sur les fonctions `map()` du packages `purrr` dont je parlais dans cet article celles du package`broom`.
library(ISwR)
head(cystfibr)
## age sex height weight bmp fev1 rv frc tlc pemax
## 1 7 0 109 13.1 68 32 258 183 137 95
## 2 7 1 112 12.9 65 19 449 245 134 85
## 3 8 0 124 14.1 64 22 441 268 147 100
## 4 8 1 125 16.2 67 41 234 146 124 85
## 5 8 0 127 21.5 93 52 202 131 104 95
## 6 9 0 130 17.5 68 44 308 155 118 80 Le test de Wilcoxon est un test non paramétrique (basé sur le calcul d’une somme de rangs) qui permet de comparer les médianes de deux groupes. Avec le jeu de données `cystfibr`, il s’agit, par exemple, de tester si les médianes des pressions expiratoires maximales (variables pemax) sont différents entre les hommes (n=14) et les femmes (n=11).
Le test de wilcoxon se réalise avec la commande suivante :
wilcox.test(pemax~sex, data=cystfibr)
##
## Wilcoxon rank sum test with continuity correction
##
## data: pemax by sex
## W = 100, p-value = 0.2158
## alternative hypothesis: true location shift is not equal to 0 La sortie comporte plusieurs informations :
Il s’agit de réaliser un test de Wilcoxon sur chacune des neuf variables numériques, pour comparer les médianes relatives aux hommes et aux femmes. Autrement dit, il s’agit de réaliser neuf tests de Wilcoxon. Neuf tests de Wilcoxon, ce n’est pas la mer à boire. Mais dans la demande initiale qui m’a été faite il y en avait près de 250 !
L’approche simple consiste à :
library(tidyverse)
library(purrr)
pvalues <- cystfibr%>%
select(-sex) %>%
map(~wilcox.test(.x~sex, data=cystfibr)) %>%
map_dbl("p.value")
pvalues <- round(pvalues,3) # arrondi à 3 chiffres après la virgule Dans un second temps, on récupère le nom des variables numériques :
var <- names(cystfibr)[c(1,3:10)] Puis on peut stoker les nom de ces variables et leur p-value correspondante, dans un data frame :
pval_df <- data_frame(var,pvalues)
pval_df
## # A tibble: 9 x 2
## var pvalues
##
## 1 age 0.441
## 2 height 0.261
## 3 weight 0.344
## 4 bmp 0.493
## 5 fev1 0.009
## 6 rv 0.218
## 7 frc 0.476
## 8 tlc 0.805
## 9 pemax 0.216 pval_df$pval_ajust <- p.adjust(pval_df$pvalues, method="BH")
pval_df
## # A tibble: 9 x 3
## var pvalues pval_ajust
##
## 1 age 0.441 0.555
## 2 height 0.261 0.555
## 3 weight 0.344 0.555
## 4 bmp 0.493 0.555
## 5 fev1 0.009 0.0810
## 6 rv 0.218 0.555
## 7 frc 0.476 0.555
## 8 tlc 0.805 0.805
## 9 pemax 0.216 0.555 cystfibr_long <- cystfibr %>%
gather(var, value, -sex)
head(cystfibr_long)
## sex var value
## 1 0 age 7
## 2 1 age 7
## 3 0 age 8
## 4 1 age 8
## 5 0 age 8
## 6 0 age 9 Dans un deuxième temps, on crée une version “nested” de la version “long”. Il s’agit de découper le jeu de données par paquet de lignes correspondant à chacune des variables, et de stocker les données à proprement parlé, dans une variable appelée “data”. Ça à l’air un peu compliqué, mais on s ’y habitue…
cystfibr_nested <- cystfibr_long%>%
group_by(var) %>%
nest()
head(cystfibr_nested )
## # A tibble: 6 x 2
## var data
##
## 1 age
## 2 height
## 3 weight
## 4 bmp
## 5 fev1
## 6 rv Vous pouvez visualiser les données “nested” dans le viewer:
View(cystfibr_nested) 
En cliquant sur une case blanche de la colonne « data », il est possible de visualiser le jeu de données qu’elle contient :

Ensuite, il s’agit de créer une fonction pour réaliser le test de wilcoxon de manière spécifique avec nos données, c’est à dire en spécifiant le nom des variables, tel qu’elles seront nommées dans le jeu de données (ici « value » et « sexe) :
