La semaine dernière, j’ai reçu un commentaire d’un lecteur qui me disait :
» Bonjour, Bravo pour la qualité de l’information. Je souhaiterais faire exactement la même méthode que dans la partie 10 (représentation finale de la régression) [de l’article La régression linéaire simple avec le logiciel R] pour mettre sur un même graphique les points, le modèle, intervalle de confiance et intervalle de prédiction. Pour des raisons expérimentales il faut que ma régression passe par 0. Habituellement sur R, il faut utiliser le script ” Y ~ -1+X” pour obtenir la pente de l’équation Y=aX sans ordonnée à l’origine.
Je n’arrive pas avec le package ggplot2 à faire passer ma régression par 0. Lorsque je programme geom_smooth(method=”lm”, formula=y~-1+x), j’obtiens un intervalle de confiance qui me semble faux
Avez-vous une solution ?
Merci par avance «
Je me suis dit que c’était une bonne occasion de refaire un point sur la représentation graphique de l’intervalle de confiance et de prédiction. Et aussi de parler de ces modèles de régression linéaire simple dont l’intercept (ordonnée à l’origine) est forcée à être égale à 0.
Je me suis dit que c’était une bonne occasion de refaire un point sur la représentation graphique de l’intervalle de confiance et de prédiction. Et aussi de parler de ces modèles de régression linéaire simple dont l’intercept (ordonnée à l’origine) est forcée à être égale à 0.
L’intervalle de confiance à 95% d’une droite de régression est obtenu à partir d’un échantillon, il correspond à une plage de valeurs ayant une probabilité de 95% de contenir la droite de régression de la population.
Vous trouverez plus d’information sur les intervalles de confiance, dans l’article Fluctuations d’échantillonnage et biais.
L’intervalle de prédiction à 95% , quant à lui, est une plage de valeur qui a une a une probabilité de 95% de contenir une observation nouvelle.
Le modèle de régression linéaire simple est une droite qui passe au mieux des points. Il comporte deux paramètres :
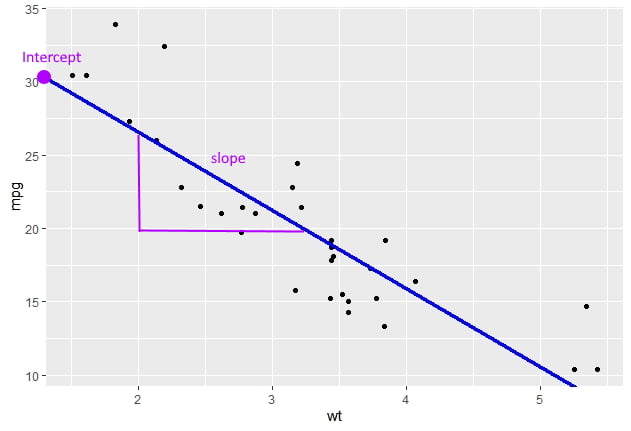
Nous allons utiliser les données du jeu de données iris (inclu dans le package dataset chargé par défaut dans R ), mais en les limitant aux 50 observations de l’espèce setosa :
library(tidyverse)
# création du sous fichier setosa
setosa <- iris %>%
filter(Species=="setosa") Nous allons ajuster un modèle de régression linéaire en considérant que la variable réponse est la variable Sepal. Width, que la variable explicative est la variable Sepal.Length, et que l’intercept de ce modèle est égale à 0.
Comme expliqué dans le commentaire, pour forcer un modèle de régression à avoir un intercept égal à 0, autrement dit pour que la droite passe par le point (0;0), nous devons utiliser la syntaxe lm(Sepal.Width~Sepal.Length-1, data=setosa) :
summary(mod1)
##
## Call:
## lm(formula = Sepal.Width ~ Sepal.Length - 1, data = setosa)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.78398 -0.18311 -0.00811 0.18176 0.53629
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## Sepal.Length 0.685328 0.007244 94.61 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.257 on 49 degrees of freedom
## Multiple R-squared: 0.9946, Adjusted R-squared: 0.9944
## F-statistic: 8952 on 1 and 49 DF, p-value: < 2.2e-16 Nous pouvons, dans un premier temps, représenter la droite de régression du modèle ajusté et son intervalle de confiance, à l’aide de la couche geom_smooth(), en spécifiant en argument :
library(ggplot2)
ggplot(setosa, aes(y=Sepal.Width, x=Sepal.Length)) +
geom_point(colour="grey40") +
stat_smooth(method = "lm", formula=y~x-1, fill="red", colour="red") +
scale_y_continuous(lim=c(0,4.5)) +
scale_x_continuous(lim=c(0,7)) 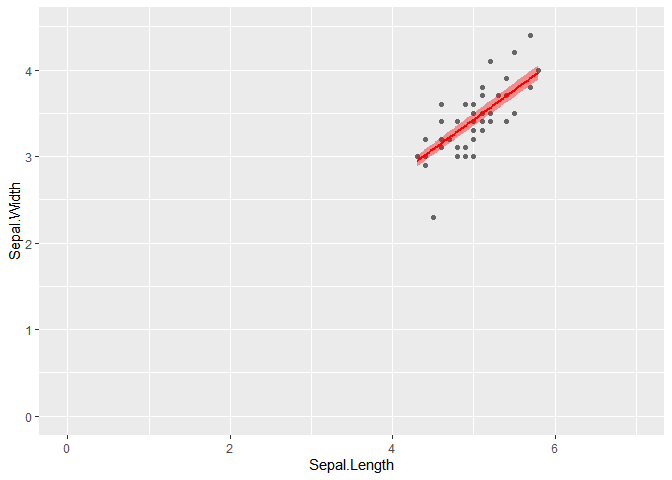
Nous créons un vecteur de 1000 valeurs de Sepal Length en prenant pour bornes les min et max observées, et nous le plaçons dans un data frame (nommé predicted):
xmin <- min(setosa$Sepal.Length)
xmax <- max(setosa$Sepal.Length)
predicted <- data.frame(Sepal.Length = seq(xmin, xmax, length.out = 1000))
head(predicted)
## Sepal.Length
## 1 4.300000
## 2 4.301502
## 3 4.303003
## 4 4.304505
## 5 4.306006
## 6 4.307508 Dans un second temps, nous ajoutons la variable `Sepal.Width` qui correspond à la valeur de `Sepal Length`, prédite par le modèle de régression ajusté précédemment, pour la valeur de `Sepal.Length` correspondante dans le tableau.
