A la fin d’une analyse de données, on réalise généralement un graph pour synthétiser les résultats obtenus. Par exemple, dans le cadre d’une ANOVA à un facteur (qui sert à comparer plusieurs moyennes), on pourrait vouloir réaliser ce genre de graph :
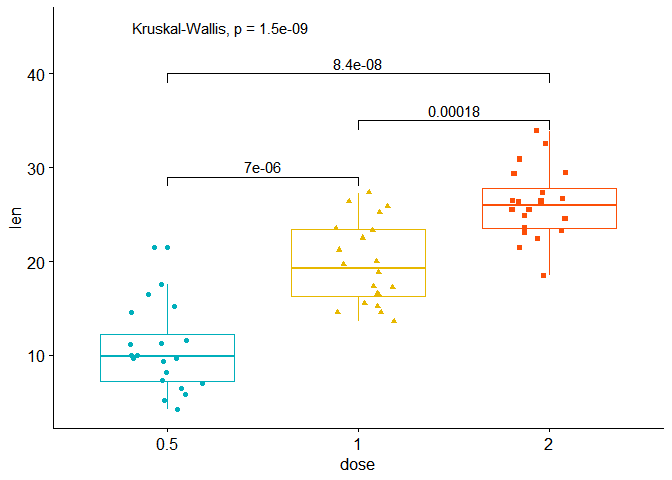
J’ai déjà évoqué, ici et là, plusieurs solutions pour ajouter les pvalues sur un ggplot, ou plus généralement pour ajouter les significativités des comparaisons (en utilisant les p-values, des lettres ou des étoiles), dans un ggplot.
Dans chacune de ces solutions, l’ajout était réalisé de façon plus ou moins automatisée, par l’utilisation d’une fonction.
Mais il existe des situations dans lesquelles ces fonctions ne peuvent pas être employées. C’est le cas, par exemple, lorsqu’on réalise une analyse de type Anova à deux facteurs en employant un GLM (parce que la réponse est de type comptage).
Je vais donc vous montrer comment ajouter les pvalues sur un ggplot, ou plus généralement comment ajouter du texte.
La méthode pour ajouter les pvalues sur un ggplot, ou n’importe quel texte, consiste à utiliser :
Pour vous montrer comment ajouter les pvalues sur un ggplot, de façon manuelle, je vais utiliser les données `warpbreaks` du package `dataset` chargé par défaut.
Ces données concernent le nombre de ruptures de chaîne par métier à tisser en fonction de 2 types de laines (A et B) et 3 niveaux de tension (High / Medium /Low).
data(warpbreaks)
head(warpbreaks)
## breaks wool tension
## 1 26 A L
## 2 30 A L
## 3 54 A L
## 4 25 A L
## 5 70 A L
## 6 52 A L Nous pouvons visualiser les données, en utilisant ce graph :
library(ggplot2)
ggplot(warpbreaks, aes(x=tension, y=breaks, fill=wool, colour=wool))+
geom_point(position=position_jitterdodge(dodge.width=0.7), size=2)+
geom_boxplot(alpha=0.5,outlier.alpha=0)+
xlab("")+
ylab("Number of breaks")+
theme_classic() 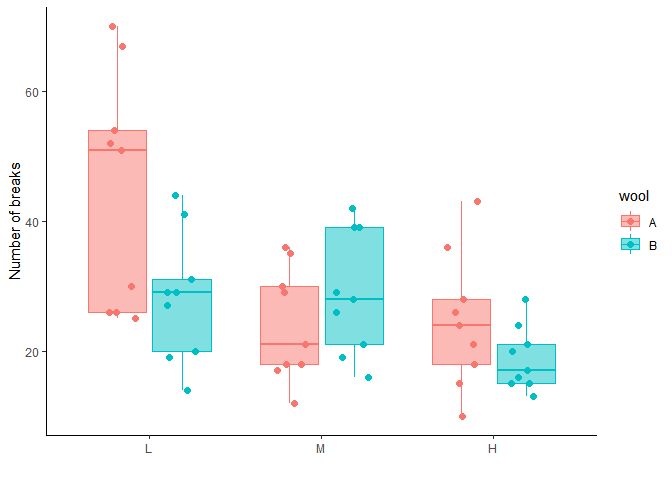
library(tidyverse) # pour le pipe %>%
library(car)# pour la fonction Anova
pval_glm_test <- warpbreaks %>%
split(.$tension) %>%
map(~glm(breaks~wool,family=quasipoisson, data=.)) %>%
map(Anova, test="F") %>%
map("Pr(>F)") %>%
map_dbl(1) pval_glm_test_adj <- p.adjust(pval_glm_test, method="holm")
pval_glm_test_adj
## L M H
## 0.07350979 0.27927729 0.26743404 g1 <- ggplot(warpbreaks, aes(x=tension, y=breaks, fill=wool, colour=wool))+
geom_point(position=position_jitterdodge(dodge.width=0.7), size=2)+
geom_boxplot(alpha=0.5,outlier.alpha=0)+
xlab("")+
ylab("Number of breaks")+
scale_y_continuous(limits=c(0,100))+
theme_classic() Je décide d’indiquer la pvalue dans la partie supérieur du graph, entre les valeurs y=75 et y=100.