wilcox_test <- function(df){
wilcox.test(value~sex, data=df)
} Puis de créer une nouvelle variable dans le data.frame “cystfibr_nest” qui contiendra la sortie du test de Wilcoxon créé à l’étape précédente :
cystfibr_nested <- cystfibr_nested %>%
mutate(wilcox_test=map(data,wilcox_test)) On utilise alors la fonction `tidy()` du package `broom` pour formater les sorties des tests de wilcoxon sous forme de data frame. Voici un exemple :
wt <- wilcox.test(pemax~sex, data=cystfibr)
wt
##
## Wilcoxon rank sum test with continuity correction
##
## data: pemax by sex
## W = 100, p-value = 0.2158
## alternative hypothesis: true location shift is not equal to 0
broom::tidy(wt)
##
# A tibble: 1 x 4
## statistic p.value method alternative
##
## 1 100 0.216 Wilcoxon rank sum test with continuity cor~ two.sided Cette fonction `tidy()` est couplée à la fonction `map()` pour être appliquée à toutes les lignes (de cystfibr_nested), et à `mutate()` pour que le data frame issu de la fonction `tidy()` soit inclus dans une nouvelle variable (nommé tidy !) :
cystfibr_nested <- cystfibr_nested %>%
mutate(tidy=map(wilcox_test, broom::tidy)) Voici à quoi ressemble à présent le jeu de données « cystfibr_nested »
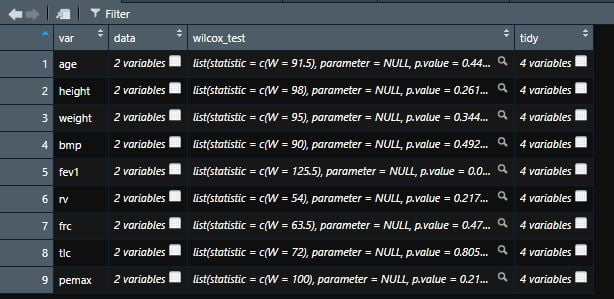
Et ici, le data frame stocké dans la variable tidy :

Il ne reste plus qu’à extraire les variables de ce data frame contenu dans la colonne « tidy » pour les ajouter directement aux colonnes du data frame “cystfibr_nested”. Ceci est possible avec la fonction `unnest()` :
cystfibr_nested <- cystfibr_nested %>%
unnest(tidy, .drop=TRUE) L’argument `.drop=TRUE`, permet de supprimer la variable `tidy`.
cystfibr_nested
## # A tibble: 9 x 5
## var statistic p.value method alternative
##
## 1 age 91.5 0.441 Wilcoxon rank sum test with continu~ two.sided
## 2 height 98 0.261 Wilcoxon rank sum test with continu~ two.sided
## 3 weight 95 0.344 Wilcoxon rank sum test two.sided
## 4 bmp 90 0.493 Wilcoxon rank sum test with continu~ two.sided
## 5 fev1 126. 0.00856 Wilcoxon rank sum test with continu~ two.sided
## 6 rv 54 0.218 Wilcoxon rank sum test with continu~ two.sided
## 7 frc 63.5 0.476 Wilcoxon rank sum test with continu~ two.sided
## 8 tlc 72 0.805 Wilcoxon rank sum test with continu~ two.sided
## 9 pemax 100 0.216 Wilcoxon rank sum test with continu~ two.sided Finalement, en enchaînant les commandes, on obtient :
wilcox_test <- function(df){
wilcox.test(value~sex, data=df)
} wilcox_res <- cystfibr %>%
gather(var, value, -sex) %>%
group_by(var) %>%
nest() %>%
mutate(
wilcox_test=map(data,wilcox_test),
tidy=map(wilcox_test, broom::tidy)) %>%
unnest(tidy,.drop=TRUE) On peut là encore ajuster les p-values :
wilcox_res$pval_ajust <- p.adjust(wilcox_res$p.value, method="BH")
wilcox_res
## # A tibble: 9 x 6
## var statistic p.value method alternative pval_ajust
##
## 1 age 91.5 0.441 Wilcoxon rank sum test w~ two.sided 0.554
## 2 height 98 0.261 Wilcoxon rank sum test w~ two.sided 0.554
## 3 weight 95 0.344 Wilcoxon rank sum test two.sided 0.554
## 4 bmp 90 0.493 Wilcoxon rank sum test w~ two.sided 0.554
## 5 fev1 126. 0.00856 Wilcoxon rank sum test w~ two.sided 0.0770
## 6 rv 54 0.218 Wilcoxon rank sum test w~ two.sided 0.554
## 7 frc 63.5 0.476 Wilcoxon rank sum test w~ two.sided 0.554
## 8 tlc 72 0.805 Wilcoxon rank sum test w~ two.sided 0.805
## 9 pemax 100 0.216 Wilcoxon rank sum test w~ two.sided 0.554 Puis finalement faire un subset du tableau de résultat en ne gardant que les p-values inférieures à un certain seuil, 0.1 par exemple :
wilcox_res_sig <- wilcox_res %>%