Cette valeur est obtenue à l’aide de la fonction predict()
predicted$Sepal.Width <- predict(mod1,predicted)
head(predicted)
## Sepal.Length Sepal.Width
## 1 4.300000 2.946912
## 2 4.301502 2.947941
## 3 4.303003 2.948970
## 4 4.304505 2.949999
## 5 4.306006 2.951028
## 6 4.307508 2.952057 Puis nous allons, toujours à l’aide de la fonction predict(), obtenir les bornes inf et sup de l’intervalle de confiance de chaque réponse de Sepal.Width prédite, en utilisant l’argument interval="confidence" :
predicted$ci_binf <- predict(mod1,predicted, interval="confidence",level = 0.95)[,2]
predicted$ci_bsup <- predict(mod1,predicted, interval="confidence",level = 0.95)[,3]
head(predicted)
## Sepal.Length Sepal.Width ci_binf ci_bsup
## 1 4.300000 2.946912 2.884319 3.009504
## 2 4.301502 2.947941 2.885326 3.010555
## 3 4.303003 2.948970 2.886333 3.011606
## 4 4.304505 2.949999 2.887341 3.012657
## 5 4.306006 2.951028 2.888348 3.013708
## 6 4.307508 2.952057 2.889355 3.014759 Puis nous faisons de même avec l’intervalle de prédiction :
predicted$pi_binf <- predict(mod1,predicted, interval="prediction",level = 0.95)[,2]
predicted$pi_bsup <- predict(mod1,predicted, interval="prediction",level = 0.95)[,3]
head(predicted)
## Sepal.Length Sepal.Width ci_binf ci_bsup pi_binf pi_bsup
## 1 4.300000 2.946912 2.884319 3.009504 2.426619 3.467205
## 2 4.301502 2.947941 2.885326 3.010555 2.427645 3.468236
## 3 4.303003 2.948970 2.886333 3.011606 2.428672 3.469268
## 4 4.304505 2.949999 2.887341 3.012657 2.429698 3.470300
## 5 4.306006 2.951028 2.888348 3.013708 2.430724 3.471331
## 6 4.307508 2.952057 2.889355 3.014759 2.431751 3.472363 Enfin, nous pouvons réaliser le graphique :
ggplot(setosa, aes(y=Sepal.Width, x=Sepal.Length))+
# ajout des points
geom_point(colour="grey40")+
# ajout de la droite de régression
geom_line(data=predicted, aes(y=Sepal.Width, x=Sepal.Length), col="red")+
scale_y_continuous(lim=c(0,4.5))+
scale_x_continuous(lim=c(0,7))+
# ajout de la binf de l'intervalle de confiance
geom_line(data=predicted, aes(y=ci_binf, x=Sepal.Length), col="red", linetype="dashed")+
# ajout de la bsup de l'intervalle de confiance
geom_line(data=predicted, aes(y=ci_bsup, x=Sepal.Length), col="red", linetype="dashed")+
# ajout de la binf de l'intervalle de prédiction
geom_line(data=predicted, aes(y=pi_binf, x=Sepal.Length), col="blue", linetype="dashed")+
# ajout de la bsup de l'intervalle de prédiction
geom_line(data=predicted, aes(y=pi_bsup, x=Sepal.Length), col="blue", linetype="dashed") 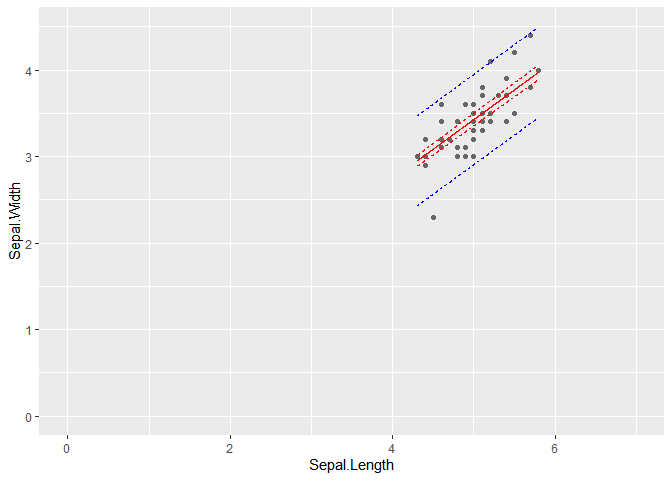
L’intervalle de confiance me semble identique à celui obtenu avec la fonction geom_smooth().