Il faut savoir que sur l’axe des x, le niveau L correspond à la valeur 1, le niveau M à la valeur 2, le niveau H à la valeur 3.
Pour réaliser ces traits, on utilise la couche `geom_segment()`
gL1 <- g1 +
geom_segment(x=0.75, xend=1.25, y=80, yend=80, col="black") + # trait horizontal
geom_segment(x=0.75, xend=0.75, y=80, yend=77, col="black") + # petit trait verticla à gauche
geom_segment(x=1.25, xend=1.25, y=80, yend=77, col="black") # petit trait vertical à droite
gL1 
La détermination des valeur x, xend, y, yend, se fait en tâtonnant un peu….
Pour ajouter du texte sur le ggplot, on utilise la fonction annotate
gL2 <- gL1 +
annotate("text", x = 1, y = 85, label = "p = 0.074")
gL2 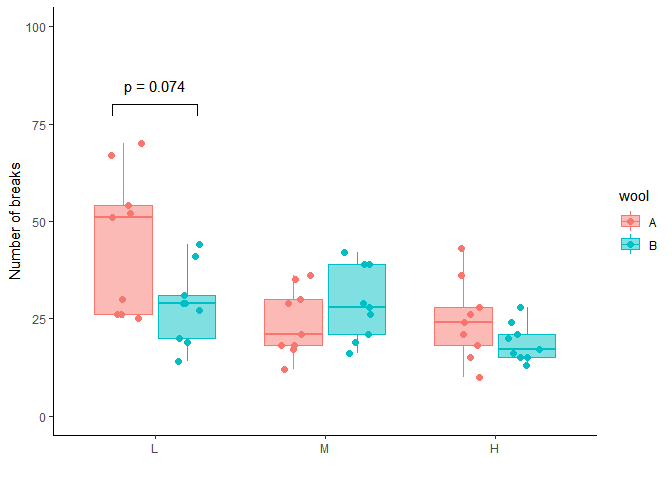
Il suffit alors de faire la même chose pour l’ensemble des niveaux
gfinal <- g1 +
##### Niveau Low
geom_segment(x=0.75, xend=1.25, y=80, yend=80, col="black") + # trait horizontal
geom_segment(x=0.75, xend=0.75, y=80, yend=77, col="black") + # petit trait verticla à gauche
geom_segment(x=1.25, xend=1.25, y=80, yend=77, col="black")+ # petit trait vertical à droite
annotate("text", x = 1, y = 85, label = "p = 0.074")+
##### Niveau Medium
geom_segment(x=1.75, xend=2.25, y=80, yend=80, col="black") + # trait horizontal
geom_segment(x=1.75, xend=1.75, y=80, yend=77, col="black") + # petit trait verticla à gauche
geom_segment(x=2.25, xend=2.25, y=80, yend=77, col="black")+ # petit trait vertical à droite
annotate("text", x = 2, y = 85, label = "p = 0.28")+
##### Niveau High
geom_segment(x=2.75, xend=3.25, y=80, yend=80, col="black") + # trait horizontal
geom_segment(x=2.75, xend=2.75, y=80, yend=77, col="black") + # petit trait verticla à gauche
geom_segment(x=3.25, xend=3.25, y=80, yend=77, col="black")+ # petit trait vertical à droite
annotate("text", x = 3, y = 85, label = "p = 0.27") 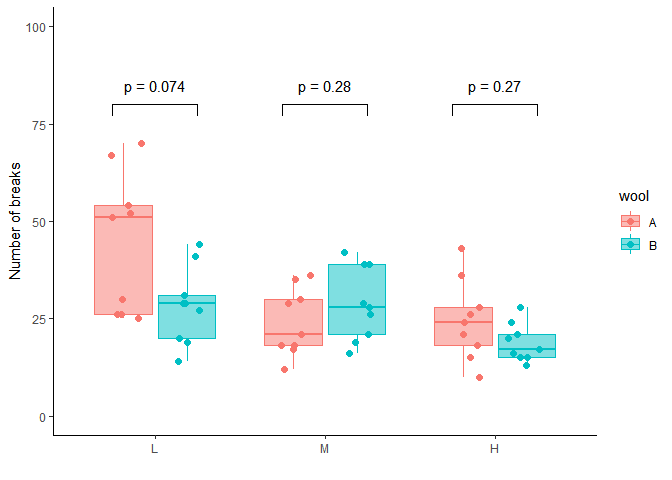


Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
3 réponses
Merci beaucoup Claire pour les infos et astuces que tu partages… C’est top ! ^_^
Merci beaucoup!! Et si l’on voulait tracé un trait pour relier 2 ou 3 facets afin d’y ajouter un texte. Comment on fait??
Bonjour,
peut être une piste ici : http://rstudio-pubs-static.s3.amazonaws.com/410976_f8eb6b218bfa42038a8b7bc9a6f9a193.html
Bonne continuation