select(var, p.value, pval_ajust) %>% # on ne garde que ces 3 var
filter(pval_ajust<0.1)
wilcox_res_sig
## # A tibble: 1 x 3
## var p.value pval_ajust
##
## 1 fev1 0.00856 0.0770 Si l’on souhaite, par exemple, faire toutes les régressions linéaires simples entre la variable « pemax » et chacune des autres variables numériques :
mod_lm <- function(df){
lm(pemax~value, data=df)
}
rls_res <- cystfibr %>%
gather(var, value, -sex,-pemax) %>%
group_by(var) %>%
nest() %>%
mutate(
mod=map(data, mod_lm),
glance=map(mod, broom::glance)) %>%
unnest(glance,.drop=TRUE) %>%
select(var, r.squared, p.value)%>%
select(var,p.value) %>%
mutate(pval_ajust=p.adjust(p.value, method="BH"))
rls_res
## # A tibble: 8 x 3
## var p.value pval_ajust
##
## 1 age 0.00111 0.00413
## 2 height 0.00155 0.00413
## 3 weight 0.000646 0.00413
## 4 bmp 0.270 0.308
## 5 fev1 0.0228 0.0457
## 6 rv 0.124 0.166
## 7 frc 0.0380 0.0608
## 8 tlc 0.385 0.385 J’espère que cet article vous aura convaincu de l’intérêt de savoir utiliser les fonctions `map()` du package `purrr`, mais aussi de l’intérêt de les coupler aux fonctions du package `broom`. Pour aller plus loin, je vous conseille de visionner cet talk d’Hadley Wickham :
Et pour découvrir le package broom, vous pouvez consulter sa vignette, ici
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏

Crédit photos : alan9187

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
3 réponses
Thanks you Claire ! Very helpfull
Bonjour,
J’ai un problème avec la commande suivante :
wilcox.test(pemax~sex, data=cystfibr)
Voilà ce que j’obtiens :
Wilcoxon rank sum test with continuity correction
data: pemax by sex
W = 100, p-value = 0.2158
alternative hypothesis: true location shift is not equal to 0
Warning message:
In wilcox.test.default(x = c(95L, 100L, 95L, 80L, 70L, 110L, 100L, :
impossible de calculer la p-value exacte avec des ex-aequos
et lorsque je charge le package tidyverse :
library(tidyverse)
— Attaching packages ———————————————————— tidyverse 1.3.1 —
v ggplot2 3.3.3 v purrr 0.3.4
v tibble 3.1.1 v dplyr 1.0.6
v tidyr 1.1.3 v stringr 1.4.0
v readr 1.4.0 v forcats 0.5.1
— Conflicts ————————————————————— tidyverse_conflicts() —
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
Warning messages:
1: le package ‘tidyverse’ a été compilé avec la version R 3.6.3
2: le package ‘ggplot2’ a été compilé avec la version R 3.6.3
3: le package ‘tibble’ a été compilé avec la version R 3.6.3
4: le package ‘tidyr’ a été compilé avec la version R 3.6.3
5: le package ‘readr’ a été compilé avec la version R 3.6.3
6: le package ‘purrr’ a été compilé avec la version R 3.6.3
7: le package ‘dplyr’ a été compilé avec la version R 3.6.3
8: le package ‘forcats’ a été compilé avec la version R 3.6.3
Pouvez-vous m’aider ?
Par avance merci.
Bonjour,
Le message sur le test de wilcoxon est seulement un warning vous disant que puisque vos données comportent des ex aequo la p-value est obtenue par une approximation (approximation selon une distribution normale, je pense) alors que sans ex aequo le test emploi une méthode exacte. C’est simplement une information, le test et les résultats restent valides.
Et pour tidyverse, il s’agit aussi d’informations qui vous disent que c’est une vieille version de R qui est employé. Je pense que cela fonctionne, mais je vous recommande de mettre R à jour. Vous trouverez un article sur le blog, si vous faites une recherche par mot clé dans le bandeau de recherche, au-dessus des articles.
Bonne continuation