Nous pouvons également poursuivre la droite pour vérifier que son intercept est bien égale à 0.
ggplot(setosa, aes(y=Sepal.Width, x=Sepal.Length))+
geom_point(colour="grey40")+ geom_line(data=predicted, aes(y=Sepal.Width, x=Sepal.Length), col="red")+
scale_y_continuous(lim=c(0,4.5))+
scale_x_continuous(lim=c(0,7))+
geom_line(data=predicted, aes(y=ci_binf, x=Sepal.Length), col="red", linetype="dashed")+
geom_line(data=predicted, aes(y=ci_bsup, x=Sepal.Length), col="red", linetype="dashed")+
geom_line(data=predicted, aes(y=pi_binf, x=Sepal.Length), col="blue", linetype="dashed")+
geom_line(data=predicted, aes(y=pi_bsup, x=Sepal.Length), col="blue", linetype="dashed")+
# prolongement de la droite de régression
geom_abline(slope=coef(mod1)) 
Cette approche pour représenter des modèles de régression et leur intervalle de confiance et de prédiction n’est pas spécifique au modèle de régression linéaire simple.
J’espère avoir un peu aidé le lecteur qui a posté ce commentaire….
Si cet article vous a plu, ou vous a été utile, et si vous le souhaitez, vous pouvez soutenir ce blog en faisant un don sur sa page Tipeee 🙏
Image par Gerd Altmann de Pixabay

Enregistrez vous pour recevoir gratuitement mes fiches « aide mémoire » (ou cheat sheets) qui vous permettront de réaliser facilement les principales analyses biostatistiques avec le logiciel R et pour être informés des mises à jour du site.
8 réponses
Bonjour Claire, travaillant sur des données hospitalières, je rejoins la cohorte des fans de votre blog avec une remarque sur cette page : au §3, la copie d’écran montrant le résultat de summary(mod1) ne correspond pas à mod1.
Bonne continuation et merci encore pour ces notes précises à l’approche intuitive.
Bonjour Bernard,
merci pour votre message et remarque, je viens de modifier !
Bonne continuation.
thanks so much. I’m post graduate in biostatistic . That’s very usefull for me
Thanks for your message !
All the best.
Bonjour,
je vous remercie pour votre article qui m’a été utile!
Cependant, j’ai encore une question: j’ai une base de données de 400 variables, j’ai réalisé une droite de régression entre deux des variables proposées. Par la suite, je cherche à connaitre les coefficients de ma droite de régression (a et b). cependant, je veux avoir les valeurs de a et b ainsi que les intervalles de confiance de a et b à 95%.
Comment peut-on faire?
Je vous remercie
Bonjour,
voici comment faire :
> fit <- lm(Sepal.Width~Sepal.Length, data=iris) > summary(fit)Call:lm(formula = Sepal.Width ~ Sepal.Length, data = iris)
Residuals:
Min 1Q Median 3Q Max
-1.1095 -0.2454 -0.0167 0.2763 1.3338
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.41895 0.25356 13.48 <2e-16 ***
Sepal.Length -0.06188 0.04297 -1.44 0.152
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4343 on 148 degrees of freedom
Multiple R-squared: 0.01382, Adjusted R-squared: 0.007159
F-statistic: 2.074 on 1 and 148 DF, p-value: 0.1519
> confint(fit)2.5 % 97.5 %
(Intercept) 2.9178767 3.92001694
Sepal.Length -0.1467928 0.02302323
Pour que les intervalles de confiance soient valide, les résidus doivent suivent une distribution normale et être homogènes.
Bonsoir Claire,
Je suis à la recherche de la construction théorique de l’intervalle de confiance de la droite de regression
C’est un encadrement des coefficients estimés ou bien.
Et si oui, j’aimerais bien savoir comment
Merci
Bonjour,
Vous trouverez cela dans quasiment tous les livres de stats théoriques, et en faisant une petite recherche sur google, par exemple https://ncss-wpengine.netdna-ssl.com/wp-content/themes/ncss/pdf/Procedures/PASS/Confidence_Intervals_for_Linear_Regression_Slope.pdf.
Bonne continuation